带有 <p> 标签的网页抓取拦截器
背景:
我最终试图通过网络抓取食谱网站并收集关键信息公司。食谱 - 名称、配料、准备说明、烹饪时间、准备时间。
我把这个项目分成小块。到目前为止,我有代码可以从食谱的网页上抓取配料。
我需要帮助的地方:
我正在尝试改进我编写的一些代码(它目前会抓取食谱成分),以便它也抓取食谱步骤(或网站称之为“方法”)代码输入(1) -
对于刮成分(这很好用!):
from scraper_api import ScraperAPIClient
from splinter import Browser
from webdriver_manager.chrome import ChromeDriverManager
executable_path = {'executable_path': ChromeDriverManager().install()}
browser = Browser('chrome', **executable_path)
resp = requests.get("https://www.simplyrecipes.com/recipes/cooking_for_two_strawberry_almond_oat_smoothie/")
soup = BeautifulSoup(resp.text, "html.parser")
div_ = soup.find("div", attrs={"class": "recipe-callout"})
recipes = {"_".join(div_.find("h2").text.split()):
[x.text for x in div_.findAll("li", attrs={"class": "ingredient"})]}
代码输出 (1)
{'Strawberry_Almond_Oat_Smoothie_Recipe': ['1/2 cup uncooked old-fashioned rolled oats',
'2 cups frozen strawberries',
'1 cup plain yogurt (regular or Greek, any fat percentage)',
'1 cup unsweetened vanilla almond milk (or milk of your choice)',
'1/2 medium banana, fresh or frozen, sliced',
'1/4 teaspoon pure almond extract',
'1-2 teaspoons honey (optional)']}
我的研究:
查看了同一食谱网站的 HTML 代码后,我确定了我需要关注的 HTML -看起来我需要定位:
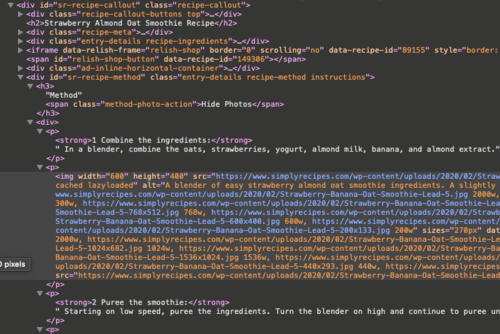
<div>与id="sr-recipe-callout"和class="recipe-callout"。<p>具有<strong>元素的标签 - 令人讨厌的是,<p>有些标签没有<strong>,而那些标签不包含配方方法并且没有用。
我需要帮助的地方:
我不知道如何改进这段代码,特别是我如何确定我只想提取<p>具有<strong>元素的代码。
我知道这是很多信息,但希望它是有意义的,并且有人可以指导我改进/回收我当前的代码,以适应方法的 HTML 的细微差别,它是用于成分的。
 SMILET
SMILET1回答
-

幕布斯6054654
from bs4 import BeautifulSoupsoup = BeautifulSoup(resp, "html.parser")div = soup.find("div", attrs={"id": "sr-recipe-method"})# select all <p> tag's inside the <div>for p in div.findAll("p"): # check if <strong> exist's inside <p> tag if p.find('strong'): print(p.text)1 Combine the ingredients: In a blender, combine the oats, strawberries, yogurt, almond milk, banana, and almond extract.2 Puree the smoothie: Starting on low speed, puree the ingredients. Turn the blender on high and continue to puree until smooth. Serve right away.

相关分类
 Python
Python