爬虫爬取豆瓣数据时,python正则匹配url问题
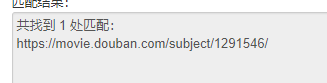
https://movie.douban.com/subject/1291546/
上面是url,我写的匹配是:
re.compile(r'http[s]?://.*/subject/.*/',re.S)) 网上测试结果也是匹配,但是,程序运行就是提取不出网址
 慕粉1417129261
慕粉1417129261浏览 1900回答 3
3回答
-

尘嚣3919577
re.compile(r'http[s]?://.*/subject/.*/',re.S))是创建匹配规则。是否未使用?例如: patten = re.compile(r'http[s]?://.*/subject/.*/',re.S)) result = patten.findall(index.html)有很多匹配方法具体可以度娘一下

 Python
Python
 爬虫
爬虫