-
 慕标3152194
慕标3152194
- kaggle.json文件一直下载不成功
- 2025-12-31 0回答·105浏览
-
 慕仰6580405
慕仰6580405
- 像老师那样打出开头字母就有完整词提示是怎么设置的?
- 2025-12-28 0回答·78浏览
-
 慕仙3231720
慕仙3231720
- jupyter themes不显示
- 2025-11-27 0回答·70浏览
-
 梁志华180326_qrXZ12
梁志华180326_qrXZ12
- jupyter打开时报错
- 2025-03-31 0回答·168浏览
-
梁志华180326_qrXZ12
- jupyter打开后没有出现视频中的对话框
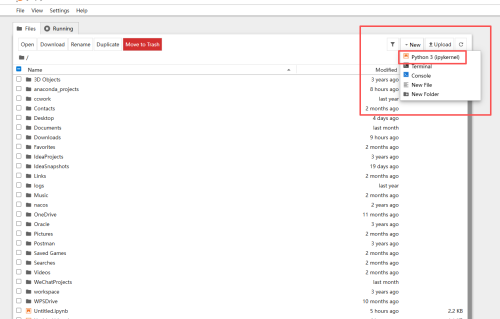
Home->New->Python3
- 2025-03-30 1回答·160浏览
-
 慕斯4571394
慕斯4571394
- 引入matplotlib之后 没有显示图片
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(k_range,score_train)
plt.xlabel('x')
plt.ylabel('y')
plt.show()
这样应该就行了
- 2025-01-06 1回答·196浏览
-
 史诗华_bkqE27
史诗华_bkqE27
- 关于fira字体问题
- 2024-12-14 0回答·127浏览
-
 慕移动9123849
慕移动9123849
- numpy安装版本有问题
已解决
- 2024-09-28 1回答·897浏览
-
 qq_星星_77
qq_星星_77
- from sklearn.metrics import accuracy_score
from sklearn.metrics import accuracy_score
- 2024-09-23 1回答·246浏览
-
 weixin_慕村2175486
weixin_慕村2175486
- 为什么我分离后的模型,添加新数据后的准确率更高了?
我也是,跟你结果一模一样,变高了!!!!???
- 2024-03-03 2回答·319浏览
-
 告别可乐827
告别可乐827
- 为什么我的新建环境没有新建python的功能,root环境可以
- 2023-12-22 0回答·304浏览
-
 hoofungson
hoofungson
- 在2-4的课程中自带函数分离训练数据集和测试数据集的划分标准是什么呢?原数据集中的哪些样本数据会划分到训练数据集、哪些样本数据会划分到测试数据集呢?
随机分配合理。
- 2023-11-06 1回答·309浏览
-
 攻占
攻占
- pandas用的是哪个版本的
- 2023-09-13 0回答·454浏览
-
 慕桂英4054809
慕桂英4054809
- logreg.fit(X_train,y_train) 报错了,这个是什么原因
- 2023-05-26 0回答·454浏览
-
 洲帅
洲帅
- 代码报错X = pima[feature_names],是咋回事
- 2023-05-11 0回答·484浏览
-
 Simcaxe
Simcaxe
-
 qq_慕雪8243059
qq_慕雪8243059
- 一个小问题
- 2022-09-29 0回答·410浏览
-
weixin_慕雪2228273
- k_score数值
- 2022-06-29 0回答·541浏览
-
weixin_慕哥4178428
- 数据集下不了,怎么办?
终于找到了,为了方便学习,网盘共享:
链接:https://pan.baidu.com/s/1EvpLWDOiQdMxb93Hs-sZAw
提取码:5pee
- 2022-04-24 1回答·568浏览
-
 慕慕6101011
慕慕6101011
- 请问我这里出现语法错误是怎么回事?
from,单词拼错了
- 2021-12-20 2回答·731浏览
-
慕慕6101011
- jupyter-themes(“ https://github.com/dunovank/jupyter-themes ”) 网页打不开
用这个
https://gitcode.net/mirrors/dunovank/jupyter-themes?utm_source=csdn_github_accelerator
- 2021-12-20 1回答·766浏览
-
weixin_慕数据4191184
- 老师,逻辑回归视频里没有啊
- 2021-12-17 0回答·554浏览
-
 Michelleqyh
Michelleqyh
- 请问本门课程有什么书可以参考吗?
这个,直接看python的书就可以了
- 2021-10-11 1回答·729浏览
-
Michelleqyh
- 课件PPT下载
没有PPT,但是可以截图,可以手动照抄。
- 2021-10-04 1回答·1120浏览
-
 qq_救赎_5
qq_救赎_5
- 模型结构打印不出来
最好把代码贴出来
- 2021-09-28 1回答·793浏览
-
weixin_慕勒1485912
- TN赋值不对
- 2021-09-02 0回答·722浏览
-
weixin_慕勒1485912
- 使用准确率评估之后结果是0.6770.。。
- 2021-09-02 0回答·747浏览
-
 慕姐0009277
慕姐0009277
- 关于anaconda的安装问题
把360关了安装,就可以了
- 2021-07-22 0回答·904浏览
-
 君莫笑写代码
君莫笑写代码
- mac安装不上这个jupyterthemes呢
这个是受系统不同的影响,可以借助三方的工具来解决
- 2021-07-13 1回答·826浏览
-
 慕桂英3086109
慕桂英3086109
- 输出结果方面
通常来说,数据是会被打散的,就是shuffle,而且划分数据的时候通常也是随机选取的,所以每次结果不一样是正常的。
- 2021-07-04 1回答·851浏览






















数据加载中...