问问大神,scrapy代码为啥爬出来的数据重复了呢?
我的结果示例如下,“元谷”重复了5次,其他的也重复了4次(而且我爬的时候后面还出现了429禁止我爬取)。补:后来再试试发现不管多层爬取的事,把loupan_detail_parse去掉也出现重复,而且loupan_item不能print出来

控制台上显示重复了两次
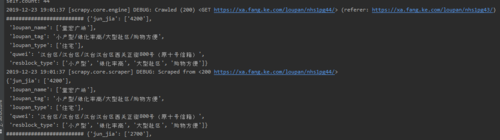
我的代码如下
# -*- coding: utf-8 -*-
import scrapy
from papa.items import PapaItem
import re
class PappSpider(scrapy.Spider):
name = 'papp'
allowed_domains = ['xa.fang.ke.com']
start_urls = ['https://xa.fang.ke.com/loupan/nhs1/']
count=1
page_end=48
def parse(self, response):
loupan_iist=response.xpath("//div[@class='resblock-desc-wrapper']")
for i_item in loupan_iist:
loupan_item=PapaItem()
quwei =i_item.xpath(".//a[@class='resblock-location']/text()").extract()
loupan_item['quwei'] = quwei[1].replace("\t", "").replace("\n", "")
loupan_item['loupan_name'] = i_item.xpath(".//div[@class='resblock-name']/a/text()").extract()
loupan_item['resblock_type'] = i_item.xpath(".//div[@class='resblock-name']/span[1]/text()").extract()
loupan_item['loupan_type'] = i_item.xpath(".//div[@class='resblock-name']/span[2]/text()").extract()
loupan_item['resblock_type']= i_item.xpath(".//div[@class='resblock-tag']/span/text()").extract()
loupan_tag=i_item.xpath(".//div[@class='resblock-tag']/span/text()").extract()
loupan_item['loupan_tag']="/".join(loupan_tag)
loupan_item['jun_jia']=i_item.xpath(".//div[@class='resblock-price']/div[@class='main-price']/span[@class='number']/text()").extract()
xiangqing_url=i_item.xpath(".//div[@class='resblock-name']/a/@href").extract()
xiang_url='https://'+self.allowed_domains[0]+xiangqing_url[0]+"xiangqing"
yield scrapy.Request(xiang_url, meta={'item': loupan_item}, callback=self.loupan_detail_parse)
self.count = self.count + 1
if self.count<=self.page_end:
nextPage=self.start_urls[0][:-1]+'pg%s'%self.count+'/'
yield scrapy.Request(nextPage,callback=self.parse)
else:
return None
def loupan_detail_parse(self,response):
item=response.meta['item']
xiangqing=response.xpath("//ul[@class='x-box']")
kaifashang=xiangqing[0].xpath(".//li[7]/span[@class='label-val']/text()").extract()
guihua=response.xpath("//ul[@class='x-box'][2]/li/span[@class='label-val']/text()").extract()
guihua= ["".join(re.findall('[".:\w+"]',i)) for i in guihua]
peitao=xiangqing[2].xpath(".//span[@class='label-val']/text()").extract()
peitao=["".join(re.findall('[".:\w+"]',i)) for i in peitao]
item['kaifashang']=kaifashang
item['jianzhu_type']=guihua[0]
item['lvhua']=guihua[1]
item['zhandi_area']=guihua[2]
item['rongji']=guihua[3]
item['jianzhu_area']=guihua[4]
item['wuye_type']=guihua[5]
item['hushu']=guihua[6]
item['chanquan_year']=guihua[7]
item['wuye']=peitao[0]
item['cheweibi']=peitao[1]
item['wuyefei']=peitao[2]
item['gongnuan']=peitao[3]
item['gongshui']=peitao[4]
item['gongdian']=peitao[5]
item['chewei']=peitao[6]
return item 无无法师
无无法师浏览 2028回答 0
0回答
-

慕斯4360584
ETNSFETRVACJCUQPYMCECHTQQMUJWHKGUFXJPMIXZUFIEZLAGQEGCBPMXSFEDGACUGBRKTPLQPVRHEPZYEBMWIPYRFVVHYZYYANYIGHNDJYOYGQGNZIILBQJJITPBVIMQGEGNYQFVFKQGMFJKTDWFBGPGPHVKJGDSSOUAZWJLHWKFBQSHVLWBYTMRASRPGSBKSNIMBHSGLNFICXQMOWNNXWUJFXHAZPRAYNJCOSPCYSUSBWOKFFCSTJLIKZGIGRNAZOZIDDYEIGJZJHHGGIGNODPSDQPLNDUHZLVKWVODJHYSUMMBWLDEZXOQMMXFBTVPDCOYTBDHWPQEZLNEGYXTQMAVMDIHMBKPIXBXCLZPPZIZNJWDQPVFHMJMRXCEIUKMPLJLHQOXMGYNBKUQLQGZLDUVDSOBJIXYRBPDZEMLAKBJLBHSJLAZZDGJRMBJJBGEIOYCLUDPOQYXVZNVLTZOSKTMIMXHDZYUPVBKWPBBWZKTQMFYMRHAORZVRBGYGGODRWJIMJUKWESVXMSHRJOKWBRDDVJNTAJBGZBVDVVYZSSXLXKXFAQMCYHWYIDCCXFMKRUPYHRVODYMEPHEWZJSUIOXMOZRNYMFLDCZQKFVSBAVGKHMUXMIZMUQUPRAZPRDIIMOKGOIGLUAFMEFRSBJQHTHPRWYAWDSGFBAWBIRFNPYDILXNFUCKUSIKCDFUWHCWXOTEJHPJO -
慕斯4360584
JMMLFJKAEOFMXMGJXXMCWWLZHBVNOLGEHNPZWIDNNHBFHPHXLPVCJQHQMXRFWFUHSIFBGRVGVSWQNXSBPZZUIJJAORVHROOYPAQCVRVLLPNXRYRKKEYSSCIIJAXRVIJJUYMMWFMMQBOYLYCMAWYLYBYHUKSUSITSJIPJZBOHRRGWVSWCOUHKBGDLCWMUZBQRZZWGWMQGQHHRVIBCLJKTQGHANRIOSNCPZQXZGHUANQHXOIIFLITFLAVVMFVJGOQOPIPXOVFZAFWDRRHYISIUMADDKXNBBBPIVPJGXUEUFPADQNBOCFCMKTOZGDXLYYPVHAABPWROFVJIFZAEJDFCGXWZDNKUXURLDEXHHUOXULVXJTQAFSNXEEYOBEFNAPJPMEXTADJTANKVPYVMHMGAKAADWIVZJWGWOLDGSSWHUELYPKJUNODMFMJQCCMZPUKCTKNNWZHRUNOHYRYXQCRKXULJSXCKNFSLJGNXPRRUUAXKXEHMOOVKYLZJDKKKDAKEXSCEEURTHJPCZFTWEBGJDTXUHWJIAXKROVQEGDAAZJDTWOGKKWZAXHHLRSISPIVIIIPAHHTVFYMPLDDMJZKOKDAABZCGMBGPFTSCFLVBTPFWTYLUENAPRQRUFOEYBLCBUKIQXNTNQFLOFPYSOYOZCZJHAZANGGASIILOORKIBOSHXUERSVRBLGQFYDQJAXAXMFKUFZZFSIY -
慕斯4360584
WDMPZFPDHAXCWPYMSIFSJATMLOSAWMWMWRDMPAVKRUEKTVYLZMIYFIBYEKIBYEKKUHVRFMDGWSWJZZSRHRBRCSZFWJIYISDAMGAZSIRLLUCWMCNZYPZCOXXADDFCFLFIOLMZTPTNNNWTMPCPVYKUXKXXDDMZRIZSLLRLMWVPZMWCWXHHYURLEKRHHSLLETANJMGTDTICLSVVYUORRTPXNDNXKQWGQUYEIPIVSUOYQKKXFPWTNAOKOYLFFJCDMLKBOQTKDMGWCIYSCUXRXYOISYLXXRIFLYVFWMDOSPVCXOXYLZZFWXPIUZPWTTTWHNOORAELWZARBVUOIYSJZKYITYKKBRLOLCIWNTZTQNGJCITGPISJJQLPZGWVBFMPANPJSKGLRBVSZFGACUNQWIFQQHQPSDBCMVRFNXNBKBYOMJAKDCJPDUKBRKNBKABBBLRDHHRNFLAUXCBOYSHJMXTHHURRIEZPPZQJXFPJPOEOIXGKURKHGLISVISVSVPIOJTKAAUSUNJQQQHEUEFYJSJQWLOTTLVKQGGHUHKUEOBUQDXPMVSCWZSMRPJTZDEMYUYYFMJHCOZQZTABGTAUGLIDANHICIMGBTWKROIFWDHUYOLSCWNNNYLXMZSZERLBIIPWUAUESVIQZKGNQAKRAXOBJLGYIMFSJPMRNNQRBBILCAZYHBVVWXNXRZCIFRHRLIYIQPXYOIFVCVW

 Python
Python
 爬虫
爬虫
 数据分析&挖掘
数据分析&挖掘