源自:4-2 字节流之文件输入流FileInputStream-2
关于io字节流问题
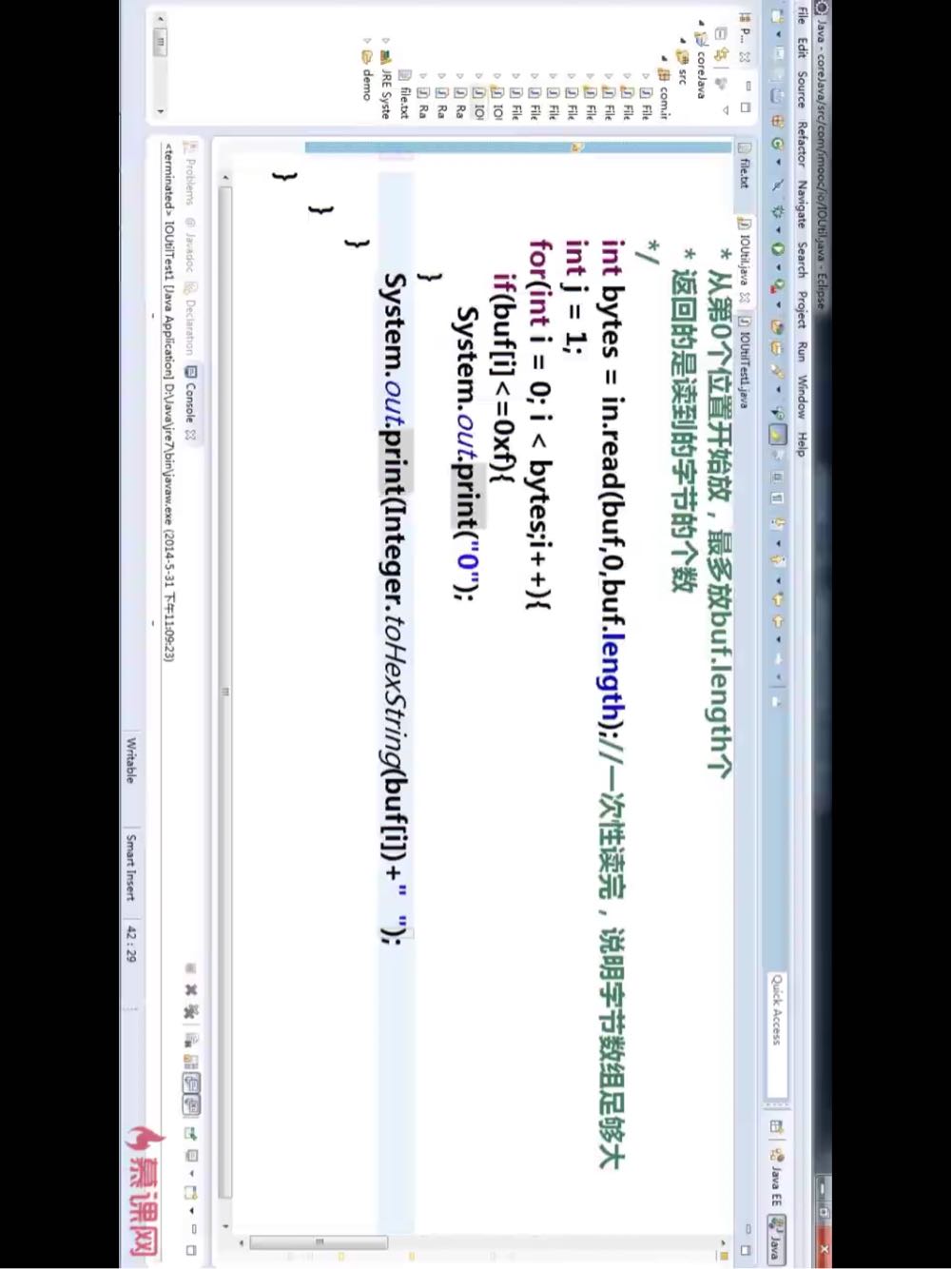
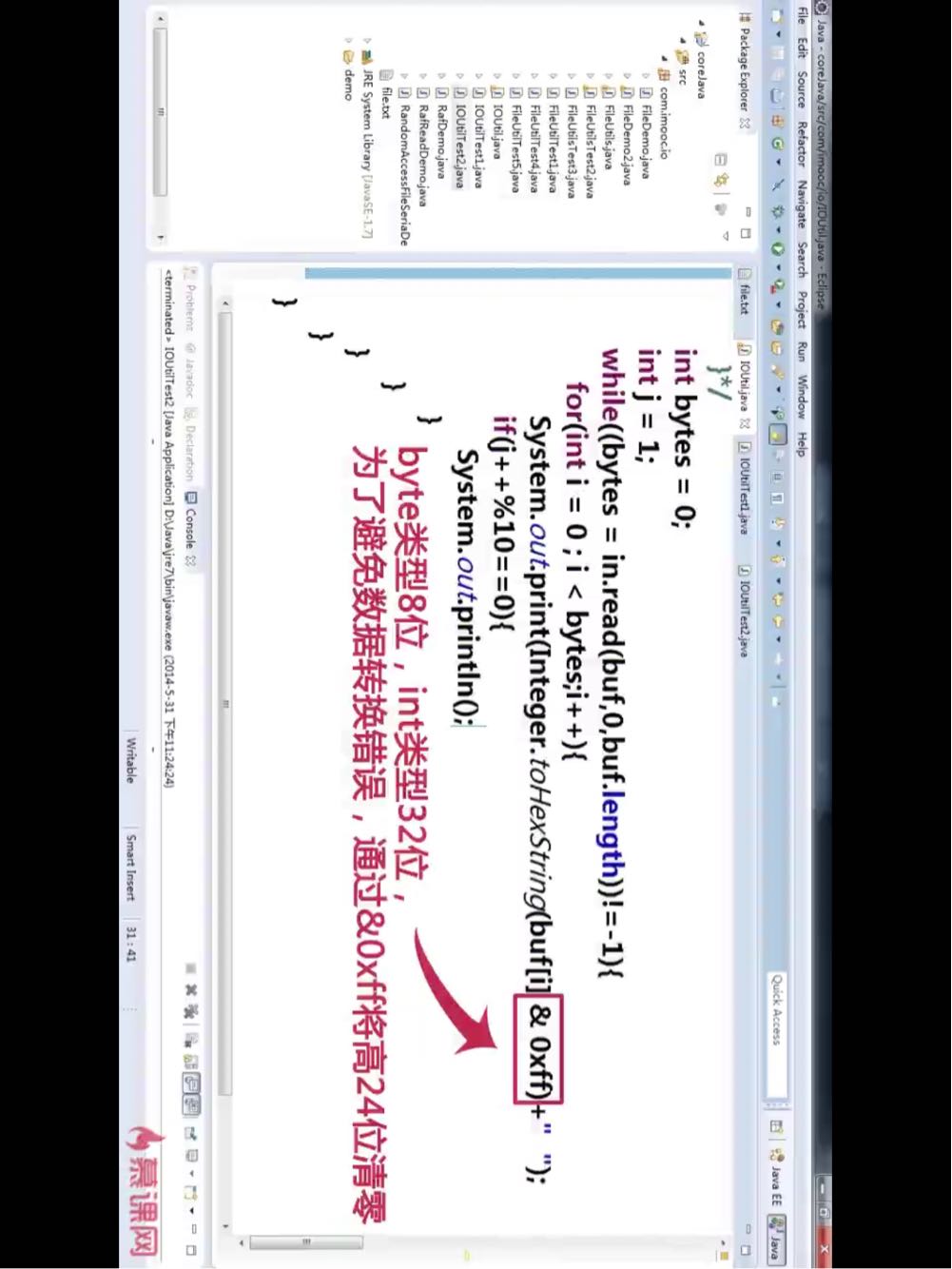
请问关于这两种方法我的疑问是
两图中的方法 第二个相对于第一个到底有什么好处 以及如何理解
提问者:hy_wang
2017-10-10 16:37
个回答
-
- 一枚flora
- 2017-10-27 20:37:13
就是通过while循环,read的指针不断往后移,开始是开足马力每次都length长度,只有可能到最后一次,read不足length。由此实现只需要开辟一个很小空间的byte[]就可以读入很多的字节
-
- qq_安居旧巷猫患者_0
- 2017-10-21 16:59:43
感觉就是
第一种方法无论你读取的文件有多大 他就会读取到byte数组满了以后就不会再读取了 所以就只读取出来byte所能存放的那么多的字节
第二种方法是循环的向byte数组中读取数据,一直读取到文件结尾,也就是read方法返回-1的时候
说到好处也就是第二个方法可以设置较小的数组读取完较大的文件,
因为第一种方法有着数组大小的控制,想要读取完一个未知文件的话 就要设置一个较大的数组
-
- 慕标7443549
- 2017-10-11 20:26:15
第一个设置的byte数组设置的长度足够大,所以能够一次性能够读完
但是第二个的设置多了一个while , 即可能一个BYTE数组没法一次性读完,所以需要加上判断条件