Keras - 从顺序 API 到函数式 API 的转换
我一直在关注 Towards Data Science 关于 word2vec 和 skip-gram 模型的教程,但我偶然发现了一个我无法解决的问题,尽管搜索了很多并尝试了多个不成功的解决方案。
由于使用了 keras.layers 中的 Merge 层,它向您展示了如何构建 skip-gram 模型架构的步骤似乎已被弃用。
我试图做的是将他的一段代码(在 Keras 的 Sequential API 中实现)转换为 Functional API,以通过将其替换为 keras.layers.Dot 层来解决 Merge 层的弃用问题。但是,我仍然停留在将两个模型(词和上下文)合并到最终模型中的这一步,其架构必须是这样的:
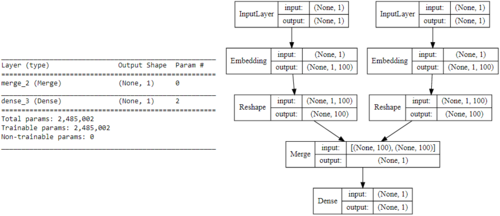
这是作者使用的代码:
from keras.layers import Merge
from keras.layers.core import Dense, Reshape
from keras.layers.embeddings import Embedding
from keras.models import Sequential
# build skip-gram architecture
word_model = Sequential()
word_model.add(Embedding(vocab_size, embed_size,
embeddings_initializer="glorot_uniform",
input_length=1))
word_model.add(Reshape((embed_size, )))
context_model = Sequential()
context_model.add(Embedding(vocab_size, embed_size,
embeddings_initializer="glorot_uniform",
input_length=1))
context_model.add(Reshape((embed_size,)))
model = Sequential()
model.add(Merge([word_model, context_model], mode="dot"))
model.add(Dense(1, kernel_initializer="glorot_uniform", activation="sigmoid"))
model.compile(loss="mean_squared_error", optimizer="rmsprop")
 慕勒3428872
慕勒34288721回答
-

holdtom
您正在将Model实例传递给图层,但是由于错误表明您需要将 Keras 张量(即图层或模型的输出)传递给 Keras 中的图层。你在这里有两个选择。一种是像这样使用实例的.output属性Model:dot_output = layers.dot([word_model.output, context_model.output], axes=1, normalize=False)或者等效地,您可以直接使用输出张量:dot_output = layers.dot([word_reshape, context_reshape], axes=1, normalize=False)此外,您需要应用Dense层,然后将层的dot_output实例Input作为 的输入传递Model。所以:model_output = layers.Dense(1, kernel_initializer='glorot_uniform', activation='sigmoid')(dot_output)model = Model([word_input, context_input], model_output)

相关分类
 Python
Python