如何从数据帧生成频率表?
我有一个 df 原始调查数据类似于以下 12000 行和 40 个问题。所有回答都是分类的
import pandas as pd
df = pd.DataFrame({'Age' : ['20-30','20-30','30-45', '20-30','30-45','20-30'],
'Gender' : ['M', 'F', 'F','F','M','F'],
'Income' : ['20-30k', '30-40k', '40k+', '40k+', '40k+', '20-30k'],
'Question1' : ['Good','Bad','OK','OK','Bad','Bad'],
'Question2' : ['Happy','Unhappy','Very_Unhappy','Very_Unhappy','Very_Unhappy','Happy']})
我想根据年龄、性别和收入对每个问题的回答进行分类,为每个问题生成一个频率(按百分比)表
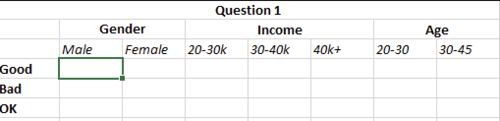
交叉表产生了太多类别,即它按收入和收入、年龄等细分。所以我不确定如何最好地解决这个问题。我确定这是一个简单的问题,但我是 python 的新手,希望得到任何帮助
 FFIVE
FFIVE浏览 145回答 2
2回答
-

SMILET
正如您所说,对所有列使用交叉表会按每列分解结果。您可以使用单独的交叉表,然后连接pd.concat([pd.crosstab(df.Question1, df.Gender), pd.crosstab(df.Question1, df.Income), pd.crosstab(df.Question1, df.Age)], axis = 1) F M 20-30k 30-40k 40k+ 20-30 30-45Question1 Bad 2 1 1 1 1 2 1Good 0 1 1 0 0 1 0OK 2 0 0 0 2 1 1编辑:在列中获得额外级别age = pd.crosstab(df.Question1, df.Age)age.columns = pd.MultiIndex.from_product([['Age'], age.columns])gender = pd.crosstab(df.Question1, df.Gender)gender.columns = pd.MultiIndex.from_product([['Gender'], gender.columns])income = pd.crosstab(df.Question1, df.Income)income.columns = pd.MultiIndex.from_product([['Income'], income.columns])pd.concat([age, gender, income], axis = 1) Age Gender Income 20-30 30-45 F M 20-30k 30-40k 40k+Question1 Bad 2 1 2 1 1 1 1Good 1 0 0 1 1 0 0OK 1 1 2 0 0 0 2

相关分类
 Python
Python