-

- 擎宇40689 2022-06-18
试下
拒绝
- 0赞 · 0采集
-

- zrey 2022-04-14
import re #导入re模块
生成pattern对象:pa = re.compile(r'imooc') #匹配的字符
生成match对象:ma = pa.match('imooc.com') #被匹配的字符
ma.group() ==>imooc #返回匹配的字符
ma.span() ==>(0,5) #被匹配字符串所在索引位置
ma.string() ==>'imooc.com' #返回被匹配字符串

- 0赞 · 0采集
-
- zrey 2022-04-14
正则表达式的作用:
使用单个字符串来描述匹配一系列符合其语法规则的字符串
是对字符串操作的一种逻辑公式
处理文本和数据
正则表达式过程:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功、否则匹配失败。
- 0赞 · 0采集
-

- 明天就暴富 2021-12-22
2、

- 0赞 · 0采集
-
- 明天就暴富 2021-12-22
2
- 0赞 · 0采集
-

- Ricoor 2021-06-30


11
- 0赞 · 0采集
-
- Ricoor 2021-06-30
正则表达式概念
使用单个字符串来描述匹配一系列符合某个语法规则的字符串
是对字符串操作的一种逻辑公式
处理文本和数据
依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;否则匹配失败
- 0赞 · 0采集
-

- 慕斯卡0601670 2021-03-20
pa=re.compile(r'imooc',re.I)#re.I意为ignore,不区分大小写
- 0赞 · 0采集
-
- 慕斯卡0601670 2021-03-20
#python正则表达式 #1:import re:python 正则表达式模块 #2:第一个正则表达式 [object Object] str1='imooc python' #非正则方法 str1.find('11')#==>-1没找到 str1.find('imooc')#==>0 str1.startswith('imooc')#==>True #正则方法 import re#导入re模块 pa = re.compile(r'imooc')#生成pattern对象,括号中是正则表达式,前加r表示原字符串 type(pa)#==>_sre.SRE_Pattern#生成实例 pa.match(str1)#==><_sre.SRE_Match at 0x7f6e2115f370>返回了一个match的对象地址 ma = pa.match(str1)#使用一个变量接收 ma.span()#查看在原字符串的位置 #查找以下划线开头 import re pa1=re.compile(r'_') ma1=pa1.match('_value') mal.group()- 0赞 · 0采集
-
- 慕斯卡0601670 2021-03-20
#课程内容
#1:正则表达式基本概念
#2:python正则表达式re模块
#3:正则表达式语法
#4:re模块相关方法使用#1-1正则简介
#为什么使用正则?
#疑问:字符串匹配就可以实现?
#场景1:在imooc.txt中找到以'imooc'开头的行
def find_start_imooc(f_name):
f=open(f_name)
for line in f:
if line.startswith('imooc'):
print line
#find_start_imooc('imooc.txt')
#场景2:在imooc.txt中找到以'imooc'开头且以'imooc'结尾的行
def find_in_imooc(f_name):
f=open(f_name)
for line in f:
if line.startswith('imooc') and line.endswith('imooc\n'):
#if line.startswith('imooc') and line[:-1].endswith('imooc'):
print line
#abcd = s[0:4] 切片:取字符串s中的第一个字符到第五个字
#python每行以/n结尾,line[:-1]切片去掉最后一个/n
#find_start_imooc('imooc.txt')
#场景3:匹配一个下划线和字母开头的变量名
a='_value1'
a and (a[0]=='_' or 'a'<=a[0]<='z')#True
a='1_value1'
a and (a[0]=='_' or 'a'<=a[0]<='z')#False
#疑问:每一次匹配都要单独完成,能否把它抽象出来做成一个规则?
#正则表达式概念
#1:使用单个字符串来描述匹配一系列符合某个句法规则的字符串
#2:是对字符串操作的一种逻辑公式
#3:应用场景:处理文本和数据
#4:正则表达式过程:依次拿出表达式和文本中的字符比较
#如果每一个字符都能匹配,则匹配成功;否则匹配失败-
截图0赞 · 0采集
-

- qq_天际的光与影 2021-02-26
语法结构清晰
- 0赞 · 0采集
-

- 未知数Unknown 2021-02-04
正则表达式 概念
-
截图0赞 · 0采集
-

- 慕仰6556596 2021-01-06
正则表达式
-
截图0赞 · 0采集
-

- qq_慕移动6432862 2020-09-20
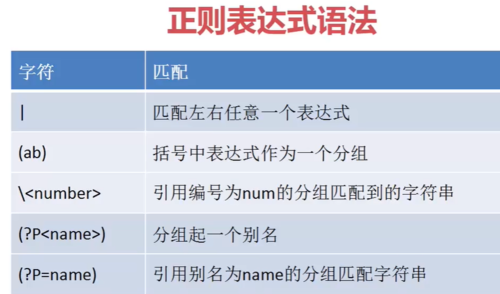
正则表达式语法--分组匹配
- 0赞 · 0采集
-
- qq_慕移动6432862 2020-09-20
正则表达式语法--边界匹配

- 0赞 · 0采集
-
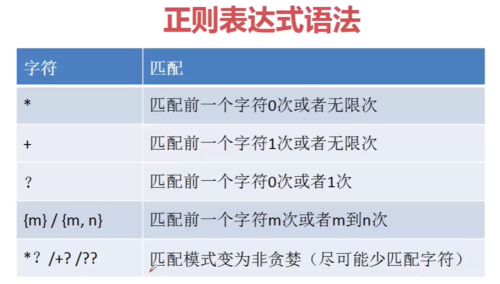
- qq_慕移动6432862 2020-09-20
正则表达式语法--单个字符匹配
- 0赞 · 0采集
-

- chand 2020-09-20
*?、+?、??的讲解
-
截图0赞 · 0采集
-
- chand 2020-09-20
\w和\W的讲解部分
-
截图0赞 · 0采集
-
- chand 2020-09-20
正则表达式的基本语法
-
截图0赞 · 0采集
-
- chand 2020-09-20
#*对前一个字符匹配0次或无限次 ma = re.match(r'[A-Z][a-z]', 'Aa') ma.group() ma = re.match(r'[A-Z][a-z]', 'A') ma.group() ma = re.match(r'[A-Z][a-z]*', 'A') ma ma.group() ma = re.match(r'[A-Z][a-z]', 'Adsdshdhhdh') ma.group()
-
截图0赞 · 0采集
-

- 人工智能小小白 2020-06-27
r'<([\w]+>)[\w]+</\1' 小括号中作为一个分组,中间的[\w]+表示匹配一个或多个数字字母 下划线
<\表示HTML中的标签结尾,\1表示再次使用小括号中的匹配内容在匹配一次
-
截图1赞 · 0采集
-

- 慕移动3109107 2020-06-18
- re.compile match从头开始匹配
-
截图0赞 · 0采集
-

- 慕函数2106304 2020-05-30
- 基础知识特别有帮助
- 0赞 · 0采集
-

- shurima阿慕慕 2020-05-22
ma=re.match(r'[_A-Za-z]+[_\w]*','str')=>用加号进行表达式拼接
*?:非贪婪模式,尽量匹配0次
+?:非贪婪模式,尽量匹配1次
??:非贪婪模式,尽量匹配0次
- 0赞 · 0采集
-
- shurima阿慕慕 2020-05-16
match = re.compile(r'\[[\w]\]', '[a]')
↑通过转义符保证匹配到:置于中括号内的字符
- 0赞 · 0采集
-
- shurima阿慕慕 2020-05-16
reg = re.compile(r'xx', re.I) , flag(re.I)的作用是忽略大小写
- 0赞 · 0采集
-
- shurima阿慕慕 2020-05-16
正则表达式流程:pattern=>re.compile(r'xxx'), match=>pa.match('str')
python自身匹配方法: str.find('xx')/startswith('xx') <=bool
pa.match方法返回Match对象,现实对象内容使用match.group()
其他方法:match.span()匹配对象跨度/string匹配字符串/re表达式实例
- 0赞 · 0采集
-
- Fighting_大叔 2020-04-06
Python 3 代码,获取图片不在是src开头,另外图片结尾有jpg和npg。特别是下载重命名时不能都命名为jpg格式。
# get html req = urllib.request.urlopen('https://www.imooc.com/course/list') buf_html = req.read().decode('utf-8') images_tmp = re.findall(r'data-original=.*(?:jpg|png)', buf_html) #get image url list img_urls = [] for ins in images_tmp: t = re.split(r'//', ins) img_urls.append('http://' + t[1]) i = 1 for url in img_urls: fileName = open(str(i) + '.' + re.split(r'\.', url)[-1], 'wb') req1 = urllib.request.urlopen(url) buf_image = req1.read() fileName.write(buf_image) i += 1- 1赞 · 0采集
-

- 谢谢你好 2020-03-25
正则表达式
-
截图0赞 · 0采集
-

- 猛男落泪衣 2020-03-20
'正则表达式语法' # 匹配的字符串也有[]时,需要转义,如r'\[[\w]\]' # 字符匹配 # . 匹配\n除外的任意字符 # [...] 匹配字符集,如[a-zA-Z0-9] # [\d]/[\D] 匹配数字/非数字 # [\s]/[\S] 匹配空白/非空白 # [\w]/[\W] 匹配单词字符[a-zA-Z0-9]/非单词字符 # 多次匹配 # * 匹配前一个字符0次或无限次,如r'[A-Z][a-z]*'可以匹配前面大写后面小写的任意个字符 # + 匹配前一个字符1次或无限次,如r'[_a-zA-Z]+[_\w]'匹配下划线或字母开头的字符,即匹配有效变量 # ? 匹配前一个字符0次或1次,[1-9]?[0-9]匹配有效的两位数 # {m}/{m,n} 匹配前一个字符m次或者n次,如r'[a-zA-Z0-9]{6,10}@163.com'匹配6-10个字符的邮箱帐号,即匹配指定次数的的字符 # *?/+?/?? 匹配模式变为非贪婪,即尽可能少匹配字符,r'[A-Z][a-z]*?只匹配符合的0次 # 边界匹配,强匹配 # ^ 匹配字符串开头如,r'^[\w]{4,10}@163.com$'匹配以任意4-10个有效字符开头,与@163.com结尾的字符 # $ 匹配字符串结尾 # \A/\Z 指定的字符串必须出现在开头或结尾 # 分组匹配 # | 匹配左右任意一个表达式 # (ab) 括号中表达式作为一个分组 # \<number> 引用编号为num的分组匹配到的字符串 # (?P<name>) 分组起一个别名 # (?P=name) 引用别名为name的分组匹配字符串- 0赞 · 0采集

















