pdf转txt后打开乱码
来源:2-4 抽取PDF文档文本内容

慕村1348781
2019-11-22 15:42
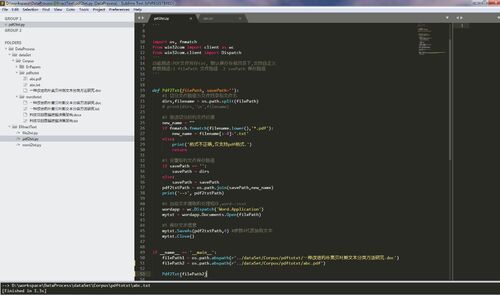
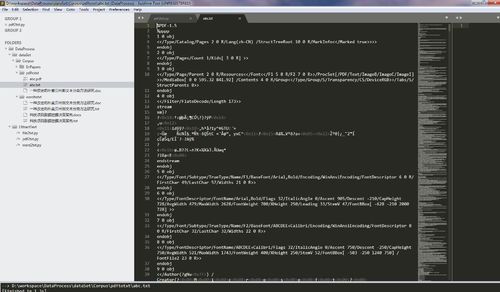
用各种文本编辑器打开都是乱码,是哪里设置不对吗?
写回答
关注
1回答
-

- 慕村1348781
- 2019-11-26 13:02:52
问题还是我自己通查多方资料解决了,案例中不管是pdf文件还是doc文件,都是打开word软件转格式,所以最关键的就是一个能打开pdf格式的word版本,我使用word2016可行。代码也没问题。如果运行后txt显示乱码,建议更换office版本到2016。
Python数据预处理(一)一抽取多源数据文本信息
Python数据预处理---人工智能通用技术
16345 学习 · 41 问题
相似问题