父标签存在4个子标签内容,但只能爬取到2个。
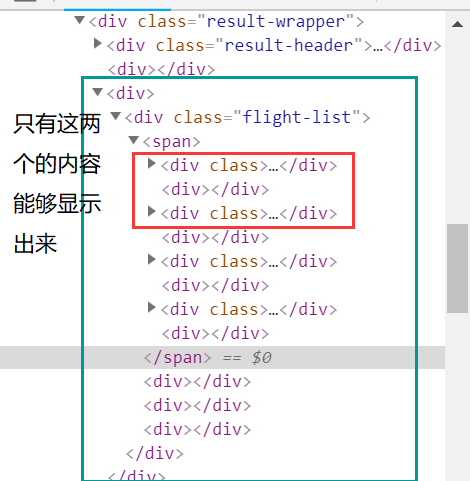
各位高手:本人小白,最近在学习爬虫技术,以携程网机票作为起步对象。 过程中发现使用子标签函数并不能返回所有的子标签内容
(如图),父标签是内容是<div class='flight-list">, 四个子标签内容均为 <div class>...</div> ,但实际能够取数的只有前两个,请问这是为什么,并如何解决呢?感激不尽!
代码:
from selenium import webdriver
from bs4 import BeautifulSoup
import time
brower = webdriver.PhantomJS(executable_path='D:/phantomjs-2.1.1-windows/phantomjs-2.1.1-windows/bin/phantomjs')
try:
html_infor = brower.get("https://flights.ctrip.com/itinerary/roundtrip/KHH-WUH?date=2018-11-21,2018-11-21&portingToken=570b1bdc855c4eaba0654eb83e9923f7")
time.sleep(20)
pageSource = brower.page_source ###网页加载信息的实体化
bsObj = BeautifulSoup(pageSource) ###放进美汤
for child in bsObj.find("div",{"class":"flight-list"}).children:
print(child)
finally:
brower.close()
 慕勒13948
慕勒13948浏览 2427回答 1
1回答
-

MyFray
上面的格式太乱了,代码我在这里重新打一下for i in range(20): js = "var q=document.documentElement.scrollTop={}" js = js.format((i+1) * 400) self.driver.execute_script(js) time.sleep(0.1)

 Python
Python
 爬虫
爬虫