为什么用Beautifulsoup无法提取微博粉丝列表的page数
用python写小脚本想爬取新浪科技的粉丝http://weibo.com/1642634100/fans,先要获得粉丝页数,用chrome看到的html结构如下:
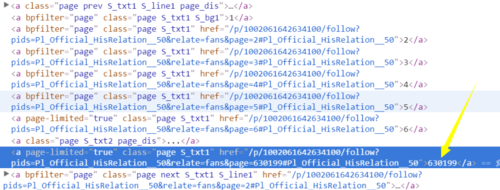
写的脚本如下,获得的list为空
def getFansPage(urlfans):
req = urllib2.Request(urlfans, headers=headers)
time.sleep(sletime)
html_sample = exceptRequest(req).read()
# 分析得到pagenum所在属性
soup = BeautifulSoup(html_sample,'html.parser')
pagenum = soup.find_all("a",class_="page prev S_txt1 S_line1 page_dis") return pagenum后来发现这样连都是空的:
pagenum = soup.find_all("a",class_="WB_frame")这是为什么呢?
浏览 826回答 1
1回答
相关分类