-

- 霜花似雪 2022-11-09
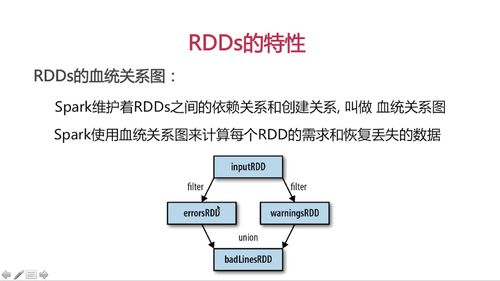
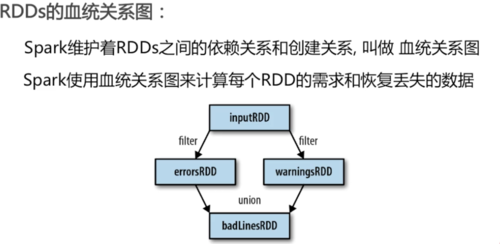
RDDs血统关系图
Spark维护着RDDs之间的依赖关系和创建关系,叫做 血统关系图
Spark使用血统关系图计算每个RDD的需求和恢复丢失的数据

dds的特性
延迟计算:
spark对rdds的计算是,他们第一次使用action操作的时候;
这种方式在处理大数据的时候特别有用,可以减少数据的传输;
spark内部记录metadata 表名tranformations操作已经被响应了;
加载数据也是延迟计算,数据只有在必要的时候,才会被加载进去。




- 0赞 · 0采集
-

- zrey 2022-03-25
RDDs血统关系图
Spark维护着RDDs之间的依赖关系和创建关系,叫做 血统关系图
Spark使用血统关系图计算每个RDD的需求和恢复丢失的数据
延迟计算( Lazy Evaluation)
在第一次使用Action操作时才进行计算, 减少数据传输
Spark内部记录metadat表明 transformation操作已经相应
RDD.persist() 持久操作
默认每次RDD进行action操作,会重新计算
persist()后可以重复利用一个RDD (缓存)
- 0赞 · 0采集
-

- 慕函数5144596 2021-09-28

RDDS的特性
- 0赞 · 0采集
-

- Jason_小杰 2021-08-28
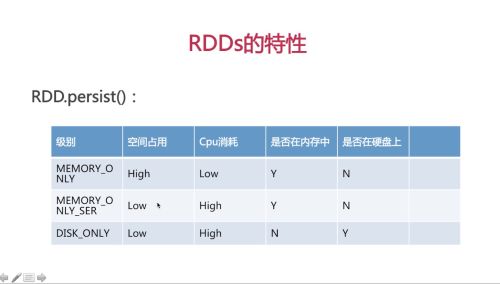
rdd缓存级别

- 0赞 · 0采集
-

- 慕粉1446071354 2020-05-24




RDDs的血统关系图
延迟计算
RDD.persist()
- 0赞 · 0采集
-

- 慕少7317271 2020-03-15
rdds的特性
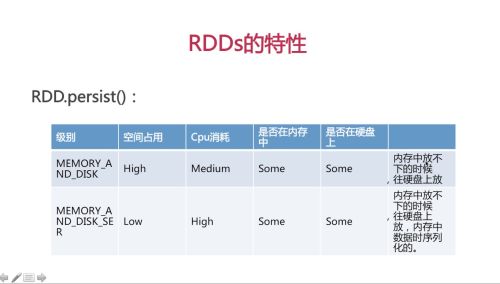
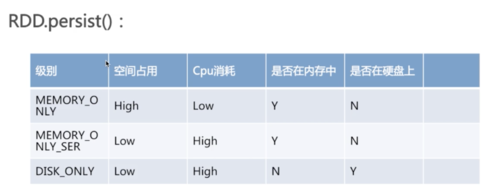
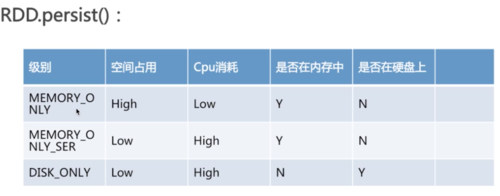
rdd.persist()可以传入一个级别,表示是否存在内存中或硬盘上,以及是否执行序列化操作等,级别不同,对应占用空间和cpu消耗情况是不一样的。
- 0赞 · 0采集
-

- APK 2019-09-01
RDDs的特性:
血统关系图,
延迟计算,
.persist()缓存
- 0赞 · 1采集
-

- xyx8888 2019-08-06
RDDs特性(5)
-
截图0赞 · 0采集
-
- xyx8888 2019-08-06
RDDs特性(4)
-
截图0赞 · 0采集
-
- xyx8888 2019-08-06
RDDs特性(3)
-
截图0赞 · 0采集
-
- xyx8888 2019-08-06
RDDs特性(2)
-
截图0赞 · 0采集
-
- xyx8888 2019-08-06
RDDs特性
-
截图0赞 · 0采集
-

- qq_离家近_0 2019-07-18
RDDs特性
1、血统关系图
2、延迟计算:只有对RDDs开始进行action操作时,才会加载RDDs(对大数据处理十分有效)
3、RDDs.presist(),重复利用RDDs时。(什么作用?)
- 0赞 · 0采集
-

- 慕UI6410761 2019-07-06
RDD持久化
-
截图0赞 · 0采集
-
- 慕UI6410761 2019-07-06
Rdds的延迟计算
-
截图0赞 · 0采集
-
- 慕UI6410761 2019-07-06
RDDs的特性
-
截图0赞 · 0采集
-

- 慕婉清5038615 2018-10-23
rdds的特性课程小结
rdds的血统关系图
延迟计算
rdd.persist()
-
截图0赞 · 0采集
-
- 慕婉清5038615 2018-10-23
rdds的特性
rdd.persist()可以传入一个级别,表示是否存在内存中或硬盘上,以及是否执行序列化操作等,级别不同,对应占用空间和cpu消耗情况是不一样的。
-
截图0赞 · 1采集
-
- 慕婉清5038615 2018-10-23
rdds的特性
rdd.persist()可以传入一个级别,表示是否存在内存中或硬盘上,以及是否执行序列化操作等,级别不同,对应占用空间和cpu消耗情况是不一样的。
-
截图0赞 · 0采集
-
- 慕婉清5038615 2018-10-23
rdds的特性
rdd.persist():
默认每次在rdds上面进行action操作时,spark都重新计算rdds
如果想重复利用一个rdd,可以使用rdd.persist()
unpersist()方法从缓存中移除;
例子--persist()
-
截图0赞 · 0采集
-
- 慕婉清5038615 2018-10-23
rdds的特性
延迟计算:
spark对rdds的计算是,他们第一次使用action操作的时候;
这种方式在处理大数据的时候特别有用,可以减少数据的传输;
spark内部记录metadata 表名tranformations操作已经被响应了;
加载数据也是延迟计算,数据只有在必要的时候,才会被加载进去。
-
截图0赞 · 0采集
-
- 慕婉清5038615 2018-10-23
rdds的特性
rdds的血统关系图:
spark维护着rdds之间的依赖关系和创建关系,叫做 血统关系图
spark使用血统关系图来计算每个rdd的需求和恢复丢失的数据。
-
截图0赞 · 0采集
-

- 慕粉3963940 2018-09-28

errorsRDD和waringsRDD都是inputRDD经过filter操作后生成的新的RDD,这两个RDD经过union操作后生成新的badLinesRDD,这样一步一步组成血统关系图
延迟计算
Spark对DDS的计算是在第一次使用action操作的时候才使用;
这种方式在处理大数据的时候特别有用,可以减少数据的传输(因为在第一次ation时才使用);
Spark内部记录metadata,表名transformations操作已经被响应了
加载数据也是延迟计算,数据只有在必要的时候,才会被加载进去(只有使用的时候才会被加载进去)
RDD.persist():
默认每次在RDDS上面进行action操作时,Spark都重新计算RDDS;
如果想重复利用一个RDDD,可以使用RDD.persist()(如还想使用上述union的BadLinesRDD会从inputRDD开始action一遍,RDD.persist则无需重复上诉过程)
unpersist()方法从缓存中移除;


- 0赞 · 2采集
-

- 扶摇三问 2018-08-11
- persist缓存级别补充
-
截图0赞 · 0采集
-
- 扶摇三问 2018-08-11
- persist缓存级别
-
截图0赞 · 0采集
-
- 扶摇三问 2018-08-11
- persist函数,使得可以重复利用rdd
-
截图0赞 · 0采集
-
- 扶摇三问 2018-08-11
- 延迟计算
-
截图0赞 · 0采集
-
- 扶摇三问 2018-08-11
- rdd血统关系图
-
截图0赞 · 0采集
-

- 慕的地522374 2018-05-15


缓存:

-
截图0赞 · 0采集
-




















 00:41
00:41