python合并文件(#利用字符串和列表将两个通讯录文本合并为一个文本)
# 下面文件编码方式皆为 utf-8, 运行环境为 windows10+python3.5
问题描述: 已知两个文件 EmailAddressBook.txt 和 TeleAddressBook.txt(内容如下)
EmailAddressBook.txt
姓名 电话号码 王丽丽 13254687@qq.com 张三 14554687@163.com 王五 15954687@outlook.com 桑迪 17854687@foxmail.com
TeleAddressBook.txt
姓名 电话号码 王丽丽 13254687912 张三 14554687912 李四 15954687912 桑迪 17854687912
现编写程序将两个文件合并为AddressBook.txt
姓名 电话 邮箱 张三 14554687@xx.com 14554687912 桑迪 17854687@xx.com 17854687912 王丽丽 13254687@xx.com 13254687912 王五 15954687@xx.com ----- 李四 ----- 15954687912
但是我的程序只能合并为如图, 姓名后的 字符'\t' 不能显示,不知道哪里出错,另外用 windows自带的记事本打开, 内容只显示在一行,没有换行
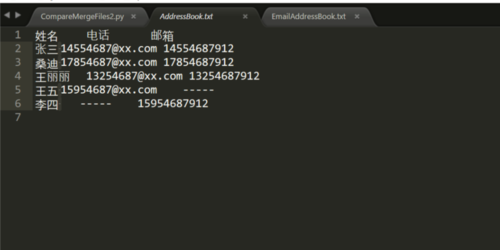
程序代码如下
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
def toDic(_lines):
dic = {}
for line in _lines: #获取第一个文本中的 姓名和邮箱 信息
e = line.split()
#将文本读出来的 bytes 转换为 str 类型
dic[e[0]] = str(e[1].decode('utf-8'))
return dic
def main():
file1 = open('EmailAddressBook.txt', 'rb')
file2 = open('TeleAddressBook.txt', 'rb')
file1.readline()#跳过第一行
file2.readline()
lines1 = file1.readlines()
lines2 = file2.readlines()
dic1 = toDic(lines1) #字典方式保存
dic2 = toDic(lines2)
###开始处理
lines = []
lines.append('姓名\t 电话 \t 邮箱\n')
for key in dic1:
s = ''
if key in dic2.keys():
s = '\t'.join([str(key.decode('utf-8')), dic1[key], dic2[key]])
s += '\n'
else:
s = '\t'.join([str(key.decode('utf-8')), dic1[key], str(' ----- ')])
s += '\n'
lines.append(s)
for key in dic2:
s = ''
if key not in dic1.keys():
s = '\t'.join([str(key.decode('utf-8')), str(' ----- '), dic2[key]])
s += '\n'
lines.append(s)
#防止出现乱码
file3 = open('AddressBook.txt','bw')
for line in lines:
line = line.encode('utf-8')
file3.write(line)
file3.close()
file2.close()
file1.close()
print('The addressBook are merged!')
if __name__ == '__main__':
main()---------
谢谢
 Yexiaomo
Yexiaomo浏览 3748回答 4
4回答
-

日职2016_软一刘彻
本来都关机了,准备睡觉了,但是躺在床上突然想到 I/O操作不占用cpu,正好可以使用一下Python多线程。。。import threading info = {} name_email = {} name_phone = {} def read(file_name): exec_dict = None if file_name == 'EmailAddressBook.txt': exec_dict = name_email elif file_name == 'TeleAddressBook.txt': exec_dict = name_phone else: pass with open(file_name, encoding='utf-8') as f: for line in f: res = line.split() exec_dict[res[0]] = res[1] exec_dict.pop('姓名') if __name__ == '__main__': thread1 = threading.Thread(target=read, args=('EmailAddressBook.txt',)) thread2 = threading.Thread(target=read, args=('TeleAddressBook.txt',)) thread1.start() thread2.start() thread1.join() thread2.join() names = set([n for n in name_email]) name_ext = set([n for n in name_phone]) names.update(name_ext) for key in names: info[key] = [] for key, tel in name_phone.items(): info[key].append(tel) for key, email in name_email.items(): info[key].append(email) with open('AddressBook.txt', 'w', encoding="utf-8") as f: f.write("姓名 \t\t 电话 \t\t\t 邮箱") for key, value in info.items(): s = "\n%s\t\t%s\t\t\t%s" if len(value) < 2: if value[0].isdigit(): # 代表第一个值是电话 f.write(s % (key, value[0], '---------')) else: # 代表第一个值是邮箱 f.write(s % (key, '---------', value[0])) else: f.write(s % (key, value[0], value[1])) -
日职2016_软一刘彻
根据题目,我也写了一个demo,供你参考下。info = {} name_email = {} name_phone = {} if __name__ == '__main__': with open('EmailAddressBook.txt', encoding='utf-8') as f: for line in f: res = line.split() name_email[res[0]] = res[1] name_email.pop('姓名') with open('TeleAddressBook.txt', encoding='utf-8') as f: for line in f: res = line.split() name_phone[res[0]] = res[1] name_phone.pop('姓名') names = set([n for n in name_email]) name_ext = set([n for n in name_phone]) names.update(name_ext) for key in names: info[key] = [] for key, tel in name_phone.items(): info[key].append(tel) for key, email in name_email.items(): info[key].append(email) with open('AddressBook.txt', 'w', encoding="utf-8") as f: f.write("姓名 \t\t 电话 \t\t\t 邮箱") for key, value in info.items(): s = "\n%s\t\t%s\t\t\t%s" if len(value) < 2: if value[0].isdigit(): # 代表第一个值是电话 f.write(s % (key, value[0], '---------')) else: # 代表第一个值是邮箱 f.write(s % (key, '---------', value[0])) else: f.write(s % (key, value[0], value[1]))代码写的不是很好,轻喷,别打击我幼小的心灵[捂脸][捂脸][捂脸]

相关分类
 Python
Python