老师,我跟你写的代码,为什么运行出来的结果不对呢?麻烦帮看看
# -*- coding: utf-8 -*-
"""
Created on Thu Oct 18 15:09:43 2018
@author: Yym
公共信息抽取信息
"""
import os
"""
第一个函数:从rating文件中抽取用户的点击序列
第二个函数:从movies里面得到item的详细信息
"""
def get_user_click(rating_file):
"""
得到用户点击数
传入参数:
rating_file:input file
return:
dict,key.userid,value:[itemID1,itemId2]
"""
if not os.path.exists(rating_file):
return{}
fp=open(rating_file)
#第一行数据不能用
num=0
#返回一个数据结构
user_click={}
#按行处理
for line in fp:
if num==0:
num+=1
continue
item=line.strip().split(',')
if len(item)<4:
continue
[userid,itemid,rating,timestamp]=item
if float(rating)<3.0:
continue
if userid not in user_click:
user_click[userid]=[]
user_click[userid].append(itemid)
fp.close()
return user_click
"""
第二个函数:从movies里面得到item的详细信息
"""
def get_item_info(item_file):
"""
get item info[title,genres]
args:
item_file:input iteminfo file
return:
a dict, key itemid,value:[title,genres]
"""
if not os.path.exists(item_file):
return{}
num=0
item_info={}
fp=open(item_file)
for line in fp:
if num==0:
num+=1
continue
#按行分割
item=line.stirp().split('')
#过滤小于3的行,和超过3的处理
if len(item)<3:
continue
if len(item)==3:
[itemid,title,genres]=item
elif len(item)>3:
itemid=item[0]
genres=item[-1]
title=",".join(item[1:-1])
if itemid not in item_info:
item_info[itemid]=[title,genres]
fp.close()
return item_info
#测试
if __name__=="__main__":
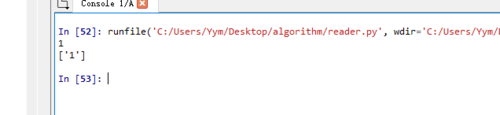
user_click=get_user_click('ratings.txt')
user_click_len=len(user_click)
print(user_click_len)
print(user_click["1"])
"""
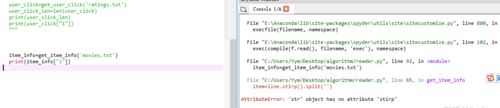
item_info=get_item_info('movies.txt')
print(item_info["1"])
"""
测试一:
测试二:
 慕慕1622691
慕慕16226911回答
相关分类
 Python
Python