在 python pandas 中使用时间帧将数据拆分成组
我有一个名为 df 的数据框,它像这样,但实际上是 [9147 行 x 3 列]
indexID RngUni[m] PowUni[dB]
157203 1.292283 132
157201 1.271878 132
157016 1.285481 134
157404 1.305886 136
157500 1.353496 136
157524 1.251474 136
157227 1.292283 132
157543 1.339893 136
157903 1.353496 138
156928 1.299084 134
157373 1.299084 136
156937 1.414709 134
157461 1.353496 136
157718 1.360297 138
157815 1.326290 138
157806 1.271878 134
156899 1.360298 134
157486 1.414709 138
157628 1.271878 136
157405 1.299084 134
157244 1.299084 134
157522 1.258275 136
157515 1.367099 138
157086 1.305886 136
157602 1.251474 134
157131 1.265077 132
157170 1.380702 138
156904 1.360297 134
157209 1.401106 138
157018 1.265077 134
我想要做的是选择表中数据的某些值。
df.plot(x = 'RngUni[m]', y = 'PowUni[dB]', kind = 'scatter') 给出:
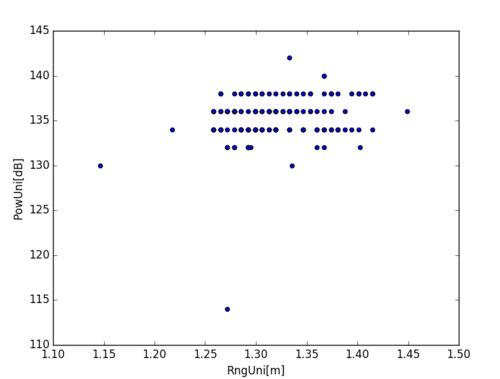
假设主组是大部分数据点聚集的区域,我需要做的是选取80%在主组内的点和20%在主组外的点。
我需要以列表形式输出的所有点的 indexID。我怎样才能做到这一点?
所需的聚类示例。我想做的是选取圈内 80% 的点和圈外点的 20%。

 温温酱
温温酱1回答
相关分类
 Python
Python