从pandas DataFrame python中提取文件路径
我有一个 Excel 文件,其中包含列中文件夹的文件路径。可能有多个文件路径存储在一行中。我可以像这样将excel文件读入熊猫。
现在我要做的是DataFrame df逐行遍历我的 pandas 并提取存储的目录,以便我可以将它们用作其他功能的输入目录。
如果我使用 iloc 访问数据框中的行,我会得到一个str类似的对象,而我想要的是拥有该类型的每一行,list这样我就可以遍历它。
我的数据框中变量格式的示例。
import pandas as pd
path_1 = '[\'C:\\\\tmp_patients\\\\Pat_MAV_BE_B01_\']'
path_2 = '[\'C:\\\\tmp_patients\\\\Pat_MAV_B16\', \'C:\\\\tmp_patients\\\\Pat_MAV_BE_B16_2017-06-30_08-49-28\']'
d = {'col1': [path_1, path_2]}
df = pd.DataFrame(data=d)
#or read directly excel
# df= pd.read_excel(filepath_to_excel)
for idx in range(len(df)):
paths = df['col1'].iloc[idx]
for a_single_path in paths:
print(a_single_path)
# todo: process all the files found at the location "a single path" with os.walk
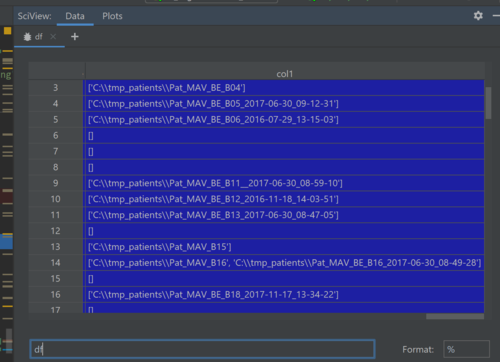
读取文件后数据的外观pd.read_excel()
 BIG阳
BIG阳2回答
-

慕村9548890
如果您想要单个目录的行:数据:注意正在使用的列名是file_path_lists,但问题截图中的列名是col1from pathlib import Pathfrom ast import literal_evaldf = pd.read_excel('test.xlsx')将行 from和each转换str为单独的行:listexplodelistdf.file_path_lists = df.file_path_lists.apply(literal_eval)df2 = pd.DataFrame(df.explode('file_path_lists'))df2.dropna(inplace=True)print(df2.file_path_lists[0])>>> 'C:\\tmp_patients\\Pat_MAV_BE_B01_'注意路径仍然是str转换为pathlib对象:pathlib标准库的一部分,应该使用而不是os. Python 3 的 pathlib 模块:驯服文件系统df2.file_path_lists = df2.file_path_lists.apply(Path)print(df2.file_path_lists[0])>>> WindowsPath('C:/tmp_patients/Pat_MAV_BE_B01_')现在每个都是一个pathlib对象。访问每个目录:for dir in df2.file_path_lists: print(dir) print(type(dir))>>> C:\tmp_patients\Pat_MAV_BE_B01_ <class 'pathlib.WindowsPath'> C:\tmp_patients\Pat_MAV_B16 <class 'pathlib.WindowsPath'> C:\tmp_patients\Pat_MAV_BE_B16_2017-06-30_08-49-28 <class 'pathlib.WindowsPath'>打印在患者目录中找到的文件列表:for dir in df2.file_path_lists: patient_files = list(dir.glob('*.*')) # use .rglob if there are subdirs print(patient_files)如果您想要行lists而不是每个目录的行:跳过.explodedf = pd.read_excel('test.xlsx')df.file_path_lists = df.file_path_lists.apply(literal_eval)print(type(df.file_path_lists[0]))>>> listfor row in df.file_path_lists: # iterate the row for x in row: # iterate the list inside the row print(x)>>> C:\tmp_patients\Pat_MAV_BE_B01_ C:\tmp_patients\Pat_MAV_B16 C:\tmp_patients\Pat_MAV_BE_B16_2017-06-30_08-49-28 -

慕码人8056858
您的示例输入具有看起来像数组的字符串。我认为read_excel不会那样做,所以你不需要.apply(literal_eval)下面的电话。假设您使用的是 pandas 0.25 或更高版本,因此您可以使用explode:from ast import literal_evalpath_1 = "['C:\\\\develop\\\\python-util-script\\\\Pat_MAV_B01']"path_2 = "['C:\\\\develop\\\\python-util-script\\\\Pat_MAV_B16', 'C:\\\\develop\\\\python-util-script\\\\Pat_MAV_BE_B16_2017-06-30_08-49-28']"d = {'col1': [path_1, path_2]}df = pd.DataFrame(data=d)df['col1'].apply(literal_eval).explode()输出:0 C:\develop\python-util-script\Pat_MAV_B011 C:\develop\python-util-script\Pat_MAV_B161 C:\develop\python-util-script\Pat_MAV_BE_B16_2...Name: col1, dtype: object


相关分类
 Python
Python