-

- qq_羽悦_03291187 2023-12-17
Orc vs Parquet的区别

- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-12-17
列式存储优点
- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-12-17
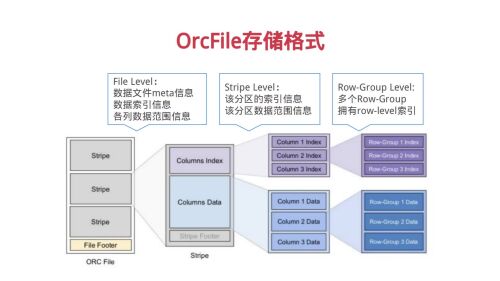
OrcFile存储格式
- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-12-17
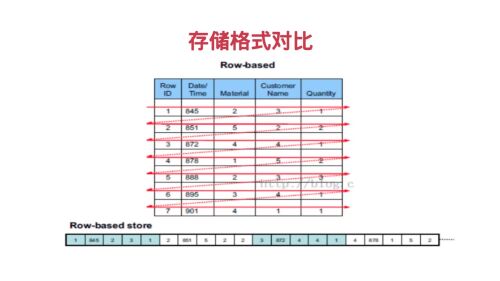
行式存储
- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-12-17
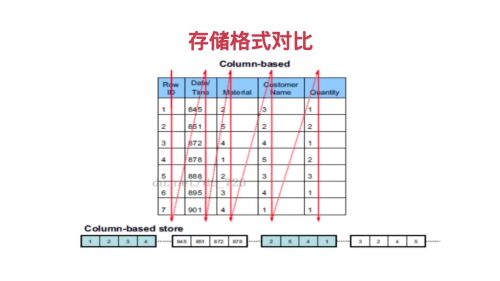
列式存储
- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-12-17
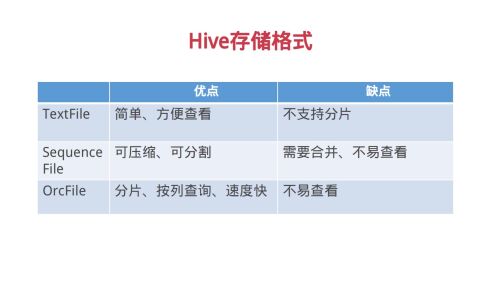
Hive存储格式
- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-12-17
alter table table1 drop partition(year=2019) 删除指定分区表

- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-12-17
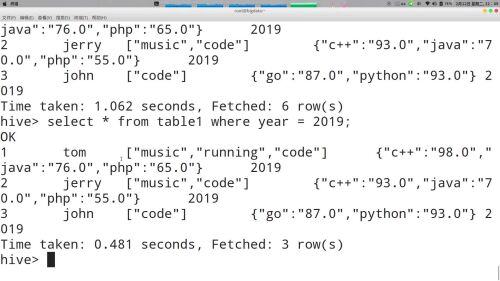
检索固定分区表,需加上分区字段
- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-12-17
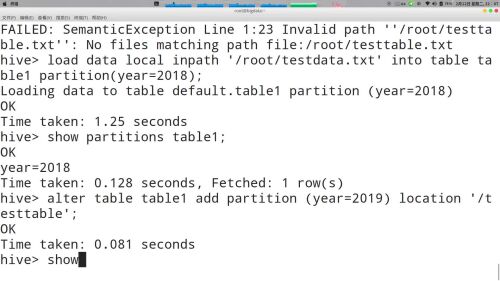
加载数据到分区表的两种方式
- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-12-17
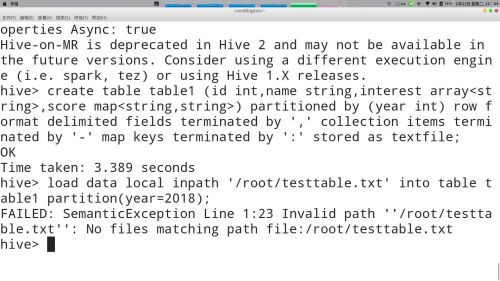
创建分区表"create external table tables(字段、...) partitioned by(字段)"
分区是为了缩小查询范围、减少查询时间、提升查询效率
- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-12-17
内部表和外部表的区别
内部表:删除表,元数据被删掉,文件不存在
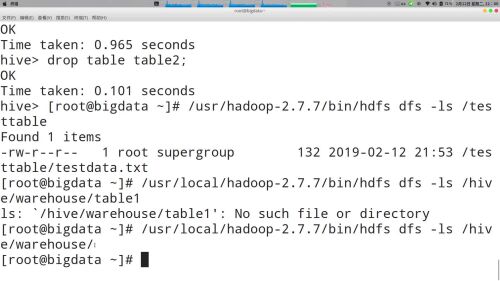
外部表:删除表,元数据被删掉,文件还存在
- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-12-17
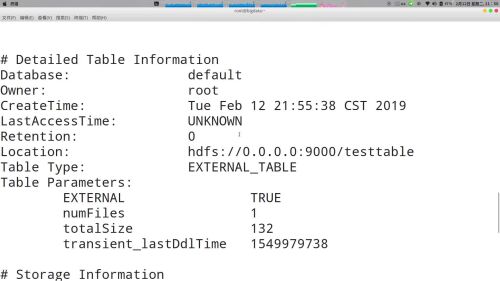
desc formatted table2 查看table2的相关信息
- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-12-17
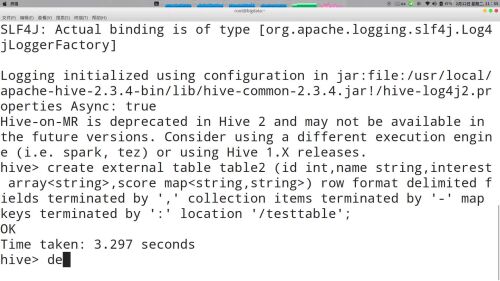
创建外部表语句“create external table tables()"
- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-12-17
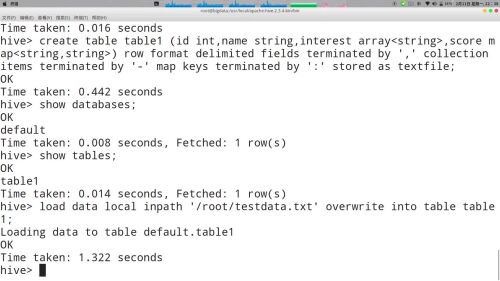
load加载".txt"文件数据到表“table1”
- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-12-17
HIVE建表结构
- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-12-10
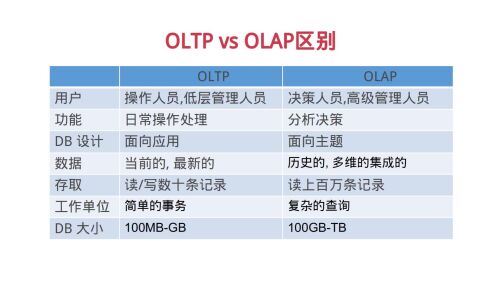
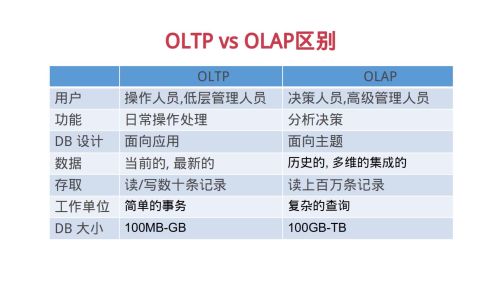
OLTP与OLAP的区别
- 0赞 · 0采集
-

- 筑梦之路 2023-08-11
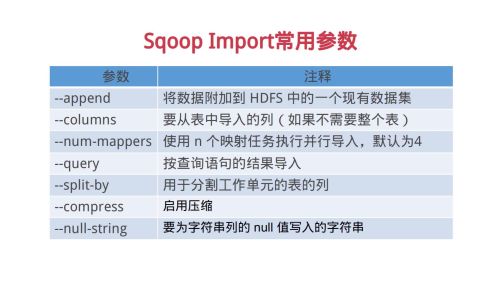 sqoop inport常用参数
sqoop inport常用参数- 0赞 · 0采集
-

- cloverwang 2023-07-08

Presto是MPP架构,跨数据源查询
- 0赞 · 0采集
-
- cloverwang 2023-07-08
支持JDBC的关系型数据库基本都可以使用Sqoop导入数据

- 0赞 · 0采集
-
- cloverwang 2023-07-08

Presto是Facebook为了解决Hive问题所开发的
PB级数据快速交互式查询
- 0赞 · 0采集
-

- 老头子马龙 2023-05-12
常用数据采集框架:DataX Gonlbblin Flume

- 0赞 · 0采集
-
- 老头子马龙 2023-05-08
数据采集系统的基本需求

- 0赞 · 0采集
-

- geniusmorn 2022-11-08


笔记测试二
- 0赞 · 0采集
-
- geniusmorn 2022-11-08



笔记测试111
- 0赞 · 0采集
-

- qq_秋雨_4 2022-05-09
presto,impala
- 0赞 · 0采集
-

- zrey 2022-03-31
Hive: 基于hadoop的数据仓库, 提供类sql语法
Hive将数据映射成数据库和一张张的表,库和表的元数据信息一般存在外部关系型数据库。 以MR计算引擎,HDFS存储系统,提供超大数据集计算扩展能力。Hive的库和表是对HDFS上数据的映射。
Hive语句执行过程将Hive sql转换为MapReduce任务执行
数据仓库:数据源的数据经过ETL处理后,按照一定的主题集成起来提供决策支持和联机分析应用的结构化数据环境。
ETL: Extract, Transform, Load
Sqoop输入 Presto查询输出
联机事务处理OLTP是传统关系型数据库
联机分析处理OLAP是数据仓库应用
- 0赞 · 0采集
-

- qq_慕桂英4511000 2021-12-22
有动态添加catalog代码吗?
- 0赞 · 0采集
-

- 慕粉2096223 2020-11-26
列式存储的优势和劣势:
优势:当我们查询语句只涉及部分列的时候,只需要扫描相关列即可,不需要扫描整个的数据文件,同一列数据格式是相同的,彼此相关性更大,对于列数据的压缩效率更大,可以针对每一列的数据选择不同的数据压缩方式。
劣势:对一条数据写入更新时需要更改多个列。
数据仓库面临的主要需求是查询分析,对于更新不是特别频繁,所以数据仓库是适合使用列式存储的,同时OLAP一般是构建在分布式存储上的,受分布式文件存储特性的影响,需要快速读取,就要按块分片进行读取,修改写入都是追加写入,而非随机读写。
- 0赞 · 1采集
-
- 慕粉2096223 2020-11-26
基于Hadoop开源数据框架工具Hive,本质上是将HDFS上的数据映射成数据库、数据表等元数据,然后再对这些文件进行检索查询。
- 0赞 · 0采集
-

- qq_慕后端80451 2020-10-29



acid:事务
事务具有4个特征,分别是原子性、一致性、隔离性和持久性,简称事务的ACID特性;
一、原子性(atomicity)
一个事务要么全部提交成功,要么全部失败回滚,不能只执行其中的一部分操作,这就是事务的原子性
二、一致性(consistency)
事务的执行不能破坏数据库数据的完整性和一致性,一个事务在执行之前和执行之后,数据库都必须处于一致性状态。
如果数据库系统在运行过程中发生故障,有些事务尚未完成就被迫中断,这些未完成的事务对数据库所作的修改有一部分已写入物理数据库,这是数据库就处于一种不正确的状态,也就是不一致的状态
三、隔离性(isolation)
事务的隔离性是指在并发环境中,并发的事务时相互隔离的,一个事务的执行不能不被其他事务干扰。不同的事务并发操作相同的数据时,每个事务都有各自完成的数据空间,即一个事务内部的操作及使用的数据对其他并发事务时隔离的,并发执行的各个事务之间不能相互干扰。
在标准SQL规范中,定义了4个事务隔离级别,不同的隔离级别对事务的处理不同,分别是:未授权读取,授权读取,可重复读取和串行化
1、读未提交(Read Uncommited),该隔离级别允许脏读取,其隔离级别最低;比如事务A和事务B同时进行,事务A在整个执行阶段,会将某数据的值从1开始一直加到10,然后进行事务提交,此时,事务B能够看到这个数据项在事务A操作过程中的所有中间值(如1变成2,2变成3等),而对这一系列的中间值的读取就是未授权读取
2、授权读取也称为已提交读(Read Commited),授权读取只允许获取已经提交的数据。比如事务A和事务B同时进行,事务A进行+1操作,此时,事务B无法看到这个数据项在事务A操作过程中的所有中间值,只能看到最终的10。另外,如果说有一个事务C,和事务A进行非常类似的操作,只是事务C是将数据项从10加到20,此时事务B也同样可以读取到20,即授权读取允许不可重复读取。
3、可重复读(Repeatable Read)
就是保证在事务处理过程中,多次读取同一个数据时,其值都和事务开始时刻是一致的,因此该事务级别禁止不可重复读取和脏读取,但是有可能出现幻影数据。所谓幻影数据,就是指同样的事务操作,在前后两个时间段内执行对同一个数据项的读取,可能出现不一致的结果。在上面的例子中,可重复读取隔离级别能够保证事务B在第一次事务操作过程中,始终对数据项读取到1,但是在下一次事务操作中,即使事务B(注意,事务名字虽然相同,但是指的是另一个事务操作)采用同样的查询方式,就可能读取到10或20;
4、串行化
是最严格的事务隔离级别,它要求所有事务被串行执行,即事务只能一个接一个的进行处理,不能并发执行。
四、持久性(durability)
一旦事务提交,那么它对数据库中的对应数据的状态的变更就会永久保存到数据库中。--即使发生系统崩溃或机器宕机等故障,只要数据库能够重新启动,那么一定能够将其恢复到事务成功结束的状态
- 1赞 · 1采集









