使用美丽汤和蟒蛇解析<li>元素的列表,这些元素在行(单元格)内组织成两列
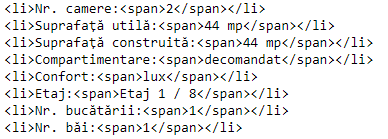
<div id="b_detalii_caracteristici" class="margin-boxes"> <h2 class="titlu-box special-caracteristici">Caracteristici</h2> <div class="row"> <div class="col-lg-6 col-md-6 col-sm-6"> <ul class="lista-tabelara"> <li>Nr. camere:<span>2</span></li> <li>Suprafaţă utilă:<span>44 mp</span></li> <li>Suprafaţă construită:<span>44 mp</span></li> <li>Compartimentare:<span>decomandat</span></li> <li>Confort:<span>lux</span></li> <li>Etaj:<span>Etaj 1 / 8</span></li> <li>Nr. bucătării:<span>1</span></li> <li>Nr. băi:<span>1</span></li> </ul> </div> <div class="col-lg-6 col-md-6 col-sm-6"> <ul class="lista-tabelara mobile-list"> <li>An construcţie:<span>2019</span></li> <li>Structură rezistenţă:<span>beton</span></li> <li>Tip imobil:<span>bloc de apartamente</span></li> <li>Regim înălţime:<span>P+8E</span></li> <li>Nr. balcoane:<span>1</span></li> </ul> </div> </div></div>
给定上述结构:我需要找到一种方法来解析它并存储在单独的变量中,每个li值:即
if string = "Nr. camere:":
var1 = 2
elsif string = "Suprafata utila:":
var2 = 44mp
等等...
我试过:
property_detail.find_all('div', id="b_detalii_caracteristici")[0].find_all('ul', class_='lista-tabelara')[0].find_all("li")[0]
并且,这将为我提供下一个结果,我需要在for循环中解析:
但是,我被困在这里。感谢您的支持。
 繁星淼淼
繁星淼淼1回答
-

富国沪深
对于调用的内容,有一个非常有用的方法,它返回一个包含标记的子级的列表:from bs4 import BeautifulSoup html = '''<div id='b_detalii_caracteristici'> <ul class="lista-tabelara"> <li> "Nr. camere:" <span>2</span> </li> <li> "Suprafata utila:" <span>44mp</span> </li> </ul></div>'''soup = BeautifulSoup(html, 'html.parser') lis = soup.select('#b_detalii_caracteristici ul.lista-tabelara li')for li in lis: li_content = li.contents li_text = li_content[0].strip() span_text = li_content[1].text print('li_content ==> ',li_content) print('li_text ==> ',li_text) print('span_text ==>',span_text)输出:li_content ==> ['\n "Nr. camere:"\n ', <span>2</span>, '\n']li_text ==> "Nr. camere:"span_text ==> 2li_content ==> ['\n "Suprafata utila:"\n ', <span>44mp</span>, '\n']li_text ==> "Suprafata utila:"span_text ==> 44mp

相关分类
 Python
Python