print(response.text)时报错如图。导致打印不了正确的信息ERROR: Spider error processing <GET https://movie.douban.com/top250> (referer: None)
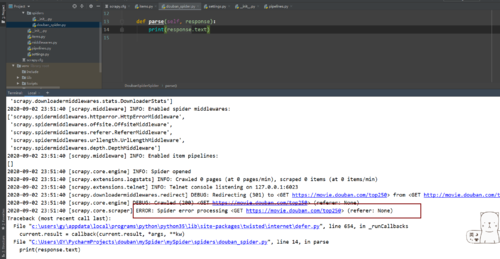
请问老师这个报错该怎么操作是不是无法引用 scrapy:如图 谢谢老师
贴上所有的返回的代码:
(venv) C:\Users\GY\PycharmProjects\douban\mySpider\mySpider\spiders>scrapy crawl douban_spider
c:\users\gy\appdata\local\programs\python\python35\lib\site-packages\OpenSSL\crypto.py:12: CryptographyDeprecationWarning: Python 3.5 support will be dropped in the nex
t release ofcryptography. Please upgrade your Python.
from cryptography import x509
2020-09-02 23:51:39 [scrapy.utils.log] INFO: Scrapy 2.1.0 started (bot: mySpider)
2020-09-02 23:51:39 [scrapy.utils.log] INFO: Versions: lxml 4.4.3.0, libxml2 2.9.10, cssselect 1.1.0, parsel 1.6.0, w3lib 1.22.0, Twisted 19.10.0, Python 3.5.0 (v3.5.0:
374f501f4567, Sep 13 2015, 02:27:37) [MSC v.1900 64 bit (AMD64)], pyOpenSSL 19.1.0 (OpenSSL 1.1.1g 21 Apr 2020), cryptography 3.1, Platform Windows-7-6.1.7601-SP1
2020-09-02 23:51:39 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.selectreactor.SelectReactor
2020-09-02 23:51:39 [scrapy.crawler] INFO: Overridden settings:
{'BOT_NAME': 'mySpider',
'NEWSPIDER_MODULE': 'mySpider.spiders',
'SPIDER_MODULES': ['mySpider.spiders'],
'USER_AGENT': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
2020-09-02 23:51:39 [scrapy.extensions.telnet] INFO: Telnet Password: 51ea689089de75be
2020-09-02 23:51:39 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.logstats.LogStats']
2020-09-02 23:51:40 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2020-09-02 23:51:40 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2020-09-02 23:51:40 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2020-09-02 23:51:40 [scrapy.core.engine] INFO: Spider opened
2020-09-02 23:51:40 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2020-09-02 23:51:40 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2020-09-02 23:51:40 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET https://movie.douban.com/top250> from <GET http://movie.douban.com/top250>
2020-09-02 23:51:40 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://movie.douban.com/top250> (referer: None)
2020-09-02 23:51:40 [scrapy.core.scraper] ERROR: Spider error processing <GET https://movie.douban.com/top250> (referer: None)
Traceback (most recent call last):
File "c:\users\gy\appdata\local\programs\python\python35\lib\site-packages\twisted\internet\defer.py", line 654, in _runCallbacks
current.result = callback(current.result, *args, **kw)
File "C:\Users\GY\PycharmProjects\douban\mySpider\mySpider\spiders\douban_spider.py", line 14, in parse
print(response.text)
UnicodeEncodeError: 'gbk' codec can't encode character '\xee' in position 21674: illegal multibyte sequence
2020-09-02 23:51:40 [scrapy.core.engine] INFO: Closing spider (finished)
2020-09-02 23:51:40 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 594,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 12895,
'downloader/response_count': 2,
'downloader/response_status_count/200': 1,
'downloader/response_status_count/301': 1,
'elapsed_time_seconds': 0.554,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2020, 9, 2, 15, 51, 40, 845000),
'log_count/DEBUG': 2,
'log_count/ERROR': 1,
'log_count/INFO': 10,
'response_received_count': 1,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'spider_exceptions/UnicodeEncodeError': 1,
'start_time': datetime.datetime(2020, 9, 2, 15, 51, 40, 291000)}
2020-09-02 23:51:40 [scrapy.core.engine] INFO: Spider closed (finished)
(venv) C:\Users\GY\PycharmProjects\douban\mySpider\mySpider\spiders>
个回答
-
- 慕的地4323161
- 2020-09-03 21:09:15
找到问题了 是因为
'https://movie.douban.com/top250'
带https的 我写成了http 报错了