-

- 慕姐0267268 2025-06-13
相关子查询能否用部门分组平均薪水来替代?
- 0赞 · 0采集
-
- 慕姐0267268 2025-06-12
rownum在原表中是升序,对原表做降序数据处理后rownum顺序没发生变化,要做TOP-N分析可以做一个子查询,在新的查询结果中做rownum的筛选会更有效。如select rownum from(selece * from 表 order by 降序)where rownum<数字能取出rownum 准确的前几行。
- 0赞 · 0采集
-
- 慕姐0267268 2025-06-12
分组函数可以嵌套,比如有多个部门,先求出每个部门的平均工资,得到的结果值可以同时嵌套一个max在后边,得到的结果就是每个部门的平均工资最大值。
- 0赞 · 0采集
-
- 慕姐0267268 2025-06-12
order by 后面的字段可以用select 中对应字段数,比如(第一列、第二列等来表示)
- 0赞 · 0采集
-

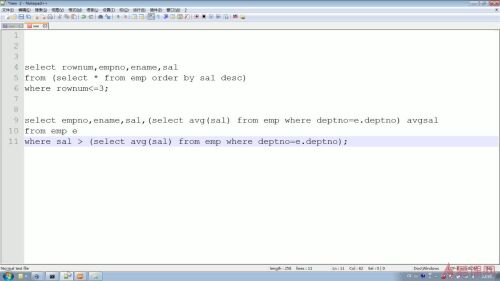
- 旧莳0 2023-10-25
select rownum,empno,ename,sal from (select * from emp order by sal desc) where rownum <= 3;
- 0赞 · 0采集
-

- 斯巴达汉子 2022-02-01
create table pm_ci
(ci_id varchar2(20),
stu_ids varchar2(100));
insert into pm_ci values('1','1,2,3,4');
insert into pm_ci values('2','1,4');
create table pm_stu
(stu_id varchar2(20),
stu_name varchar2(20));
insert into pm_stu values('1','张三');
insert into pm_stu values('2','李四');
insert into pm_stu values('3','王五');
insert into pm_stu values('4','赵六');
col stu_name for a20;
select c.ci_id,wm_concat(s.stu_name) stu_name
from pm_ci c,pm_stu s
where instr(c.stu_ids,s.stu_id)>0
group by c.ci_id;
- 0赞 · 0采集
-
- 斯巴达汉子 2022-02-01
按照部门统计工人数,按照如下格式输出
方式一:函数的方式
select count(*) Total,
sum(decode(to_char(hiredate,'YYYY'),'1980',1,0)) "1980",
sum(decode(to_char(hiredate,'YYYY'),'1981',1,0)) "1981",
sum(decode(to_char(hiredate,'YYYY'),'1982',1,0)) "1982",
sum(decode(to_char(hiredate,'YYYY'),'1987',1,0)) "1987"
from emp;
decode(条件,值1,返回值1,值2,返回值2,...值n,返回值n,缺省值)
方式二:子查询的方式
select
(select count(*) from emp) Total,
(select count(*) from emp where to_char(hiredate,'yyyy')='1980') "1980",
(select count(*) from emp where to_char(hiredate,'yyyy')='1981') "1981",
(select count(*) from emp where to_char(hiredate,'yyyy')='1982') "1982",
(select count(*) from emp where to_char(hiredate,'yyyy')='1987') "1987"
from dual;
dual 伪表
- 0赞 · 0采集
-
- 斯巴达汉子 2022-01-31
找到员工表中薪水大于本部门平均薪水的员工
select empno,ename,sal,(select avg(sal) from emp where deptno=e.deptno) avgsal
from emp e
where sal>(select avg(sal) from emp where deptno=e.deptno);
-- 用多表查询实现
select e.empno,e.ename,e.sal,d.avgsal
from emp e,(select deptno,avg(sal) avgsal from emp group by deptno) d
where e.deptno=d.deptno and e.sal > d.avgsal;
--- 查询sql语句运算效率
explain plan for
select empno,ename,sal,(select avg(sal) from emp where deptno=e.deptno) avgsal
from emp e
where sal>(select avg(sal) from emp where deptno=e.deptno);
select * from table (dbms_xplan.display);
explain plan for
select e.empno,e.ename,e.sal,d.avgsal
from emp e,(select deptno,avg(sal) avgsal from emp group by deptno) d
where e.deptno=d.deptno and e.sal > d.avgsal;
select * from table (dbms_xplan.display);
************************************************************************
SQL> select rownum,r,empno,ename,sal
2 from (select rownum r,empno,ename,sal
3 from (select rownum,empno,ename,sal from emp order by sal desc) e1
4 where rownum<=8) e2
5 where r>=5;
ROWNUM R EMPNO ENAME SAL
---------- ---------- ---------- ---------- ----------
1 5 7698 BLAKE 2850
2 6 7782 CLARK 2450
3 7 7499 ALLEN 1600
4 8 7844 TURNER 1500
SQL> select e.empno,e.ename,e.sal,d.avgsal
2 from emp e,(select deptno,avg(sal) avgsal from emp group by deptno) d
3 where e.deptno=d.deptno and e.sal > d.avgsal;
EMPNO ENAME SAL AVGSAL
---------- ---------- ---------- ----------
7499 ALLEN 1600 1566.66667
7566 JONES 2975 2175
7698 BLAKE 2850 1566.66667
7788 SCOTT 3000 2175
7839 KING 5000 2916.66667
7902 FORD 3000 2175
已选择6行。
SQL> select empno,ename,sal,(select avg(sal) from emp where deptno=e.deptno) avgsal
2 from emp e
3 where sal>(select avg(sal) from emp where deptno=e.deptno);
EMPNO ENAME SAL AVGSAL
---------- ---------- ---------- ----------
7499 ALLEN 1600 1566.66667
7566 JONES 2975 2175
7698 BLAKE 2850 1566.66667
7788 SCOTT 3000 2175
7839 KING 5000 2916.66667
7902 FORD 3000 2175
已选择6行。
SQL> explain plan for
2 select empno,ename,sal,(select avg(sal) from emp where deptno=e.deptno) avgsal
3 from emp e
4 where sal>(select avg(sal) from emp where deptno=e.deptno);
已解释。
SQL>
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------
------------------------------
Plan hash value: 2385781174
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 43 | 8 (25)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 7 | | |
|* 2 | TABLE ACCESS FULL | EMP | 5 | 35 | 3 (0)| 00:00:01 |
|* 3 | HASH JOIN | | 1 | 43 | 8 (25)| 00:00:01 |
| 4 | VIEW | VW_SQ_1 | 3 | 78 | 4 (25)| 00:00:01 |
| 5 | HASH GROUP BY | | 3 | 21 | 4 (25)| 00:00:01 |
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------
------------------------------
| 6 | TABLE ACCESS FULL| EMP | 14 | 98 | 3 (0)| 00:00:01 |
| 7 | TABLE ACCESS FULL | EMP | 14 | 238 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("DEPTNO"=:B1)
3 - access("ITEM_1"="E"."DEPTNO")
filter("SAL">"AVG(SAL)")
已选择21行。
SQL> explain plan for
2 select e.empno,e.ename,e.sal,d.avgsal
3 from emp e,(select deptno,avg(sal) avgsal from emp group by deptno) d
4 where e.deptno=d.deptno and e.sal > d.avgsal;
已解释。
SQL> select * from table (dbms_xplan.display);
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------
------------------------------
Plan hash value: 269884559
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 43 | 8 (25)| 00:00:01 |
|* 1 | HASH JOIN | | 1 | 43 | 8 (25)| 00:00:01 |
| 2 | VIEW | | 3 | 78 | 4 (25)| 00:00:01 |
| 3 | HASH GROUP BY | | 3 | 21 | 4 (25)| 00:00:01 |
| 4 | TABLE ACCESS FULL| EMP | 14 | 98 | 3 (0)| 00:00:01 |
| 5 | TABLE ACCESS FULL | EMP | 14 | 238 | 3 (0)| 00:00:01 |
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------
------------------------------
-----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("E"."DEPTNO"="D"."DEPTNO")
filter("E"."SAL">"D"."AVGSAL")
已选择18行。
- 0赞 · 0采集
-
- 斯巴达汉子 2022-01-31
行号rownum是个伪列
- 0赞 · 0采集
-
- 斯巴达汉子 2022-01-31
子查询注意的10个问题
1.子查询语法中的小括号
2.子查询的书写风格
3.可以使用子查询的位置:where,select,having,from后面使用子查询
4.不可以使用子查询的位置:group by后面不可使用子查询
5.强调:from后面的子查询---
6.主查询和子查询可以不是同一张表
7.一般不在子查询中使用排序;但在Top-N分析问题中,必须对子查询排序
8.一般先执行子查询,再执行主查询;但相关子查询例外
9.单行子查询只能使用单行操作符;多行子查询只能使用多行操作符;
10.注意:子查询中是null值问题
1---如果没有小括号,语法是错误的
2----书写风格好,方便阅读
3----
单行子查询---仅仅返回一条记录
多行子查询---返回多行记录,2行及其以上
select empno,ename,sal,(select job from emp where empno=7839) 第四列
from emp;
select deptno,avg(sal)
from emp
group by deptno
having avg(sal) > (select max(sal)
from emp
where deptno=30);
-- 这having不能用where替代,有avg
select *
from(select empno,ename,sal from emp);
-- from 中加子查询的,用的很多
-- 括号里面,相当于一个新的结果集
4 -- group by 后不能使用子查询
-- 错误示例
select avg(sal)
from emp
group by (select deptno from emp);
5.from后面的子查询
select *
from (select empno,ename,sal,sal*12 from emp);
--通过12*sal计算出年薪
6.主查询和子查询不是一张表
-- 查询销售部员工
select *
from emp
where deptno=(select deptno
from dept
where dname='SALES');
-- 多表查询的方式解决同样问题,相对上面,这里数据库访问一次,效率得根据实际数据量模式
select e.*
from emp e,dept d
where e.deptno=d.deptno and d.dname='SALES';
7.一般不在子查询中使用排序;但在Top-N分析问题中,必须对子查询排序
select rownum,empno,ename,sal
from emp
where rownum<3
order by sal desc;
select rownum,empno,ename,sal from emp order by sal desc;
行号永远按照默认的顺序生成
行号只能使用< <=不能使用> >=
select rownum,empno,ename,sal
from (select * from emp order by sal desc)
where rownum<=3;
8.一般先执行子查询,再执行主查询;但相关子查询例外
-- 查询在所在部门,工资高于平均工资的员工
select empno,ename,sal,(select avg(sal) from emp where deptno=e.deptno) avgsal
from emp e
where sal > (select avg(sal) from emp where deptno=e.deptno);
9.单行子查询只能使用单行操作符
多行子查询只能使用多行操作符
返回一条记录---单行子查询
返回2条及其以上----多行子查询
单行子查询示例1:
查询员工信息:
1.职位与7566员工一样
2.薪水大于7782的薪水
select *
from emp
where job = (select job from emp where empno=7566) and
sal > (select sal from emp where empno=7782);
单行子查询示例2:
查询工资最低的员工信息
select *
from emp
where sal = (select min(sal) from emp);
单行查询示例-3:
查询最低工资大于20号部门最低工资的部门号和部门的最低工资
select deptno,min(sal)
from emp
group by deptno
having min(sal) > (select min(sal)
from emp
where deptno=20);
多行操作符-
in--- 等于列表中的任何一个
any--- 和子查询返回的任意一个值比较
all--- 和子查询返回的所有值比较
多行操作符in:
查询部门名称是SALES和ACCOUNTING的员工信息
select *
from emp
where deptno in (select deptno from dept where dname='SALES' or dname='ACCOUNTING');
多表查询实现:
select e.*
from emp e,dept d
where e.deptno=d.deptno and (d.dname='SALES' or d.dname='ACCOUNTING');
tips:如若不加括号,按照and,or从前到后次序执行;
多行操作符any
示例:查询工资比30号部门任意一个员工高的员工信息
select *
from emp
where sal > any (select sal from emp where deptno=30);
select *
from emp
where sal > (select min(sal) from emp where deptno=30);
多行操作符:all
示例:查询工资比30号部门所有员工高的员工信息
select *
from emp
where sal > all (select sal from emp where deptno=30);
select *
from emp
where sal > (select max(sal) from emp where deptno=30);
10.子查询中的null问题
单行子查询中的null问题----结果是空值
多行子查询中的null问题
示例:查询不是老板的员工
select *
from emp
where empno not in (select mgr from emp);
-- 因为子查询中有null,导致返回空数据
select *
from emp
where empno not in (select mgr from emp where mgr is not null);
*******************************************************
- 0赞 · 0采集
-
- 斯巴达汉子 2022-01-31
10.子查询中的null问题
单行子查询中的null问题----结果是空值
多行子查询中的null问题
示例:查询不是老板的员工
select *
from emp
where empno not in (select mgr from emp);
-- 因为子查询中有null,导致返回空数据
select *
from emp
where empno not in (select mgr from emp where mgr is not null);
- 0赞 · 0采集
-
- 斯巴达汉子 2022-01-31
9.单行子查询只能使用单行操作符
多行子查询只能使用多行操作符
返回一条记录---单行子查询
返回2条及其以上----多行子查询
单行子查询示例1:
查询员工信息:
1.职位与7566员工一样
2.薪水大于7782的薪水
select *
from emp
where job = (select job from emp where empno=7566) and
sal > (select sal from emp where empno=7782);
单行子查询示例2:
查询工资最低的员工信息
select *
from emp
where sal = (select min(sal) from emp);
单行查询示例-3:
查询最低工资大于20号部门最低工资的部门号和部门的最低工资
select deptno,min(sal)
from emp
group by deptno
having min(sal) > (select min(sal)
from emp
where deptno=20);
多行操作符-
in--- 等于列表中的任何一个
any--- 和子查询返回的任意一个值比较
all--- 和子查询返回的所有值比较
多行操作符in:
查询部门名称是SALES和ACCOUNTING的员工信息
select *
from emp
where deptno in (select deptno from dept where dname='SALES' or dname='ACCOUNTING');
多表查询实现:
select e.*
from emp e,dept d
where e.deptno=d.deptno and (d.dname='SALES' or d.dname='ACCOUNTING');
tips:如若不加括号,按照and,or从前到后次序执行;
多行操作符any
示例:查询工资比30号部门任意一个员工高的员工信息
select *
from emp
where sal > any (select sal from emp where deptno=30);
select *
from emp
where sal > (select min(sal) from emp where deptno=30);
多行操作符:all
示例:查询工资比30号部门所有员工高的员工信息
select *
from emp
where sal > all (select sal from emp where deptno=30);
select *
from emp
where sal > (select max(sal) from emp where deptno=30);

- 0赞 · 0采集
-
- 斯巴达汉子 2022-01-31

单行子查询错误示例提示
subquery 子查询
ORA-01427 single-row subquery returns more than one row
- 0赞 · 0采集
-
- 斯巴达汉子 2022-01-31
8.一般先执行子查询,再执行主查询;但相关子查询例外
-- 查询在所在部门,工资高于平均工资的员工
select empno,ename,sal,(select avg(sal) from emp where deptno=e.deptno) avgsal
from emp e
where sal > (select avg(sal) from emp where deptno=e.deptno);
*******************************************************************
SQL> select empno,ename,sal,(select avg(sal) from emp where deptno=e.deptno) avgsal
2 from emp e
3 where sal > (select avg(sal) from emp where deptno=e.deptno);
EMPNO ENAME SAL AVGSAL
---------- ---------- ---------- ----------
7499 ALLEN 1600 1566.66667
7566 JONES 2975 2175
7698 BLAKE 2850 1566.66667
7788 SCOTT 3000 2175
7839 KING 5000 2916.66667
7902 FORD 3000 2175
已选择6行。
- 0赞 · 0采集
-
- 斯巴达汉子 2022-01-31
7.一般不在子查询中使用排序;但在Top-N分析问题中,必须对子查询排序
select rownum,empno,ename,sal
from emp
where rownum<3
order by sal desc;
select rownum,empno,ename,sal from emp order by sal desc;
行号永远按照默认的顺序生成
行号只能使用< <=不能使用> >=
select rownum,empno,ename,sal
from (select * from emp order by sal desc)
where rownum<=3;
*******************************************************
SQL> select rownum,empno,ename,sal
2 from emp
3 where rownum<3
4 order by sal desc;
ROWNUM EMPNO ENAME SAL
---------- ---------- ---------- ----------
2 7499 ALLEN 1600
1 7369 SMITH 800
SQL> select rownum,empno,ename,sal
2 from (select * from emp order by sal desc)
3 where rownum<=3;
ROWNUM EMPNO ENAME SAL
---------- ---------- ---------- ----------
1 7839 KING 5000
2 7788 SCOTT 3000
3 7902 FORD 3000
SQL> select rownum,empno,ename,sal from emp order by sal desc;
ROWNUM EMPNO ENAME SAL
---------- ---------- ---------- ----------
9 7839 KING 5000
13 7902 FORD 3000
8 7788 SCOTT 3000
4 7566 JONES 2975
6 7698 BLAKE 2850
7 7782 CLARK 2450
2 7499 ALLEN 1600
10 7844 TURNER 1500
14 7934 MILLER 1300
3 7521 WARD 1250
5 7654 MARTIN 1250
ROWNUM EMPNO ENAME SAL
---------- ---------- ---------- ----------
11 7876 ADAMS 1100
12 7900 JAMES 950
1 7369 SMITH 800
已选择14行。
- 0赞 · 0采集
-
- 斯巴达汉子 2022-01-31
6.主查询和子查询不是一张表
-- 查询销售部员工
select *
from emp
where deptno=(select deptno
from dept
where dname='SALES');
-- 多表查询的方式解决同样问题,相对上面,这里数据库访问一次,效率得根据实际数据量模式
select e.*
from emp e,dept d
where e.deptno=d.deptno and d.dname='SALES';
- 0赞 · 0采集
-
- 斯巴达汉子 2022-01-31
-- group by 后不能使用子查询
-- 错误示例
select avg(sal)
from emp
group by (select deptno from emp);
- 0赞 · 0采集
-
- 斯巴达汉子 2022-01-31
3----
单行子查询---仅仅返回一条记录
多行子查询---返回多行记录,2行及其以上
select empno,ename,sal,(select job from emp where empno=7839) 第四列
from emp;
select deptno,avg(sal)
from emp
group by deptno
having avg(sal) > (select max(sal)
from emp
where deptno=30);
-- 这having不能用where替代,有avg
select *
from(select empno,ename,sal from emp);
-- from 中加子查询的,用的很多
-- 括号里面,相当于一个新的结果集
*******************************************************
SQL> select empno,ename,sal,(select job from emp where empno=7839) 第四列
2 from emp;
EMPNO ENAME SAL 第四列
---------- ---------- ---------- ---------
7369 SMITH 800 PRESIDENT
7499 ALLEN 1600 PRESIDENT
7521 WARD 1250 PRESIDENT
7566 JONES 2975 PRESIDENT
7654 MARTIN 1250 PRESIDENT
7698 BLAKE 2850 PRESIDENT
7782 CLARK 2450 PRESIDENT
7788 SCOTT 3000 PRESIDENT
7839 KING 5000 PRESIDENT
7844 TURNER 1500 PRESIDENT
7876 ADAMS 1100 PRESIDENT
EMPNO ENAME SAL 第四列
---------- ---------- ---------- ---------
7900 JAMES 950 PRESIDENT
7902 FORD 3000 PRESIDENT
7934 MILLER 1300 PRESIDENT
已选择14行。
SQL> select deptno,avg(sal)
2 from emp
3 group by deptno
4 having avg(sal) > (select max(sal)
5 from emp
6 where deptno=30);
DEPTNO AVG(SAL)
---------- ----------
10 2916.66667
SQL> select *
2 from(select empno,ename,sal from emp);
EMPNO ENAME SAL
---------- ---------- ----------
7369 SMITH 800
7499 ALLEN 1600
7521 WARD 1250
7566 JONES 2975
7654 MARTIN 1250
7698 BLAKE 2850
7782 CLARK 2450
7788 SCOTT 3000
7839 KING 5000
7844 TURNER 1500
7876 ADAMS 1100
EMPNO ENAME SAL
---------- ---------- ----------
7900 JAMES 950
7902 FORD 3000
7934 MILLER 1300
已选择14行。
SQL> select empno,ename,sal from emp;
EMPNO ENAME SAL
---------- ---------- ----------
7369 SMITH 800
7499 ALLEN 1600
7521 WARD 1250
7566 JONES 2975
7654 MARTIN 1250
7698 BLAKE 2850
7782 CLARK 2450
7788 SCOTT 3000
7839 KING 5000
7844 TURNER 1500
7876 ADAMS 1100
EMPNO ENAME SAL
---------- ---------- ----------
7900 JAMES 950
7902 FORD 3000
7934 MILLER 1300
已选择14行。
SQL>
- 0赞 · 0采集
-
- 斯巴达汉子 2022-01-31
子查询注意的10个问题
1.子查询语法中的小括号
2.子查询的书写风格----书写风格好,方便阅读
3.可以使用子查询的位置:where,select,having,from后面使用子查询
4.不可以使用子查询的位置:group by后面不可使用子查询
5.强调:from后面的子查询---
6.主查询和子查询可以不是同一张表
7.一般不在子查询中使用排序;但在Top-N分析问题中,必须对子查询排序
8.一般先执行子查询,再执行主查询;但相关子查询例外
9.单行子查询只能使用单行操作符;多行子查询只能使用多行操作符;
10.注意:子查询中是null值问题
*******************************************************
- 0赞 · 0采集
-
- 斯巴达汉子 2022-01-31
SQL> select *
2 from emp
3 where sal > (select sal
4 from emp
5 where ename='SCOTT');
EMPNO ENAME JOB MGR HIREDATE SAL COMM
---------- ---------- --------- ---------- -------------- ---------- ----------
DEPTNO
----------
7839 KING PRESIDENT 17-11月-81 5000
10
- 0赞 · 0采集
-
- 斯巴达汉子 2022-01-30
自连接存在的问题
1.不适合操作大表---数据运算太大,产生的笛卡尔积的大小数据的平方
解决办法:层次查询----一张表查询,本质是单表查询
select level,empno,ename,sal,mgr
from emp
connect by prior empno=mgr
start with mgr is null
order by 1;
connect by 上一层的员工号=老板号
start with mgr is null 一定要从顶层开始查
必须在查询语句中把查询的伪列给显示出来level

*******************************************************
SQL> select count(*) from emp e,emp b;
COUNT(*)
----------
196
SQL> select level,empno,ename,sal,mgr
2 from emp
3 connect by prior empno=mgr
4 start with mgr is null
5 order by 1;
LEVEL EMPNO ENAME SAL MGR
---------- ---------- ---------- ---------- ----------
1 7839 KING 5000
2 7566 JONES 2975 7839
2 7698 BLAKE 2850 7839
2 7782 CLARK 2450 7839
3 7902 FORD 3000 7566
3 7521 WARD 1250 7698
3 7900 JAMES 950 7698
3 7934 MILLER 1300 7782
3 7499 ALLEN 1600 7698
3 7788 SCOTT 3000 7566
3 7654 MARTIN 1250 7698
LEVEL EMPNO ENAME SAL MGR
---------- ---------- ---------- ---------- ----------
3 7844 TURNER 1500 7698
4 7876 ADAMS 1100 7788
4 7369 SMITH 800 7902
已选择14行。
- 0赞 · 0采集
-
- 斯巴达汉子 2022-01-30
自连接
核心:通过别名,将同一张表视为多张表
select e.ename 员工姓名,b.ename 老板姓名,e.empno,e.mgr
from emp e,emp b
where e.mgr=b.empno;
*******************************************************
SQL> select e.ename 员工姓名,b.ename 老板姓名,e.empno,e.mgr
2 from emp e,emp b
3 where e.mgr=b.empno;
员工姓名 老板姓名 EMPNO MGR
---------- ---------- ---------- ----------
FORD JONES 7902 7566
SCOTT JONES 7788 7566
TURNER BLAKE 7844 7698
ALLEN BLAKE 7499 7698
WARD BLAKE 7521 7698
JAMES BLAKE 7900 7698
MARTIN BLAKE 7654 7698
MILLER CLARK 7934 7782
ADAMS SCOTT 7876 7788
BLAKE KING 7698 7839
JONES KING 7566 7839
员工姓名 老板姓名 EMPNO MGR
---------- ---------- ---------- ----------
CLARK KING 7782 7839
SMITH FORD 7369 7902
已选择13行。
- 0赞 · 0采集
-
- 斯巴达汉子 2022-01-30
按照部门统计员工数,要求显示:部门号,部门名称,人数
select d.deptno 部门号,d.dname 部门名称,count(e.empno) 人数
from emp e,dept d
where e.deptno=d.deptno
group by d.deptno,d.dname;
select d.deptno 部门号,d.dname 部门名称,count(e.empno) 人数
from emp e,dept d
where e.deptno=d.deptno
group by d.deptno;
核心:通过外链接,把对于连接条件不成立的记录,仍然包含在最后的结果中
左外连接:当连接条件不成立的时候,等号左边的表仍然被包含
右外连接: 当连接条件不成立的时候,等号右边的表仍然被包含
---- 右外连接示例:叫法和写法左右是反着的
select d.deptno 部门号,d.dname 部门名称,count(e.empno) 人数
from emp e,dept d
where e.deptno(+)=d.deptno
group by d.deptno,d.dname;
select d.deptno 部门号,d.dname 部门名称,count(e.empno) 人数
from emp e,dept d
where e.deptno=d.deptno(+)
group by d.deptno,d.dname;
*******************************************************
SQL> select * from dept;
DEPTNO DNAME LOC
---------- -------------- -------------
10 ACCOUNTING NEW YORK
20 RESEARCH DALLAS
30 SALES CHICAGO
40 OPERATIONS BOSTON
SQL> select d.deptno 部门号,d.dname 部门名称,count(e.empno) 人数
2 from emp e,dept d
3 where e.deptno=d.deptno
4 group by d.deptno,d.dname;
部门号 部门名称 人数
---------- -------------- ----------
10 ACCOUNTING 3
20 RESEARCH 5
30 SALES 6
SQL> select d.deptno 部门号,d.dname 部门名称,count(e.empno) 人数
2 from emp e,dept d
3 where e.deptno=d.deptno
4 group by d.deptno;
select d.deptno 部门号,d.dname 部门名称,count(e.empno) 人数
*
第 1 行出现错误:
ORA-00979: 不是 GROUP BY 表达式
SQL> select count(*) from emp
2 ;
COUNT(*)
----------
14
SQL> select count(*) from dept;
COUNT(*)
----------
4
SQL> select d.deptno 部门号,d.dname 部门名称,count(e.empno) 人数
2 from emp e,dept d
3 where e.deptno(+)=d.deptno
4 group by d.deptno;
select d.deptno 部门号,d.dname 部门名称,count(e.empno) 人数
*
第 1 行出现错误:
ORA-00979: 不是 GROUP BY 表达式
SQL> select d.deptno 部门号,d.dname 部门名称,count(e.empno) 人数
2 from emp e,dept d
3 where e.deptno(+)=d.deptno
4 group by d.deptno,d.dname;
部门号 部门名称 人数
---------- -------------- ----------
10 ACCOUNTING 3
40 OPERATIONS 0
20 RESEARCH 5
30 SALES 6
SQL> select d.deptno 部门号,d.dname 部门名称,count(e.empno) 人数
2 from emp e,dept d
3 where e.deptno=d.deptno(+)
4 group by d.deptno,d.dname;
部门号 部门名称 人数
---------- -------------- ----------
10 ACCOUNTING 3
20 RESEARCH 5
30 SALES 6
- 0赞 · 0采集
-
- 斯巴达汉子 2022-01-30
链接条件是不等号,不等值连接
select e.empno,e.ename,e.sal,s.grade
from emp e,salgrade s
where e.sal between s.losal and s.hisal;
select e.empno,e.ename,e.sal,s.grade
from emp e,salgrade s
where e.sal between s.hisal and s.losal;
*******************************************************
SQL> select * from salgrade;
GRADE LOSAL HISAL
---------- ---------- ----------
1 700 1200
2 1201 1400
3 1401 2000
4 2001 3000
5 3001 9999
SQL> select e.empno,e.ename,e.sal,s.grade
2 from emp e,salgrade s
3 where e.sal between s.losal and s.hisal;
EMPNO ENAME SAL GRADE
---------- ---------- ---------- ----------
7369 SMITH 800 1
7900 JAMES 950 1
7876 ADAMS 1100 1
7521 WARD 1250 2
7654 MARTIN 1250 2
7934 MILLER 1300 2
7844 TURNER 1500 3
7499 ALLEN 1600 3
7782 CLARK 2450 4
7698 BLAKE 2850 4
7566 JONES 2975 4
EMPNO ENAME SAL GRADE
---------- ---------- ---------- ----------
7788 SCOTT 3000 4
7902 FORD 3000 4
7839 KING 5000 5
已选择14行。
SQL> select e.empno,e.ename,e.sal,s.grade
2 from emp e,salgrade s
3 where e.sal between s.highsal and s.losal;
where e.sal between s.highsal and s.losal
*
第 3 行出现错误:
ORA-00904: "S"."HIGHSAL": 标识符无效
SQL> select e.empno,e.ename,e.sal,s.grade
2 from emp e,salgrade s
3 where e.sal between s.hisal and s.losal;
未选定行
- 0赞 · 0采集
-
- 斯巴达汉子 2022-01-30
SQL> select e.empno,e.ename,e.sal,d.dname
2 from emp e,dept d
3 where e.deptno=d.deptno;
EMPNO ENAME SAL DNAME
---------- ---------- ---------- --------------
7782 CLARK 2450 ACCOUNTING
7839 KING 5000 ACCOUNTING
7934 MILLER 1300 ACCOUNTING
7566 JONES 2975 RESEARCH
7902 FORD 3000 RESEARCH
7876 ADAMS 1100 RESEARCH
7369 SMITH 800 RESEARCH
7788 SCOTT 3000 RESEARCH
7521 WARD 1250 SALES
7844 TURNER 1500 SALES
7499 ALLEN 1600 SALES
EMPNO ENAME SAL DNAME
---------- ---------- ---------- --------------
7900 JAMES 950 SALES
7698 BLAKE 2850 SALES
7654 MARTIN 1250 SALES
- 0赞 · 0采集
-
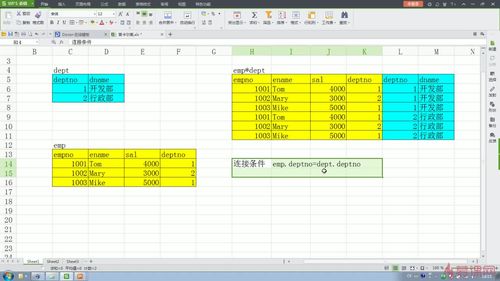
- 斯巴达汉子 2022-01-30
连接条件可以避免使用笛卡尔乘积的全集
- 0赞 · 0采集
-
- 斯巴达汉子 2022-01-30
多表查询
1、什么是多表查询?
2、笛卡尔集
3、等值连接
4、不等值连接
5、外连接
6、自连接
7、层次查询
- 0赞 · 0采集
-
- 斯巴达汉子 2022-01-30
ttitle col 15 '我的报表' col 35 sql.pno
col deptno heading 部门号
col job heading 职位
col sum(sal) heading 工资总额
break on deptno skip 1
ttitle col 15 '我的报表' col 35 sql.pno
表示标题前空15列,后空35列
sql.pno 表示报表的第一页,第二页
break on deptno skip 1
get sql文件,读取sql文件
@sql文件,执行sql文件
*******************************************************
SQL> get e:\temp\report.sql
1 ttitle col 15 '我的报表' col 35 sql.pno
2 col deptno heading 部门号
3 col job heading 职位
4 col sum(sal) heading 工资总额
5* break on deptno skip 1
SQL> @e:\temp\report.sql
SQL> select deptno,job,sum(sal) from emp group by rollup(deptno,job);
我的报表 1
部门号 职位 工资总额
---------- --------- ----------
10 CLERK 1300
MANAGER 2450
PRESIDENT 5000
8750
20 CLERK 1900
ANALYST 6000
MANAGER 2975
10875
30 CLERK 950
MANAGER 2850
SALESMAN 5600
9400
29025
已选择13行。
SQL> set pagesize 10
SQL> select deptno,job,sum(sal) from emp group by rollup(deptno,job);
我的报表 1
部门号 职位 工资总额
---------- --------- ----------
10 CLERK 1300
MANAGER 2450
PRESIDENT 5000
8750
20 CLERK 1900
我的报表 2
部门号 职位 工资总额
---------- --------- ----------
20 ANALYST 6000
MANAGER 2975
10875
30 CLERK 950
MANAGER 2850
我的报表 3
部门号 职位 工资总额
---------- --------- ----------
30 SALESMAN 5600
9400
29025
已选择13行。
- 0赞 · 0采集
-
- 斯巴达汉子 2022-01-30

select deptno,job,sum(salary) from users group by deptno,job;
+
select deptno,sum(sal) from emp group by deptno
+
select sum(sal) from emp
=
select deptno,job,sum(sal) from emp group by rollup(deptno,job);
group by rollup---叫group by语句的增强------在报表中用的比较多
group by rollup(a,b)
等价于
group by a,b
+
group by a
+
group by null
break on deptno skip 2
相同部门号仅仅显示一次,
不同的部门号之间跳过2行
set pagesize 30 ---让每列显示30条数据
*******************************************************
SQL> select deptno,job,sum(sal) from emp group by rollup(deptno,job);
DEPTNO JOB SUM(SAL)
---------- --------- ----------
10 CLERK 1300
10 MANAGER 2450
10 PRESIDENT 5000
10 8750
20 CLERK 1900
20 ANALYST 6000
20 MANAGER 2975
20 10875
30 CLERK 950
30 MANAGER 2850
30 SALESMAN 5600
DEPTNO JOB SUM(SAL)
---------- --------- ----------
30 9400
29025
已选择13行。
SQL> break on deptno skip 2
SQL> set pagesize 30
SQL> select deptno,job,sum(sal) from emp group by rollup(deptno,job);
DEPTNO JOB SUM(SAL)
---------- --------- ----------
10 CLERK 1300
MANAGER 2450
PRESIDENT 5000
8750
20 CLERK 1900
ANALYST 6000
MANAGER 2975
10875
30 CLERK 950
MANAGER 2850
SALESMAN 5600
9400
29025
已选择13行。
- 0赞 · 0采集
-
- 斯巴达汉子 2022-01-30
分组函数的嵌套
示例:求部门平均工资的最大值
*******************************************************
SQL> select max(avg(sal))
2 from emp
3 group by deptno;
MAX(AVG(SAL))
-------------
2916.66667
- 0赞 · 0采集


