试着写一下我的语句和理解,比老师的更加有可读性,好理解
老师给出的答案可读性实在太差了,不直观,不符合正常逻辑,老师又不作解释。下面是我的语句:
SELECT c.user_name, c.timestr, c.kills FROM
(SELECT a.id, a.user_name, b.timestr, b.kills FROM user1 a INNER JOIN user_kills b on a.id = b.user_id) c
INNER JOIN user_kills d ON c.id = d.user_id AND c.kills <= d.kills
GROUP BY c.user_name, c.timestr
HAVING COUNT(*) <= 2
ORDER BY c.user_name, c.kills DESC;
个回答
-
- 慕祈
- 2022-11-30 23:24:52
SELECT a.user_name, b.timestr, b.kills FROM user1 ainner join
( select b.user_id, b.kills, max(b.timestr) as timestr from user_kills b
GROUP BY b.user_id, b.kills
) b on a.id = b.user_id
INNER JOIN
( select b.user_id, b.kills, max(b.timestr) as timestrfrom user_kills b
GROUP BY b.user_id, b.kills
) d
ON a.id = d.user_id AND b.kills <= d.kills
GROUP BY b.kills
HAVING COUNT(*) <= 2
ORDER BY a.user_name, b.kills DESC;
个人的一个修改,主要思路就是表连接之前先把重复的过滤(数据分组然后取最大的时间)
-
- 洛奇2019
- 2021-01-16 22:33:21
可以把子查询 c 去掉 ,改成两次 inner join。
-
- Henry_Liu
- 2020-01-10 08:05:19
1.括号中的子查询连接两张表,很好理解。
2.子查询得到的集合再去连接user_kills表,条件c.id = d.user_id,很好理解。
条件c.kills <= d.kills的作用,使得杀怪最多的天数只出现一次,第二多的天数出现两次,如此类推。
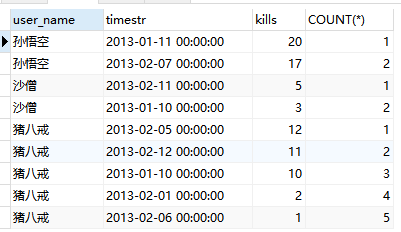
重复出现的次数,其实就等于杀怪数的排名。放两个图,不懂的人结合图细细品一下。


3.GROUP BY c.user_name, c.timestr分组。GROUP BY有去除重复的作用,此时的表:

4.HAVING COUNT(*) <= 2,把重复出现次数小于等于2的保留,也就是杀怪最多的两天。
有人可能会卡在这一步,觉得不好理解。可以结合第二步来看,虽然分组后看不到重复,但是通过函数可以计算出来。
再放个图(没加HAVING COUNT(*) <= 2的时候,而且增加count列,方便理解),还不懂就没救了。
5.ORDER BY c.user_name, c.kills DESC,排序就不用解释了吧。