-

- 慕工程2344038 2025-12-12
- 。。 。。冬天让。#等等。都让人。你好,的路灯又eere4df?y;?;;对的人。套。对的。打扰到。你01果园新村小程序行行重行行想吃串串
cytdsdzvssdf
f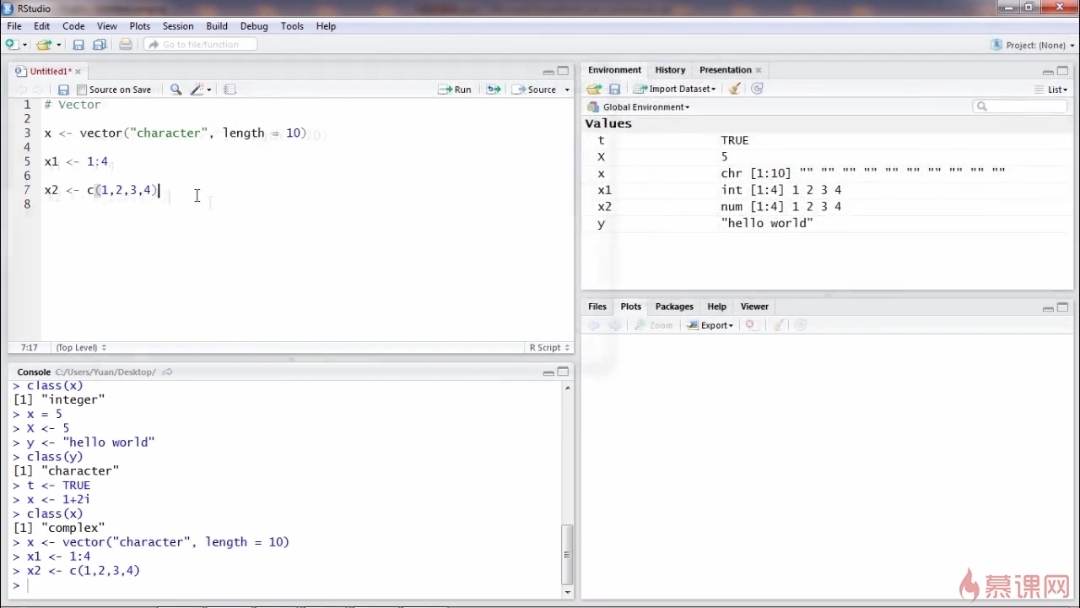 ,谢学长6x
,谢学长6x - 0赞 · 0采集
-

- 慕勒242594 2024-09-13
如何处理缺失值
- 0赞 · 0采集
-
- 慕勒242594 2024-09-12
矩阵中构建子集(行,列)
矩阵和向量的区别
,向量是给出行或列
矩阵给出的是行和列
- 0赞 · 0采集
-
- 慕勒242594 2024-09-12
构建子集subsetting
raw dataset and clean dateset
【】
【【】】
$
拿到数据顺序:子集
- 0赞 · 0采集
-
- 慕勒242594 2024-09-12
日期和时间
date,time
date()
sys.date()
as.date(年-月-日)
weekday()
months()
quarters()
julian()
posixct()
posixlT()
strptime()
- 0赞 · 0采集
-
- 慕勒242594 2024-09-11
数据框:data frame
data.frame()
- 0赞 · 0采集
-
- 慕勒242594 2024-09-11
因子:factor处理分类数据,有序或无序
证书向量+标签
X<-factor(c())
levels=极限水平
- 0赞 · 0采集
-
- 慕勒242594 2024-09-11
列表:list
矩阵:matrix
数组:array
- 0赞 · 0采集
-

- weixin_慕前端5321204 2024-03-14
is.na和is.nan的区别
- 0赞 · 0采集
-

- weixin_精慕门9172904 2023-09-18

NaN属于NA,因为NaN一般用来表示数字的缺失值,NA可以表示的缺失值的范围更广
判断向量里面是否有缺失值,用:
is.na()/is.nan,对应以上两种缺失值

以上例子说明:
存在第二个和第四个是na类型的缺失值
不存在nan这个类型的缺失值
如果将x中的内容改成NaN则:

可以发现:na是可以检测出nan的缺失值的
- 0赞 · 0采集
-
- weixin_精慕门9172904 2023-09-18

因子是用来处理分类数据的
有序 例子:年龄低中高
无序 例子:性别男女
因子优于整数向量,因为可以对整数向量进行描述,如你会知道1或者2代表男性还是女性
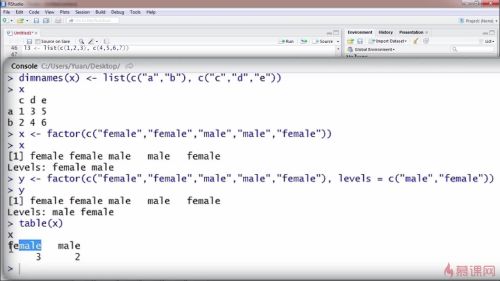
factor函数:用c将所有人的性别连在一起;输出后得到x的内容;level可以查看因子包含的水平

在factor里面插入第二个函数 levels:levels的第一个参数的就是基线水平

对x有一个基本的了解,使用table函数,可查看不同水平内容的个数:
可以用unclass函数去掉levels:

内容是:
attr显示曾经的level和其内容
用class函数查看unclass之后x变成了什么类别的数据

- 0赞 · 0采集
-
- weixin_精慕门9172904 2023-09-18

和矩阵最大的区别就是列表可以包含不同类型的数据
list函数:每一个参数都是列表里面元素的内容

给列表里的元素命名,用元素a=名字1这样的规则进行命名

列表中每一个元素的个数大于1
用c将元素合并 c(1,2,3)的意思就是c这个元素里面有123这个三个内容

引入矩阵的维度
给矩阵的每一行每一列命名:
dimnames(矩阵)<-赋值list(行的命名,列的命名)【list里面第一个元素c包含两行,第二个元素c包含三列】

- 0赞 · 0采集
-
- weixin_精慕门9172904 2023-09-17

创建矩阵:
matrix,两个参数,多少行+多少列
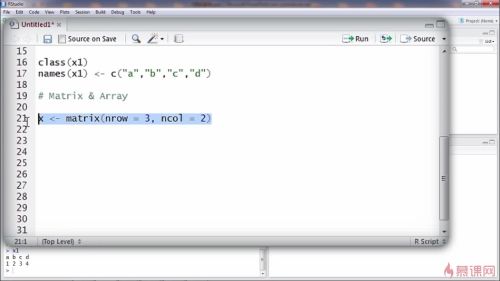
出现:

console出现:

添加矩阵的内容:

控制台console出现:
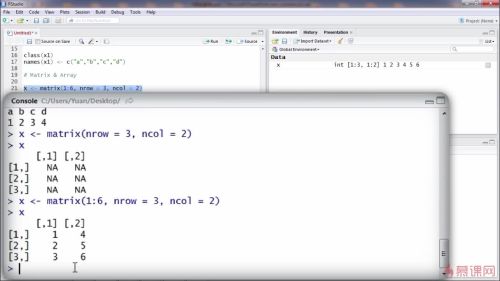
矩阵填充是按照列的方式来填充的
查看矩阵维度属性:
dim(x)
可以查看有多少行多少列

三行两列
矩阵有多少属性,有哪些属性:
attributes(x)
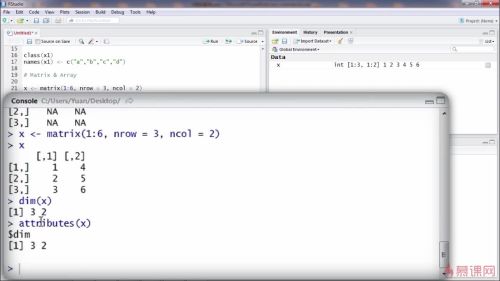
当前这个矩阵的属性是维度
矩阵就是向量加上维度属性
所以也可以用以下方式进行矩阵的创建:
给y向量添加维度信息dim赋值c,这个c函数里面写两个参数,第一个参数有多少行,第二个有多少列

运行后:

两个矩阵进行拼接
按照行来拼接:rbind

按照列拼接:cmind

数组

用arry函数,第一个参数是数组的内容,第二个参数是维度dim的设定
二维:

三维:
第三个维度“4”代表有四个元素;
“,,1”代表的是第三个维度里的第一个元素,也就是“4”这个维度中的第一个元素。
第三个维度的第一个元素“,,1”中是一个两行三列的矩阵,也就是dim函数的前两个维度:2✖3
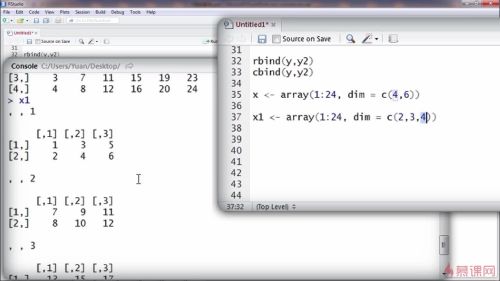
注意的是:1:24的排列是按照第三个维度中的每一个元素排下来的,也就是说:先排完“,,1”的123456,再排“,,2”....
- 0赞 · 1采集
-
- weixin_精慕门9172904 2023-09-17

向量是可以包含多种同一类型元素的对象
console中命令是一次性的不可重复利用
新建文件:保存和重复利用代码
注释用#
创建函数可以右键看到提示
vector:
创建方法1
第一个参数是这个向量里面元素的类型,第二个参数是向量包含的原色个数,长度如是10个
脚本文件中要选择这句话,点击右上角run
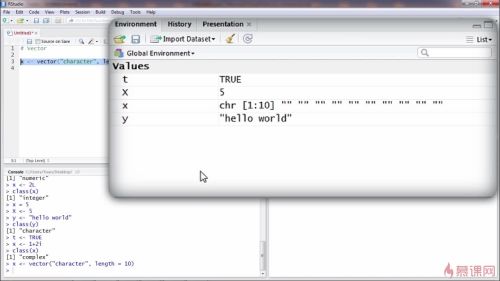
创建方法2
变量<-赋值1:4,即从一到四

创建方法3使用c函数,需要在这个函数中输入你需要的在这个向量中的每一个元素的内容
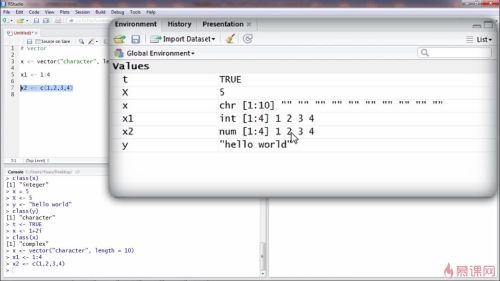
注意:
如果向量中每一个量的元素的类型不一样,r会强制转换成同一类型的变量

上面的例子就是r把3个不同类型的元素类型都转换成了字符类型的元素
可以自我强制转换元素的类型,添加as.,如把字符型转换成数字型
强制转换的函数:
as.numeric(参数)as.logical()
as.character()
以此类推
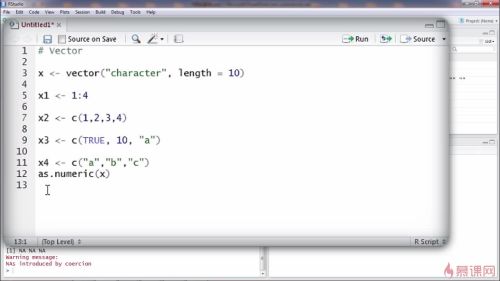
但是有可能会看到warning信息,因为r有可能不知道怎么把字符型转换成数字型函数,就会把无法转换的值用NA来替代

此外,记得可以用class查询向量的类型
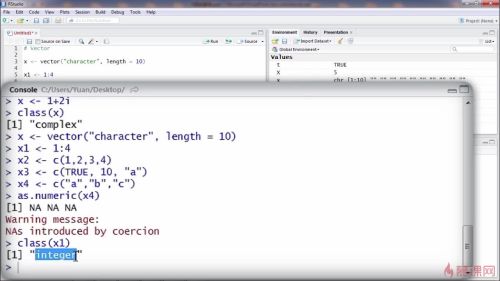
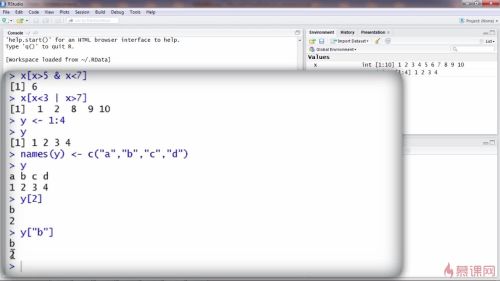
对象的属性可以包含名称,向量中的每一个元素都是可以有名称的
names(向量x1)<-c(“a”,。。。。)
设置abcd四个是因为向量x1中有4个元素

上图可见,第一个元素的名称是a,第二个元素的名称是B,......
- 0赞 · 0采集
-
- weixin_精慕门9172904 2023-09-17

左侧为控制台,右侧上方环境中的变量,右侧下方看绘图和包的信息和帮助文档的地方等
创建变量x,赋值符号<- 右侧环境中出现values=1

输入x然后回车:方括号1的意思是它后面接着的元素是x中第一个元素,没有方括号的1代表x中存储的内容是1
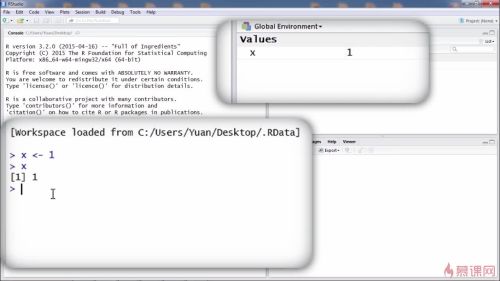
查看对象类型的函数:class
numeric:x是数值型变量,它的值可以是整数也可以是小数
强调存储的是整数,只需要赋值的时候在后面加L
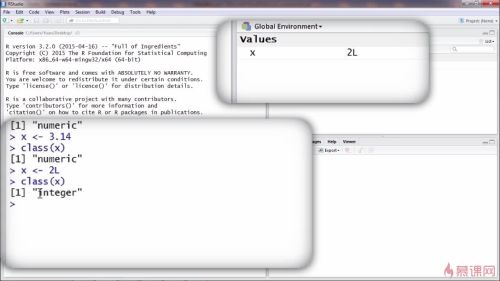
细节:
赋值符号<-
注意x是大写还是小写,这是不同的两个变量
创建字符型变量:赋值双引号“”

逻辑型变量:真假
复数
r的对象的属性
- 0赞 · 1采集
-

- 慕姐2471796 2023-07-24
列表
l <- list("a", 2, 10L, 3+4i, TRUE)
列表命名l2 <- list(a=1, b=2, c=3)
列表中每个元素中的元素个数大于1
l3 <- list(c(1,2,3), c(4,5,6,7))
矩阵行列命名
x <- matrix(1:6, nrow=2, ncol=3)
dimnames(x) <- list(c("a","b"), c("c","d","e"))
(x是一个矩阵,a.b是行的名字,d,e是列的名字)
- 0赞 · 0采集
-
- 慕姐2471796 2023-07-24
R数据结构
2.矩阵(matrix):向量+维度属性(整数向量:nrow, ncol)
2.1 创建矩阵:
方法一: x <- matrix(nrow=3, ncol=2) #创建一个3行2列矩阵,元素为NA。该函数创建矩阵时先列后行。
x <- matrix(1 : 6, nrow=3, ncol=2) #按列填充元素
方法二: y <- 1 : 6 #生成一个向量
dim(y) <- c(2, 3) #指定行数与列数
其他:dim(matrix):查看矩阵matrix的行数与列数
attributes(matrix):查看矩阵matrix有哪些属性
2.2 拼接矩阵
y1 <- 1 : 6
dim(y1) <- c(2 : 3)
y2 <- matrix(1:6, nrow =2, ncol=3)
rbind(y1, y2) #按行拼接
cbind(y1, y2) #按列拼接3.数组:与矩阵类似,但维度可以大于2
创建数组:x <- array(1:24, dim=c(4, 6)) #参数1填充元素,参数2指定维度
y <- array(1:24, dim=c(2, 3, 4))
- 0赞 · 0采集
-
- 慕姐2471796 2023-07-24
向量(vector):只能包含同一类型的对象
创建向量的方法:1. 定义 x <- vector(数据类型,数据长度)
2. x1 <- 1:4 #创建整型向量1-4
3. x3 <- c(向量的元素) # 例如构建向量x3<-c(1,2)
#对于向量中元素类型不同的情况,R语言中会自动强制转化
例如x3 <- c(TRUE,10,"a") 会转换为("TRUE","10","a")
as.numeric(x) #将x转换为数值型向量
as.logical(x) #将x转换为逻辑向量
as.character(x) #将x转换为字符型向量
names(x1) <- c("a","b","c") #给向量x1进行命名,“a”为第一个向量元
素的名字,依次类推
- 0赞 · 0采集
-
- weixin_慕沐4005445 2023-03-30

#日期

- 0赞 · 0采集
-
- weixin_慕沐4005445 2023-03-30










 1
1

- 0赞 · 0采集
-
- weixin_慕沐4005445 2023-03-30


 1
1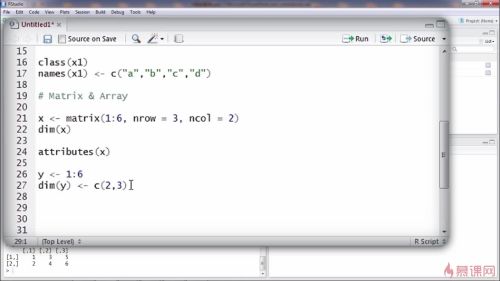



- 0赞 · 0采集
-
- weixin_慕沐4005445 2023-03-30
1

- 0赞 · 0采集
-

- 慕丝2186471 2022-11-12
数组三个维度的排列

- 0赞 · 0采集
-

- 乐子瞻 2022-01-03
#tapply函数的应用
#对向量的子集进行操作
#rnorm(5)前五个正态分布
#runif(5)中间五个均匀分布
#rnorm(5,1)均值标准差为0的分布
x<-c(rnorm(5),runif(5),rnorm(5,1))#第三个为均值为1,方差为0的正态分布
f<-gl(3,5)#
tapply(x,f,mean)
tapply(x,f,mean,simplify=FALSE)
- 0赞 · 0采集
-
- 乐子瞻 2022-01-03
#data frame 数据框
#第一个参数代表第一列的内容,第二个参数表示第二列的内容
df <- data.frame(id = c(1,2,3,4),name = c("a","b","c","d"),gender = c(TRUE,TRUE,FALSE,FALSE))
#查看数据框有多少行
nrow(df)
#查看数据框有多少列
ncol(df)
#定义一个类似矩阵的数据框
df2 <- data.frame(id=c(1,2,3,4),score = c(89,90,70,50))
#数据框转换成矩阵,要求,第二个参数的数据类型必须一样
data.matrix(df2)
- 0赞 · 0采集
-

- 慕容8030739 2022-01-01

本章小结-学习内容
- 0赞 · 0采集
-

- 慕UI6483783 2021-11-28
数据结构矩阵函数

- 0赞 · 0采集
-

- 大白小白i 2021-09-26
4-7总结数据信息
head(airquality)(airquality的前6行)
head(airquality,10)(airquality的前10行)
tail(airquality)(airquality的后6行)
summary(airquality的变量的描述统计)
str(airquality)(把airquality进行了总结)
table(airquality$Ozone,useNA="ifany")(如果有缺失值就总结出来)
table(airquality$Month,airquality$Day)(得到二维的表)
any(is.na(airquality$Ozone))(如果返回的是TRUE,就说明一定有缺失值)
sum(is.na(airquality$Ozone))(臭氧含量中有多少缺失值)
all(airquality$Month<12)(是不是所有的月份都小于12)
titanic<-as.data.frame(Titanic)
head(Titanic)
dim(Titanic)(维度)
summary(Titanic)
x<-xtabs(Freq~Class+Age,data=titanic)(Class+Age的交叉频率,)
ftable(x)(与上面类似 结果更扁平化)
object.size(airquality)(数据的大小)
print(object.size(airquality),units="kb")
- 0赞 · 0采集
-
- 大白小白i 2021-09-26
4-6排序
排序
sort:对向量进行排序;返回排好序的内容
order:返回排好序的内容的下标/多个排序标准
x<-data.frame(v1=1:5,v2=c(10,7,9,6,8),v3=11:15,v4=c(1,1,2,2,1))
sort(x$v2)(对v2这一列按照升序进行排序)
sort(x$v2,decreasing=TRUE)(对v2这一列按照降序进行排序)
order(x$v2)(返回的不是内容本身 返回了行号)
x[order(x$v2),](对整个数据框按照v2这一列进行排序)
x[order(x$v4,x$v2),](对整个数据框按照v4这一列进行排序,如果v4中有重复的元素,则按照v2排序)
x[order(x$v4,x$v2),decreasing=TRUE](降序)
- 0赞 · 0采集
-
- 大白小白i 2021-09-26
4-5split
split:根据因子或因子列表将向量或者其他对象进行分组,通常与lapply一起使用。
split(参数):split(向量/列表/数据框,因子/因子列表)
x<-c(rnom(5),runif(5),rnorm(5,1))
f<-gl(3,5)
split(x,f)(返回了列表,有3个水平,每个水平有5个元素)
lapply(split(x,f),mean)
head(airquality)
s<-split(airquality,airquality$Month)(按月份来查看空气质量的数据)
table(airquality$Month)(airquality到底包含了多少个月份的数据并且每个月下面多少条记录)
lapply(s,function(x) colMeans(x[,c("Ozone","Wind","Temp")]))(计算每1个月的臭氧含量、风速和温度的平均值)
sapply(s,function(x) colMeans(x[,c("Ozone","Wind","Temp")],na.rm=TRUE))(不包含缺失值)
- 0赞 · 0采集









