爬虫爬取网页后,如何保存网页?
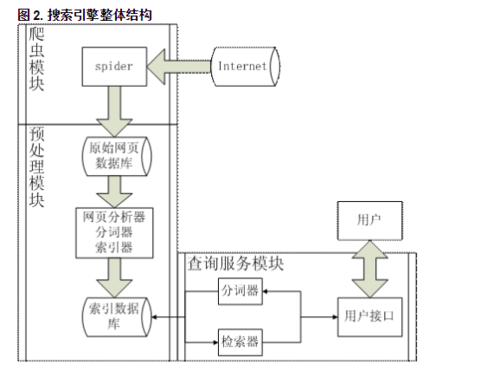
爬虫从 Internet 中爬取众多的网页作为原始网页库存储于本地,然后网页分析器抽取网页中的主题内容交给分词器进行分词,得到的结果用索引器建立正排和倒排索引,这样就得到了索引数据库,用户查询时,在通过分词器切割输入的查询词组并通过检索器在索引数据库中进行查询,得到的结果返回给用户。
请问这里原始网页库是该怎么实现,是直接存到数据库里吗?还是什么形式?
如果是存到数据库里,应该有哪些字段?
 犯罪嫌疑人X
犯罪嫌疑人X浏览 2701回答 2
2回答
-

holdtom
他这里的意思是抓取到的网页直接以文件的方式存放到本地磁盘

 爬虫
爬虫