-

- 慕勒242594 2024-09-13
如何处理缺失值
- 0赞 · 0采集
-

- 大白小白i 2021-09-24
3-5处理缺失值
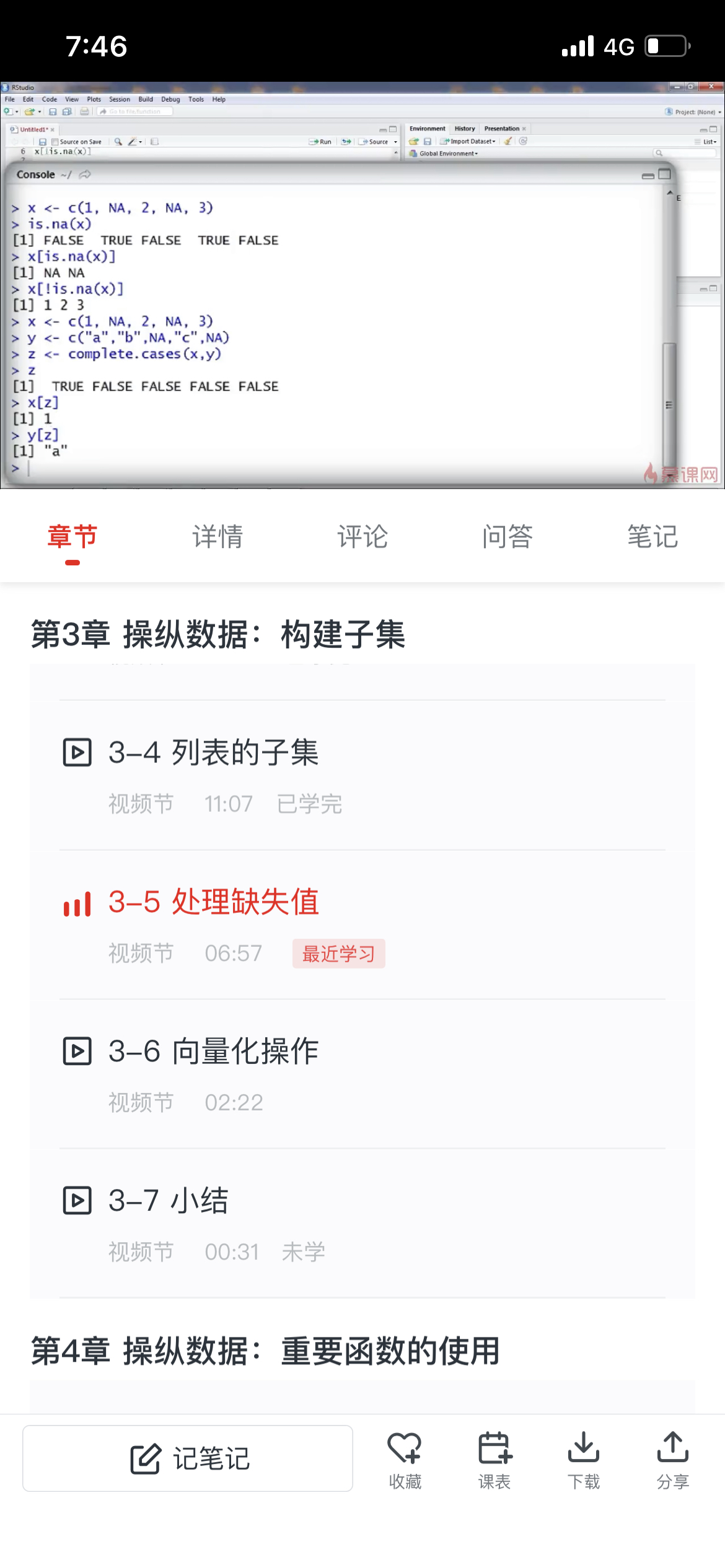
x<-c(1,NA,2,NA,3)
is.na(x)
x[!is.na(x)] (取x中不是缺失值的部分,!的意思是取反,即真变假)
x<-c(1,NA,2,NA,3)
y<-c("a","b",NA,"c"NA)
z<-complete.cases(x,y)(运行之后x和y都不是缺失值的位置才会是TRUE)
然后x[z] y[z]就可以拿到都不是缺失值的元素
进一步看complete函数的功能:
首先加载一下数据集所在的包 library(datasets)
head(airquality)(看一下数据集)
通常情况下会选择都没有缺失值的变量 g<-complete.cases(airquality)
airquality[g,][1:10,](得出的结果是没有缺失值的)
- 0赞 · 0采集
-

- 慕斯6251277 2021-08-10


- 0赞 · 0采集
-

- weixin_慕容1489917 2020-02-19
处理缺失值
x <- c(1,NA,2,NA,3)
x[!is.na(x)] #输出去除缺失值后的x
complete.cases(x,y) #x,y为两个向量,此函数输出结果为逻辑值,只要当对应位置的值都不为缺失值时返回TRUE,否则返回FALSE。
library(datasets) #加载R自带的datasets数据集
head(airquality) #查看数据集前6行
g <- complete.cases(airquality) #去除缺失值
airquality[g,][1:10,] #显示前十条记录
- 0赞 · 0采集
-

- qq_慕移动3337404 2020-02-06
选取x,y对应位置均不是缺失值的元素:z <- complete.cases(x,y)
- 0赞 · 0采集
-

- 慕粉2206434494 2019-12-25
处理缺失值
 创建带有缺失值的向量,判断是否带有缺失值
创建带有缺失值的向量,判断是否带有缺失值 !代表--取反
!代表--取反 complete.case()---获取两个都不是缺失值的数据
complete.case()---获取两个都不是缺失值的数据结果:只有x,y中都不是缺失值的位置是TRUE ,有一个缺失值或者两个缺失值为FALSE
 这样x,y就取到了x,y都不是缺失值位置的内容
这样x,y就取到了x,y都不是缺失值位置的内容 加载datasets这个包
加载datasets这个包 查看其中一个数据集的内容
查看其中一个数据集的内容 判断数据集是否为空值[1]、[13]等,是代表数据的位置,第一个,第十三个
判断数据集是否为空值[1]、[13]等,是代表数据的位置,第一个,第十三个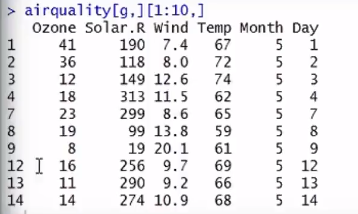
- 0赞 · 0采集
-

- 慕慕0584863 2019-12-11
!表示取反
complete.cases(,)表示取x,y中都不是缺失值的元素
-
截图0赞 · 0采集
-

- qq_慕沐0585126 2019-08-09
得到向量中非缺失值的元素:x[!is.na(x)],!代表取反
选取两个向量(x,y)中对应位置都不是缺失值的元素:用complete.cases()函数给z赋值,得到逻辑向量,然后用x[z]和y[z]得到最终结果
看数据集长什么样用head()函数,数据集中每一行叫做一次记录,每一列叫做一个变量,通常会选择在所有变量中都没有缺失值的记录,这时可用complete.cases(数据集)函数给z(任一字母)赋值
-
截图1赞 · 0采集
-

- 慕先生2438196 2019-08-05
缺失值处理 - 判断缺失值:is.na(x) - 取出向量中非缺失值元素:y[!is.na(x)] - 取出多个向量中的缺失值:z <- complete.cases(x,y) x[z] ; y[z] - 利用数据集实践 library(datasets) - 包含airquality集
library(datasets) #得到R的数据集 head(数据集名称) #返回数据集前六列的数据 可通过g <- complete.cases(数据集名称)返回所有的结果
右下键的packages栏可以查看当前加载的包的情况;
- 0赞 · 0采集
-

- 慕勒4424536 2019-07-29
用x[!is.na(x)]取得x中不是缺失值的元素;
用complete.cases(x,y)来获得对应位置都不是缺失值的元素;
右下键的packages栏可以查看当前加载的包的情况;
- 0赞 · 0采集
-

- 慕雪0237335 2019-03-06
两个向量,选取对应位置都不是缺失值的-用complete选出一个新变量z,只有两者都不是缺失值才会返回true,然后再用x【z】 y【z】选出都不是缺失值的
library加载数据集,dataset是r里自带的数据包
head是取数据集的前六行看看数据及有哪些变量,基本情况。这个数据集有六个变量,目前只看到 6次记录,通常我们希望选取所有变量都没有缺失值的记录
用complete输出的判断 第二行的13表示第二行的第一个true是原数据集的第十三个数据
数据框与向量还是不一样,返回输出非缺失值是考虑行和列,这里我们要每行数据都完整,所以g放在行上,列都留下,所以列的位置空着,后面再加一颗括号就依旧是行列的格式,前10行,列空着。最后输出的数据框左边数字表示选出来的数据在原数据集是第几行
- 0赞 · 1采集
-

- 小调皮3586 2019-01-18
如何处理缺失值
x[!is.na(x)]//除去不是缺失值的元素留下的内容
- 0赞 · 0采集
-

- 杜仲先生 2018-10-10
#如何处理缺失值
x<-c(1,NA,2,NA,3) is.na(x) x[!is.na(x)]#提取出无缺失值的数据,“!”代表取反 x<-c(1,NA,2,NA,3) y<-c("a","b",NA,"c",NA) z<-complete.cases(x,y)#查看x和y的对应位置中均不存在缺失值的部分(以逻辑向量形式表示) x[z]#取出x中对应的非缺失值 y[z]#取出y中对应的非缺失值 library(datasets) head(airquality)#查看数据集中的前面部分 g<-complete.cases(airquality) airquality[g,][1:10,]- 0赞 · 0采集
-

- 慕粉2207325809 2018-09-13
x<-c(1,NA,2,NA,3)
is.na(x) # 返回逻辑向量 FALSE TRUE FALSE TRUE FALSE
(FALSE代表不是缺失值,TRUE代表是缺失值)
x[!is.na(x)] #运行后得到 1 2 3,向量中不是缺失值的元素
x<-c(1,NA,2,NA,3)
y<-c("a","b",NA,"c",NA)
z<-complete.cases(x,y) #选取那些对应位置都不是缺失值的元素,
x[z] #得到x,y里都不是缺失值的元素
y[z] #得到x,y里都不是缺失值的元素
用R自带的数据集来展示complete函数的功能:
library(datasets) #加载一个datasets的包,这个包里包含了很多现成的数据集,找到airquality这个数据集,可以查看airquality这个数据集中有哪些变量
head(airquality) # 展示前六行, 一行代表一个记录,一列代表一个变量,选择在所有变量上都没有缺失值的记录
g<-complete.cases(airquality)
airquality[g, ][1: 10, ]
- 0赞 · 0采集
-

- imblackhat 2018-06-30
x[!is.na(x)] #返回不是缺失值的元素
complete.cases() #()内为两个向量对应的元素都不是缺失值的才为TRUE,否则返回的向量中都为FALSE
library(datasets) #得到R的数据集
head(数据集) #返回数据集前六列的数据
可通过g <- complete.cases(数据集) 返回每条数据是否含有缺失值的向量
数据集[g,][1:10,] #表示不含有缺失值的,所有变量都显示,显示第1到第10行,显示所有列。因为g是向量,所以可以用来选择行,即选择哪些数据
-
截图0赞 · 0采集
-

- 全都在手走一走 2017-11-16
- 缺失值处理 - 判断缺失值:is.na(x) - 取出向量中非缺失值元素:y[!is.na(x)] - 取出多个向量中的缺失值:z <- complete.cases(x,y) x[z] ; y[z] - 利用数据集实践 library(datasets) - 包含airquality集 - 查看前六行数据 head(airquality) - g <- complete.cases(airquality) - 不包含缺失值的结果:airquality[g,]
- 1赞 · 1采集
-

- 慕函数8024186 2017-11-09
- z <-complete.case(data)##返回逻辑值 data <- data[z,]
- 0赞 · 0采集
-

- lvjinge 2017-10-23
- > library(datasets) > head(airquality) Ozone Solar.R Wind Temp Month Day 1 41 190 7.4 67 5 1 2 36 118 8.0 72 5 2 3 12 149 12.6 74 5 3 4 18 313 11.5 62 5 4 5 NA NA 14.3 56 5 5 6 28 NA 14.9 66 5 6 > g<-complete.cases(airquality) > g [1] TRUE TRUE TRUE TRUE FALSE FALSE TRUE TRUE TRUE FALSE FALSE TRUE > airquality[g,][1:10,] Ozone Solar.R Wind Temp Month Day 1 41 190 7.4 67 5 1 2 36 118 8.0 72 5 2 3 12 149 12.6 74 5 3 4 18 313 11.5 62 5 4 7 23 299 8.6 65 5 7 8 19 99 13.8 59 5 8 9 8 19 20.1 61 5 9 12 16 256 9.7 69 5 12 13 11 290 9.2 66 5 13 14 14 274 10.9 68 5 14 > #缺少第六行、十行、十一行的数据,说明这三行存在缺失值
- 0赞 · 0采集
-
- lvjinge 2017-10-23
- 处理缺失值 > x<-c(1,NA,2,NA,3) > is.na(x) [1] FALSE TRUE FALSE TRUE FALSE > #是缺失值 > > x[!is.na(x)] [1] 1 2 3 > #!取反,拿到不是缺失值的元素 > y<-c("a","b","NA","c","NA") > z<-complete.cases(x,y) > z [1] TRUE FALSE TRUE FALSE TRUE > x[z] [1] 1 2 3 > y[z] [1] "a" "NA" "NA"
- 0赞 · 0采集
-

- 沈流 2017-10-04
- 数据集非NA的元素获取法
-
截图0赞 · 0采集
-
- 沈流 2017-10-04
- complete.cases后的逻辑值列表,[1]表示第一行开始的第一个元素为整个向量中的第一个
-
截图0赞 · 0采集
-
- 沈流 2017-10-04
- head()获取数据集前面6行
-
截图0赞 · 0采集
-
- 沈流 2017-10-04
- 使用数据集需要加载包,例:library(datasets)
-
截图0赞 · 0采集
-
- 沈流 2017-10-04
- 将多个向量组的元素对比并取得共同位置不是NA的元素——complete.cases(x,y)
-
截图0赞 · 0采集
-
- 沈流 2017-10-04
- 取得一组向量中非缺失值部分,!的使用
-
截图0赞 · 0采集
-

- Crystalslsw 2017-09-19
- head()# 前六行
- 0赞 · 0采集
-

- 九等紫檀 2017-08-29
- #missing value x <- c(1,NA,2,NA,3) x[!is.na(x)] #获取不为缺失值的元素 y <- c("a","b",NA,"C",NA) z <- complete.cases(x,y) x[z] y[z] #使用R的数据集 library(datasets) head(airquality) #查看数据集的开头 g <- complete.cases(airquality) airquality[g,][1:10,] #去除数据集中有缺失值的行
-
截图0赞 · 0采集
-

- mr_brianweng 2017-07-25
- is.na是检验缺失值的,在[!]当中表示取反输出ttrue,compete函数是去判断对应向量都是是缺失值会显示TURE,之后应{}就可以输出了
-
截图0赞 · 0采集
-

- 滕玉龙 2017-06-12
- x[!is.na(x)] #返回不是缺失值的元素 complete.cases() #()内对应的都不是缺失值的才为TRUE,否则返回的向量中都为FALSE library(datasets) #得到R的数据集 head(数据集名称) #返回数据集前六列的数据 可通过g <- complete.cases(数据集名称)返回所有的结果 数据集名[g,][1:10,] #表示不含有缺失值的,所有变量都显示,显示第1到第10行,显示所有列
-
截图2赞 · 1采集
-
- 滕玉龙 2017-06-12
- 每一行(记录),每一列(变量)
-
截图1赞 · 1采集
























