-

- 大白小白i 2021-09-25
第4章 重要函数的使用
4-1 R语言函数 lapply
处理循环:R不仅有for/while循环语句(特点:需要些多行代码),还有更强大的实现循环的“一句话”函数。
排序
总结数据信息
lapply:可以循环处理列表中的每一个元素
lapply(参数):lapply(列表,函数/函数名,其他参数)
结果:总是返回一个列表
例:1.str(lapply)(其作用是把任意的R对象以一种整洁紧凑的形式显示出来)
x<-list(a=1:10,b=c(11,21,31,41,51))
lapply(x,mean)
2.x<-1:4(在lapply内部,会强制转化为列表)
lapply(x,runif)(从均匀分布的总体里抽取若干个数,默认从0到1之间抽取)
lapply(x,runif,min=0,max=100)(从0到100之间抽取)
3.x<-list(a=matrix(1:6,2,3)),b=matrix(4:7,2,2)
lapply(x,function(m)m[1,])(m为匿名函数,对x中的每一个矩阵都取出它第1行的元素)
sapply:与lapply非常相似,它可以在允许的情况下对lapply的结果进行化简。结果列表元素长度均为1,返回向量;结果列表长度相同且大于1,返回矩阵;其他情况与lapply相同。
例: x<-list(a=1:10,b=c(11,21,31,41,51))
lapply(x,mean)
sapply(x,mean)
- 0赞 · 0采集
-

- weixin_慕容1489917 2020-02-24
R语言函数lapply
可以循环处理列表中的每一个元素
lapply(参数):lapply(列表,函数/函数名,其他参数)
总是返回一个列表
sapply:简化结果
结果列表元素长度均为1,返回向量
结果列表元素长度相同且大于1,返回矩阵
lapply(x,mean) #求列表x的平均值
lapply(x,runif ) #runif 从一个均匀分布的总体中抽取若干个数出来,默
认为(0,1)区间
lapply(x,runif,min=0,max=100 ) #抽取的范围是0-100
x <- list(a=matrix(1:6,2,3),b=matrix(4:7,2,2))
lapply(x,function(m),m[1,])#function代表一个函数,m表示传入的参数是矩阵
- 0赞 · 0采集
-

- 慕粉2206434494 2019-12-25
重要函数的使用
#lapply
str() ---------把任意的R对象的使用标准展示出来


eunif ----- 从一个均匀分布的整体里抽取若干个数出来
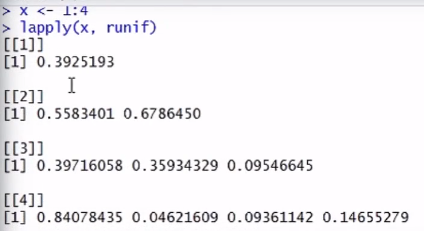
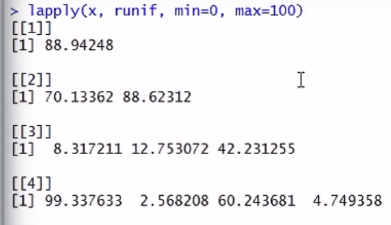
runif 默认的取数区间是0-1,但是当对min和max进行设置以后,取数区间变成了0-100
建一个匿名函数---function(m) ---m是函数要传入的参数


#sapply
sapply可以对lapply的结果进行化简,如果能化解则化简,不能化简则和lapply的结果一致



- 0赞 · 0采集
-
- 慕粉2206434494 2019-12-25
重要函数的使用
-
截图0赞 · 0采集
-
- 慕粉2206434494 2019-12-25
重要函数的使用
-
截图0赞 · 0采集
-

- 慕慕0584863 2019-12-11
sapply()输出的结果更为简化
-
截图0赞 · 0采集
-
- 慕慕0584863 2019-12-11
runif从均匀分布的总体里抽出若干个数,默认从0-1开始抽取,
在lapply内部,强制转化为列表(在后面可以设第三个第四个参数,设置抽取范围)
-
截图0赞 · 0采集
-
- 慕慕0584863 2019-12-11
str()函数是将任意R对象以简单,紧凑的形式展现出来
function()表示这是一个函数(X,FUN,...) (X表示列表)
-
截图0赞 · 0采集
-
- 慕慕0584863 2019-12-11
一句话函数
-
截图0赞 · 0采集
-
- 慕慕0584863 2019-12-11
重要函数的使用
-
截图0赞 · 0采集
-

- qq_慕沐0585126 2019-08-10
function()代表匿名函数
sapply()能把lappy的结果进行化解,例如把列表化解成向量,使结果更加清晰:1)当结果列表元素长度均为1 ,返回向量;2)当长度相同且大于1,返回矩阵。反之,返回结果和lapply一样
-
截图0赞 · 0采集
-
- qq_慕沐0585126 2019-08-10
循环函数:for/while()语句(需要多行代码),此外还有“一句话”函数(一行代码即可)
lapply(参数):可以循环处理列表中的每一个元素,参数可以是列表,函数名等,其结果总是返回一个列表
求平均mean(),runif()代表从一个均匀分布的总体里抽取若干个数出来,该函数默认从0到1进行抽取
-
截图0赞 · 0采集
-

- 慕先生2438196 2019-08-06
#lapply
str(lapply)#str()函数是使得任意的R函数以一种简介紧凑的形式显示出来
x <- list(a = 1:10,b = c(11,23,45,67,32,12))
lapply(x,mean)#求x列表中a和b元素的平均值
x1 <- 1:4
lapply(x1,runif)#runif函数作用是:从一个均匀分布的总体里抽取若干个数出来,默认从0-1之间抽取
lapply(x1,runif,min=0,max=100)#可以自助设置取值区间,虽然x1是向量,但是返回值默认是列表
x2 <-list(a = matrix(1:6,3,2), b =matrix(4:9,2,3))
lapply(x2,function(m) m[1,])#使用lapply函数时,参数格式一定要书写正确。本例抽取了列表中两个矩阵的第一行
#sapply,在lapply的结果能够简化的情况下对其进行简化,若不能简化则输出结果与lapply一样
x <- list(a = 1:10,b = c(11,23,45,67,32,12))
lapply(x,mean)
sapply(x,mean)
class(sapply(x,mean))#查看其类型属于数值型
#apply
y <-array(rnorm(2*3*4),c(2,3,4))
y
apply(y, c(1,2),mean)#对不同维度上的行和列求均值
apply(y, c(1,3),mean)#把不同列上的维度和列求均值
apply(y, c(2,3),mean)#把不同行上的列和维度求均值
#mapply
list(rep(1,4),rep(2,3),rep(3,2),rep(4,1))#与下面的函数运动结果一样
mapply(rep,1:4,4:1)#作用就是用rep函数,把1-4之间的数分别重复4-1遍
#写一个自己的函数:抽取正态分布中标准差(std)一定、均值(mean)一定的若干个数(n)的值
s <- function(n,mean,std){
rnorm(n,mean,std)
}#写完函数要先运行一下才能被调用
s(4,0,1)#抽取4个均值为0标准差为1的数
mapply(s,1:5,5:1,2)#传入s函数名,抽取1-5个值,均值分别为5-1,标准差为2
#tapply
x <-c(rnorm(5),runif(5),rnorm(5,1))#创建包含15个元素的向量,前五个是正态分布的5个,中间是均匀分布的5个元素,最后是标准差为1,标准差为0的正态分布
x
f <- gl(3,5)#gl函数后的参数说明:选取3个水平,每个水平下有5个元素
f
tapply(x, f, mean)#参数的含义就是:对x这个向量,按照f的水平进行分组,对每一组求均值
#split
split(x,f)#把x按照f水平进行划分
lapply(split(x,f),mean)#对划分后的数据求均值
head(airquality)
s <- split(airquality,airquality$Month)#查找airquality包中的月份数据,并传入s中
table(airquality$Month)#查找month的信息,以及每一月包含的记录数
lapply(s, function(x) colMeans(x[,c("Ozone","Wind","Temp")]))#计算x中Ozone、Wind、Temp三列的均值
sapply(s, function(x) colMeans(x[,c("Ozone","Wind","Temp")]))#sapply可以简化结果
#sapply虽然简化了结果,但是结果中包含缺失值,在Ozone中存在缺失值,所以运算时无法刨除,也就无法计算出正确的均值
#加上"na.rm = TRUE",就能解决存在缺失值的问题
sapply(s, function(x) colMeans(x[,c("Ozone","Wind","Temp")],na.rm = TRUE))
#排序
x1 <- data.frame(v1=1:5, v2 =c(10,5,2,8,63), v3=11:15, v4 =c(1,1,2,4,5))
x1
sort(x1$v2)#升序排列
sort(x1$v2, decreasing = TRUE)#降序排列
order(x1$v2)#返回的是第二列排序后的下标序号
x1[order(x1$v2),]#可以把所有数据按照第二列升序后的顺序进行相应的重新排列
x1[order(x1$v4,x1$v2),]#先按照v1进行排序(升序),遇到相同值时就用v2进行排序
x1[order(x1$v4,x1$v2,decreasing = TRUE),]#也可直接按降序排列
- 0赞 · 0采集
-

- 慕勒4424536 2019-07-29
lapply(列表,函数/函数名,其他参数), 可以循环处理列表中每一个元素,总是返回一个列表,如果传入的第一个元素不是列表,会自动强制转化为列表;
str()函数用于把任意R对象以简洁的形式显示;
自己创建函数lapply(x, function(m) m[1, ]);
sapply()化简结果:如果结果列表元素长度均为1,返回向量;如果结果元素长度相同且大于1,返回矩阵;若结果元素长度不同无法化简;
- 0赞 · 0采集
-

- My_My_My 2019-06-13
sapply():简化lapply()结果,不再返回列表,而是返回向量和矩阵
- 0赞 · 0采集
-
- My_My_My 2019-06-13
lapply() 循环处理列表中的每一个元素
- 0赞 · 0采集
-

- AYLM暗夜联盟 2019-03-20
lapply函数可以处理循环列表中的没一个元素,但是返回了是一个列表
注意,如果传入lapply函数的不是一个列表,那么他将进行强制转换为列表
slapply函数返回结果是一个数值型的
mean函数是求平均的
服从均匀分布的随机数
runif(n, min = 0, max = 1)
生成一个长度为10的向量,向量中的每个值服从0~1区间上的均匀分布,那么可以这样写
- 1赞 · 0采集
-

- 小调皮3586 2019-01-18
lapply(x,runif)
//对数据进行随机抽取
常与匿名函数结合使用
lapply(x,function(m) m[1,])
//讲x依次传入function中,并抽取第一行
sapply(x,mean)//简化结果,当列表元素长度均为1,返回向量;列表元素长度相同且大于1,返回矩阵
- 1赞 · 0采集
-

- 慕勒0443662 2018-10-28
runif: 从一个均匀分布的整体抽出若干个数,默认 从0到1之间抽取,如果主动设置区间会从相应区间抽取
lapply(x, functon(m) m[1,]),第二三项之间没有逗号
sapply:更简化,长度相同把列表简化为向量或矩阵,不相同依旧转化为列表
- 0赞 · 0采集
-

- 杜仲先生 2018-10-11
#lapply的应用 x<-list(a=1:10,b=c(11,21,31,41,51)) lapply(x,mean)#将返回一个列表,内容为列表x中单个元素的平均值(函数起到循环作用) x<-1:4 lapply(x,runif)#从均匀分布的总体中抽取若干个数出来 lapply(x,runif,min=0,max=100)#runif的默认区间为0-1;设定了min和max,更改了runif的区间为1-100 x<-list(a=matrix(1:6,2,3),b=matrix(4:7,2,2)) lapply(x,function(m)m[1,])#取出矩阵x中两个元素中第一行的元素 #sapply x<-list(a=1:10,b=c(11,21,31,41,51)) lapply(x,mean) sapply(x,mean)#简化lapply的数据,也起循环的作用 class(lapply(x,mean))#返回列表 class(sapply(x,mean))#返回数值 #sapply:简化结果 结果列表元素长度均为1,返回向量; 长度相同且大于1,返回矩阵。
- 1赞 · 1采集
-

- 慕粉2207325809 2018-09-13
循环函数
lapply:可以循环处理列表中每一个元素
lapply(列表,函数/函数名,其他参数)
x<-list(a=c(1:10)), b=c(11,21,31,41,51))
lapply(x, mean)
x2<-1:4 #创建一个向量x2
lapply( x2, runif ) #runif函数(r + unif):从一个均匀分布的整体里,抽取若干个数出来
R语言生成均匀分布随机数的函数是runif()
句法是:runif(n,min=0,max=1) n表示生成的随机数数量,min表示均匀分布的下限,max表示均匀分布的上限;若省略参数min、max,则默认生成[0,1]上的均匀分布随机数。
lapply(x2, runif,min=0,max=100)
x3<-list(a=matrix(1:6,2,3), b=matrix(4:7),2,2 )
lapply(x3, function(m) m[1, ])
#函数function返回x3中每个矩阵的第一行
#sapply函数 能够化简lapply
x返回值从列表简化成向量,并不影响理解
- 0赞 · 0采集
-

- imblackhat 2018-06-30
处理循环:R中不仅有for/while循环语句,还有“一句话”函数。
排序
总结数据信息
lapply:可以循环处理列表中的每一个元素。
lapply(列表,函数/函数名,其他参数),返回值总是一个列表。
lapply(x,mean) #对x中的元素求平均,若x不是列表,会被强制转换为列表
lapply(x,runif) #从均匀分布的总体里抽取元素数值个0-1的随机数
lapply(x,runif,min=0,max=100) #抽取出大于0小于100的随机数 min、max作为runif的参数传入
函数可以自定义,即匿名函数形式: function(参数) 操作
注意:传进来的参数是列表中的每个元素(是下一级的)。
sapply与lapply操作相同,但是是对lapply进行简化,若结果列表中元素个数均为1,返回numeric向量;若结果列表元素个数相同且大于1,返回矩阵。
str()参数为R对象,将其以一种整洁紧凑的形式显示出来。可以用来函数对象需要哪些参数
-
截图1赞 · 0采集
-

- qiaodeqi 2018-05-19
如果不是列表,会自动转化为列表
-
截图0赞 · 0采集
-
- qiaodeqi 2018-05-19
R中可以一句话而避免for和while多行
-
截图0赞 · 0采集
-

- 肖涵99 2018-04-03
lapply:循环列表中的每一个元素
- 0赞 · 0采集
-

- 爱茉莉的猪 2018-03-19
- 重要函数的使用:lapply,sapply
-
截图0赞 · 0采集
-
- 爱茉莉的猪 2018-03-19
- 重要函数使用
-
截图0赞 · 0采集
-

- 慕粉15156365919 2017-12-05
- sapply 对 lapply 的结果化简
-
截图0赞 · 0采集
-
- 慕粉15156365919 2017-11-30
- 对列表的循环操作
-
截图0赞 · 0采集
-

- 慕婉清0107024 2017-11-27
- lapply
-
截图0赞 · 0采集


















