在新的(未见过的)文本上部署文本分类模型
我正在研究文本分类问题。我附上了我训练过的文本分类模型的简单虚拟片段。
如何在 new_text 上部署模型?当模型用于 时check_predictions,它可以正确地对文本进行分类,但是,当使用新数据时,分类是错误的。
这是因为new_text需要矢量化吗?我错过了一些基本的东西吗?
from collections import Counter
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score, precision_score, recall_score
df = pd.read_csv("/Users/veg.csv")
print (df)
X_train, X_test, y_train, y_test = train_test_split(df['Text'], df['Label'],random_state=1, test_size=0.2)
cv = CountVectorizer()
X_train_vectorized = cv.fit_transform(X_train)
X_test_vectorized = cv.transform(X_test)
naive_bayes = MultinomialNB()
naive_bayes.fit(X_train_vectorized, y_train)
predictions = naive_bayes.predict(X_test_vectorized)
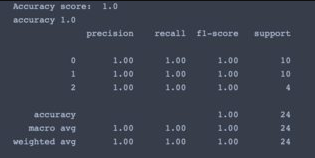
print("Accuracy score: ", accuracy_score(y_test, predictions))
print('accuracy %s' % accuracy_score(predictions, y_test))
print(classification_report(y_test, predictions))
check_predictions = []
for i in range(len(X_test)):
if predictions[i] == 0:
check_predictions.append('vegetable')
if predictions[i] == 1:
check_predictions.append('fruit')
if predictions[i] == 2:
check_predictions.append('tree')
dummy_df = pd.DataFrame({'actual_label': list(y_test), 'prediction': check_predictions, 'Text':list(X_test)})
dummy_df.replace(to_replace=0, value='vegetable', inplace=True)
dummy_df.replace(to_replace=1, value='fruit', inplace=True)
dummy_df.replace(to_replace=2, value='tree', inplace=True)
print("DUMMY DF")
print(dummy_df.head(10))

1回答
-
牧羊人nacy
无论您输入模型中的任何(新)文本都必须经过与训练数据完全相同的预处理步骤 - 这里 CountVectorizer已经与您的X_train:new_data_vectorized = cv.transform(new_data) # NOT fit_transformnew_predictions = naive_bayes.predict(new_data_vectorized)00
相关分类