-

- Styxmale 2026-02-10
选择合适的数据类型。



- 0赞 · 0采集
-
- Styxmale 2026-02-10
删除哪些没有使用的索引

- 0赞 · 0采集
-
- Styxmale 2026-02-10
重复索引

冗余索引



- 0赞 · 0采集
-
- Styxmale 2026-02-10
判断离散度的sql语句

- 0赞 · 0采集
-
- Styxmale 2026-02-10
111111111111111111111111


缺点:要求主键是排列有序的

- 0赞 · 0采集
-
- Styxmale 2026-02-10
优化之前的sql

优化之后的sql

- 0赞 · 0采集
-
- Styxmale 2026-02-10
111111111111111111111111

- 0赞 · 0采集
-
- Styxmale 2026-02-10
mysql优化。。。。
const是主键查找,eq_reg是范围查找,ref常见于连接的查询中


- 0赞 · 0采集
-

- 涓涓细语_qwxyz0 2024-11-18
数据库优化


- 0赞 · 0采集
-

- 慕粉3678604 2024-02-29
数据库优化的目的是什么?
避免错误页面的发生
1.请求数据库服务器超时,会发生数据库的内部错误
2.慢sql,造成页面无法加载
3.阻塞,数据无法提交
增加数据库的稳定性
很多都是因为由于低效的查询引起的
优化用户体验
流畅页面的访问速度
良好的网站功能体验
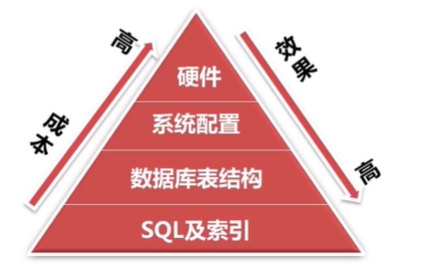
数据库可以从哪几个方面优化呢?
- 0赞 · 0采集
-

- weixin_慕函数0407600 2023-12-06
max
io就相当高
建索引
count(*) 全部行
count(id)不包括null
select count (code='18') as 'good',count(code='19')as 'hahah' from study
- 0赞 · 0采集
-
- weixin_慕函数0407600 2023-12-05
哪些查询需要优化:
mysql中有个慢查询日志进行sql监控
- 0赞 · 0采集
-
- weixin_慕函数0407600 2023-12-05
目的:
数据库连接超时
慢查询:出现页面无法加载
阻塞:内部锁的原因,轻则影响性能,还会影响业务,有锁超时,超过时间就会被回滚
优化:
sql及索引优化:结构良好的sql,有效适量的索引
表结构设计:减少冗余
系统配置:tcp文件数/打开文件数限制/安全性限制,没查询一个表就会打开一个文件,打开文件数
硬件:cpu。更快的io 内存越大可能越好,cpu不一定越多越好,对核数也有限制;io级别的选择,io并不能减少锁的机制,硬件是成本最高效果最差的
- 1赞 · 1采集
-

- heshui 2023-11-23
- 这位老师的英文不咋滴,中文也不咋地啊
- 0赞 · 0采集
-

- AppMan 2023-02-20
数据库优化,SQL及索引优化效果最高,成本最低。

- 0赞 · 0采集
-
- AppMan 2023-02-17
选择合适类型做数据库索引



- 0赞 · 0采集
-
- AppMan 2023-02-17

索引并不是越多越好,作为主键的字段不要再做索引。

- 0赞 · 0采集
-
- AppMan 2023-02-17
SQL索引优化

- 0赞 · 0采集
-
- AppMan 2023-02-17
可优化的方面:

SQL及索引优化:

- 0赞 · 0采集
-

- pingwang 2022-07-23
测试
- 0赞 · 0采集
-

- Ganjr 2022-07-10
打开文件数的限制,可以使用 ulimit-a 查看目录的各位限制,可以修改 /etc/ security/ limits.conf文件,增加以下内容以修改打开文件数量的限制 soft nofile 65535 hard nofile 65535
除此之外最好在 MySQL 服务器上关闭 iptables, selinux 等防火墙软件。
- 0赞 · 0采集
-
- Ganjr 2022-07-10
数据库是基于操作系统的,目前大多数 MySQL 都是安装在 Linux 系统之上,所以对于操作系统的一些参数配置也会影响到 MySQL 的性能,下面就列出一些常到的系统配置。
网络方面的配置,要修改 /etc/ sysctl.conf 文件
#增加 tcp 支持的队列数
net.ipv4.tcp_max_syn_backlog = 65535
#减少断开连接时,资源回收
net.ipv4.tcp_max_tw_buckets = 8000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_fin_timeout = 10
- 0赞 · 0采集
-
- Ganjr 2022-07-10
常用的水平拆分方法为:
对 customer id 进行 hash 运算,如果要拆分成 5 个表则使用 mod(customer_id,5) 取出 0-4 个值
针对不同的 hashID 把数据存到不同的表中。
挑战:
跨分区表进行数据查询
统计及后台报表操作
- 0赞 · 0采集
-
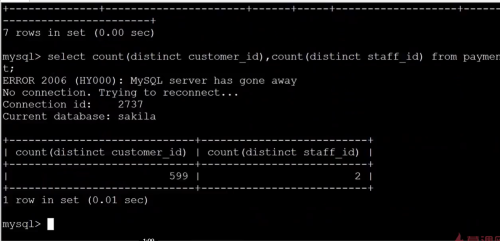
- Ganjr 2022-07-10
表的水平拆要是为了解决单表的数据量过大的问题,水平插分的表每一个表的结构都是完成一致的。以下面的 payment 表为例

- 0赞 · 0采集
-
- Ganjr 2022-07-10
CREATE TABLE `film` ( `film_id` SMALLINT(5) UNSIGNED NOT NULL AUTO_INCREMENT, `title` VARCHAR(255) NOT NULL, `description` TEXT, `release_year` YEAR(4) DEFAULT NULL, `language_id` TINYINT(3) UNSIGNED NOT NULL, `original_language_id` TINYINT(3) UNSIGNED DEFAULT NULL, `rental_duration` TINYINT(3) UNSIGNED NOT NULL DEFAULT'3', `rental_rate` DECIMAL(4,2) NOT NULL DEFAULT'4.99', `length` SMALLINT(5) UNSIGNED DEFAULT NULL, `replacement_cost` DECIMAL(5,2) NOT NULL DEFAULT '19.99', `rating` VARCHAR(5) DEFAULT'G', `special_features` VARCHAR (10) DEFAULT NULL, `last_update` TIMESTAMP, PRIMARY KEY(`film_id`))

CREATE TABLE file_text ( `film_id` SMALLINT (5) UNSIGNED NOT NULL, `title` VARCHAR(255) NOT NULL, `description` TEXT primary key(film_id) ) engine = innodb
- 0赞 · 0采集
-
- Ganjr 2022-07-10
所谓的垂直拆分,就是把原来一个有很多列的表拆分成多个表,这解决了表的宽度问题。通常垂直拆分可以按以下原则进行:
把不常用的字段单独存放到一个表中。
把大字段独立存放到一个表中。
把经常一起使用的字段放到一起。
- 0赞 · 0采集
-
- Ganjr 2022-07-10
思考:反范式化后再查询订单信息
SELECT a.用户名,a.电话,a.地址,a.订单ID, a.订单价格 FROM `订单表` a
- 0赞 · 0采集
-
- Ganjr 2022-07-10
对下面的表进行反范式化后

- 0赞 · 0采集
-
- Ganjr 2022-07-10
思考:如何查询订单信息?
SELECT b.用户名,b.电话,b.地址,a.订单ID, SUM(c.商品价价*c.商品数量)as 订单价格 FROM `订单表` a JOIN `用户表` b ON a.用户ID=b.用户ID JOIN `订单商品表` c ON c.订单ID=b.订单ID GROUP BY b.用户名,b.电话,b.地址,a.订单ID
- 0赞 · 0采集
-
- Ganjr 2022-07-10
反范式化是指为了查询效率的考虑把原本符合第三范式的表适当的增加冗余,以达到优化查询效率的目的,反范式化是一种以空间来换取时间的操作。

- 0赞 · 0采集







