-
 慕斯1033074
慕斯1033074
- 特别卡,是我网不好吗
- 已采纳 慕雪8379791 的回答
也有可能是别的原因
- 2022-05-31 2回答·710浏览
-
 weixin_慕斯卡5179427
weixin_慕斯卡5179427
- set global long_query_time不起作用
把global去掉就生效了
- 2021-02-21 1回答·797浏览
-
 牛在飞
牛在飞
- 为啥要设计一张中间表?
商品和分类对应关系表可以省略
- 2021-01-28 3回答·1134浏览
-
 慕UI3128855
慕UI3128855
- sakila-db导入
win导入啊
步骤也很简单:https://jingyan.baidu.com/article/414eccf612e0c16b431f0a95.html这里用cmd登入mysql
然后在执行官方提供的命令就OK了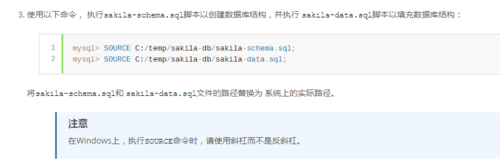
- 2020-11-26 1回答·1163浏览
-
 qq_追梦永不止息_0
qq_追梦永不止息_0
- 老师,你使用的这个数据库在哪里下载啊?我按照网址没找到呢
https://www.mysql.com/downloads/ 这里面找你需要的版本
- 2020-09-17 1回答·846浏览
-
 qq_落泪无痕_0
qq_落泪无痕_0
- 我有个批量插入数据的功能,由于表的字段有点多大概有200多个字段,longtext和varchar的类型的字段有点多,分批写入的时候写入2000条就很慢,用了大概20多秒,请问怎么优化?
带插入数据先写入消息队列或缓存,然后再从队列或缓存取出来写入数据库。同步改异步
- 2020-07-15 1回答·1073浏览
-
 阿理理
阿理理
- 请问如下子查询的优化,为什么性能变差。
命中率低,因为film和actor是多对多关系吧(我没看具体的表结构)?导致查询的IO大,所以性能低
- 2020-06-23 1回答·1001浏览
-
 Andylance
Andylance
- order by了其他字段并且想要limit分页, 如何优化性能呢?
只能联合索引了
- 2020-05-30 2回答·1143浏览
-
 疯格_
疯格_
- 索引失效问题
如果有其他函数计算会失效,但是max是求最大值,索引本身就是按大小排好的,所以max,min都不会失效
- 2020-04-24 1回答·999浏览
-
 _冬阳
_冬阳
- 重点是学知识!
说的对!
- 2020-02-28 1回答·789浏览
-
 和尚夜袭寡妇村
和尚夜袭寡妇村
- 是不是念冗余 (rong 三声)?
多音字
- 2020-02-21 1回答·1129浏览
-
 白水00
白水00
- 不是应该有一张订单快照表?有些信息边了,但是订单的信息不能变
是的,我感觉也应该有一张表
- 2020-02-16 1回答·974浏览
-
 执念messi
执念messi
- 类型存储不就是时间戳么???
是啊,你是对的,有其他疑问么
- 2020-01-16 1回答·1010浏览
-
 庄学爸
庄学爸
- 不知道怎么选MySQl慢查询日志分析工具的同学,看这个连接
好的,谢谢
- 2019-10-06 1回答·1572浏览
-
 qq_慕丝3367668
qq_慕丝3367668
- 水平分表 查询如何写 mybatis如何写?挑战如何解决?都没有讲
自己想想就知道了。
水平分表由一张表变成了多张子表,那么就涉及在查询时从哪张子表中获取,以及在插入时要插入到哪一张表当中。
这里的就涉及数据分片的路由策略,有非常多的方法,主流的不过就是Hash、一致性Hash、虚拟槽等等,这个需要在程序进行控制,由程序计算后自行控制要在哪张表插入和查询,比如主键是程序赋予的UUID,当靠mysql你玩呢?
- 2019-09-08 1回答·1237浏览
-
 慕先生8692493
慕先生8692493
- 没有学过mysql数据库方面的基础
- 2019-08-23 0回答·752浏览
-
 扬州灬炒饭
扬州灬炒饭
- 实际开发的如何权衡?
实际项目开发很多索引都是不连续的,但是一般用户也不会一直翻页下去,几百页最多了
- 2019-07-15 2回答·781浏览
-
 chaosbead
chaosbead
-
 qq_知弦轻流_0
qq_知弦轻流_0
- 用户表 邮编依赖地址--》地址依赖用户ID,这难道不是传递依赖吗?
是传递依赖,可以将地址和对应的邮编单独做一个表
- 2019-06-14 1回答·940浏览
-
 xingkong8
xingkong8
- 我想问下mysql中的explain只是计划,并没有执行sql吧
EXPLAIN :模拟Mysql优化器是如何执行SQL查询语句的,从而知道Mysql是如何处理你的SQL语句的。分析你的查询语句或是表结构的性能瓶颈。
- 2019-05-29 1回答·1850浏览
-
 右席曦
右席曦
- 为什么要count(*) ? 在子查询中不是直接 select actor_id 就可以了吗
count(*)是统计按actor_id分组后,每一组的数量,查询后会返回 actor_if,cnt 两个字段(cnt是别名),直接你那样是不会统计数量的
- 2019-05-26 2回答·1358浏览
-
 Kunghsu
Kunghsu
- https://tools.percona.com/wizard 这个网址访问不了?
这是14年就有的课程,可能是时间太久了,这个网站已经不维护了
- 2019-05-11 1回答·1565浏览
-
 慕勒7601522
慕勒7601522
- 业务让用title排序,结果优化变成了主键,
应该就是创建索引了,一般是时间排序吧
- 2019-05-09 1回答·1006浏览
-
 慕粉1312521428
慕粉1312521428
- mybatis分页插件有进行limit优化吗
你用的哪一个插件 把包名版本号发出来
- 2019-04-28 1回答·1265浏览
-
 精慕门8459013
精慕门8459013
- 老师您好,有没有比较全的mysql视频。
那你估计得私信老师
- 2019-04-02 1回答·1210浏览
-
 计冉ran
计冉ran
- 老师的笔记和课件在哪呢
https://www.zam9.com/blog/mysql_opt01
这个是我在学习这个视频的适合整理的笔记,里面也提供了笔记文档的下载地址。
希望对你有用?
- 2019-03-01 1回答·1343浏览
-
 一代大神o_o
一代大神o_o
- 这个念 冗(rǒng)余,跟二傻子似的,还中雨,还小雪呢。。。
人家就是念成“chen",影响人家技术牛逼吗?
- 2019-02-18 5回答·1120浏览
-
 xc757036
xc757036
- 为什么我在mysql里show variables like 'show_query_log' 显示空集什么也没查出来?
show VARIABLES like 'slow_query_log'
- 2019-01-06 1回答·2013浏览
-
 阿笔
阿笔
- 如果只想对其他字段进行order by怎么处理?给其他字段加索引,也没用
sql中可以强制使用索引 force index 具体你百度一下就知道了
- 2018-12-22 1回答·1264浏览
-
 创泽
创泽
- 位置为题2
退出数据库登陆状态,然后再试试
- 2018-12-18 1回答·1068浏览





























