-

- UFO2015 2022-11-22
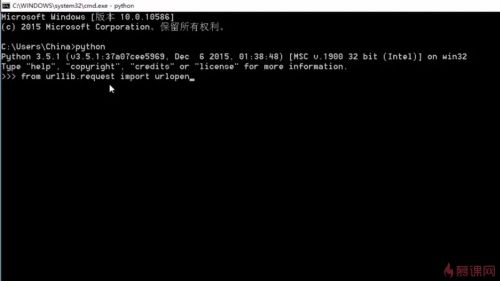
```py
$ which python
$ python --version
from urllib.request import urlopen
```
- 0赞 · 0采集
-
- UFO2015 2022-11-22
python data crawler

- 0赞 · 0采集
-

- 慕函数7431850 2022-02-05
- urllib
beautifulsoup - 0赞 · 0采集
-

- 慕九州1469150 2021-11-17
2

- 0赞 · 0采集
-
- 慕九州1469150 2021-11-17
1
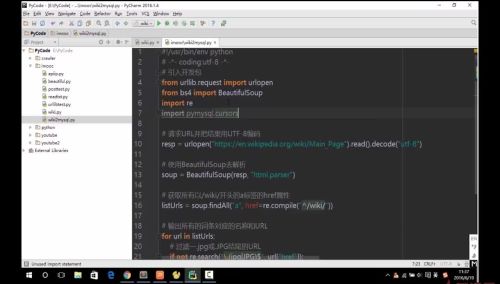
- 0赞 · 0采集
-
- 慕九州1469150 2021-11-17
2

- 0赞 · 0采集
-
- 慕九州1469150 2021-11-17

wiki
- 0赞 · 0采集
-

- akabla 2021-09-16
使用POST请求

- 0赞 · 0采集
-

- qq_主教练_0 2020-11-30
读取PDF文档
-
截图0赞 · 0采集
-

- 睿Rui 2020-07-18
urllib使用方法(3种)




- 0赞 · 0采集
-

- 精慕门6084420 2020-04-27
- Python
- 0赞 · 0采集
-
- 精慕门6084420 2020-04-27
- pathon
- 0赞 · 0采集
-
- 精慕门6084420 2020-04-27
- P
- 0赞 · 0采集
-

- ssssylvia_zhu 2020-02-21
#conding:utf-8 from urllib.request import urlopen html=uropen('http://en.wikipedia.org/robots.txt') print(himl.read().decode('utf-8'))-
截图0赞 · 0采集
-
- Foreverixhy 2019-11-02
beautiful soup
www.crummy.com/software/BeautifulSoup/#Download
查找修改树形结构,提供一些工具,可以解析文档
默认Unicode,utf-8
文档地址:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/#id4
- 0赞 · 0采集
-
- Foreverixhy 2019-10-29
使用post
-
截图0赞 · 0采集
-

- kingdompeak 2019-10-19
课程介绍:
-
截图0赞 · 0采集
-

- 慕仰2907144 2019-09-15
vim将多行代码前后移动一个tab的方法。 一、连续的十几行到50行内的左右移动: 1. 第m行到第n行右移一个tab :m,n> 2. 第m行到第n行左移一个tab :m,n< 二、连续的I行的左右移动(I > 100): 向左: 1.移动到要处理的首行,输入ma 2.移动到要处理的尾行,输入<'a 向右,即将第二个命令中的 '<' 改为 '>'即可。
- 0赞 · 0采集
-

- 霜花似雪 2019-09-14
课程总结5
-
截图0赞 · 0采集
-
- 霜花似雪 2019-09-14
课程总结4
-
截图0赞 · 0采集
-
- 霜花似雪 2019-09-14
课程总结3
-
截图0赞 · 0采集
-
- 霜花似雪 2019-09-14
课程总结1
-
截图0赞 · 0采集
-
- 霜花似雪 2019-09-14
课程总结2
-
截图0赞 · 0采集
-
- 霜花似雪 2019-09-14
爬虫 协议
-
截图0赞 · 0采集
-
- 霜花似雪 2019-09-14
# coding:utf-8
from pdfminer.pdfparser import PDFParser,PDFDocument
from pdfminer.pdfinterp import PDFResourceManager,PDFPageInterpreter
from pdfminer.pdfdevice import PDFDevice
from pdfminer.layout import LAParams
from pdfminer.converter import PDFPageAggregator
fp = open("1.pdf","rb") # 打开对象,使用二进制方式
parser = PDFParser(fp) # 创建对应的解释器,传入文件对象,可理解为解释文件
doc = PDFDocument() # 创建文档对象
parser.set_document(doc) # 两步方法将fp的解释器和doc文档关联起来
doc.set_parser(parser) # 两步方法将fp的解释器和doc文档关联起来
doc.initialize() # 关联了解释器的文档,进行初始化
resource = PDFResourceManager() # 创建pdf的资源管理器
laparams = LAParams() # 创建pdf的参数分析器
device = PDFPageAggregator(resource,laparams=laparams) # 使用聚合器将资源管理器和参数分析器聚合在一起
interpreter = PDFPageInterpreter(resource,device) # 创建页面解析器,将资源管理器和聚合其结合在一起
for page in doc.get_pages(): # 获取文档对象的每一页
interpreter.process_page(page) # 使用页面解析器解析每一页
layout = device.get_result() # 使用聚合其获取解析的结果
for out in layout: # 遍历获取的结果
print(out.get_text()) # 输出
- 0赞 · 0采集
-
- 霜花似雪 2019-09-14
Python读取PDF文档3
-
截图0赞 · 0采集
-
- 霜花似雪 2019-09-14
Python读取PDF文档2
-
截图0赞 · 0采集
-
- 霜花似雪 2019-09-14
python读取PDF文档
-
截图0赞 · 0采集
-
- 霜花似雪 2019-09-14
安装pdfminer3k 一般只安装了python3 安装使用语句 pip install pdfminer3k
-
截图0赞 · 0采集
-
- 霜花似雪 2019-09-14
python乱码原因
-
截图0赞 · 0采集












