如何在Python中实现FPGrowth算法?
我已经在Python中成功使用了apriori算法,如下所示:
import pandas as pd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
df = pd.read_csv('C:\\Users\\marka\\Downloads\\Assig5.csv')
df = apriori(df, min_support=0.79, use_colnames=True)
rules = association_rules(df, metric="lift", min_threshold=1)
rules[ (rules['lift'] >= 1) &
(rules['confidence'] >= 1) ]
我想使用FPGrowth算法来查看是否获得了相同的结果,但是我相信我使用的是错误的,因为我没有得到相似的输出。spark的文档
所以我的代码又是:
from pyspark.mllib.fpm import FPGrowth
from pyspark import SparkConf
from pyspark.context import SparkContext
sc = SparkContext.getOrCreate(SparkConf().setMaster("local[*]"))
data = sc.textFile("C:\\Users\\marka\\Downloads\\Assig6.txt")
transactions = data.map(lambda line: line.strip().split(' '))
model = FPGrowth.train(transactions, minSupport=0.2, numPartitions=10)
result = model.freqItemsets().collect()
for fi in result:
print(fi)
但是我得到了以下答案,而不是真正的答案,我在做什么错?
FreqItemset(items=['1\t1\t1\t1\t1\t1\t1\t0\t0\t0\t0\t1\t1\t0\t0\t1\t1\t1\t1\t1\t0\t0'], freq=24)
为了制作Assig6,我只是将我原来的csv重新保存为txt
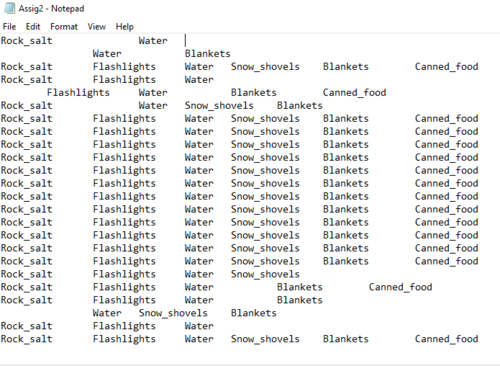
我开始更改格式并更新每个用户的代码10136092,但仍然得到不希望的输出。这是我的代码,输出和新输入的示例图片。
from pyspark.mllib.fpm import FPGrowth
from pyspark import SparkConf
from pyspark.context import SparkContext
sc = SparkContext.getOrCreate(SparkConf().setMaster("local[*]"))
data = sc.textFile("C:\\Users\\marka\\Downloads\\Assig2.txt")
data.map(lambda line: line.strip().split())
transactions = data.map(lambda line: line.strip().split(' '))
model = FPGrowth.train(transactions, minSupport=0.2, numPartitions=10)
result = model.freqItemsets().collect()
for fi in result:
print(fi)
输出
FreqItemset(items=['Rock_salt\tFlashlights\tWater\tSnow_shovels\tBlankets\tCanned_food'], freq=34)
2回答
-
函数式编程
您的数据不是Spark FPGrowth算法的有效输入。在Spark中,每个购物篮都应表示为唯一标签列表,例如:baskets = sc.parallelize([("Rock Salt", "Blankets"), ("Blankets", "Dry Fruits", Canned Food")])而不是二进制矩阵,就像您使用的其他库一样。请先将您的数据转换为上述格式。此外,您的数据是制表符,并且没有空格分隔,因此即使输入正确,您也应该像 data.map(lambda line: line.strip().split())00 -
慕雪6442864
我认为该文件是制表符分隔的,因此应将其分割'\t'而不是' 'transactions = data.map(lambda line: line.strip().split('\t'))00
相关分类