-

- 慕移动9059126 2026-04-10
Openai Embeddings模型
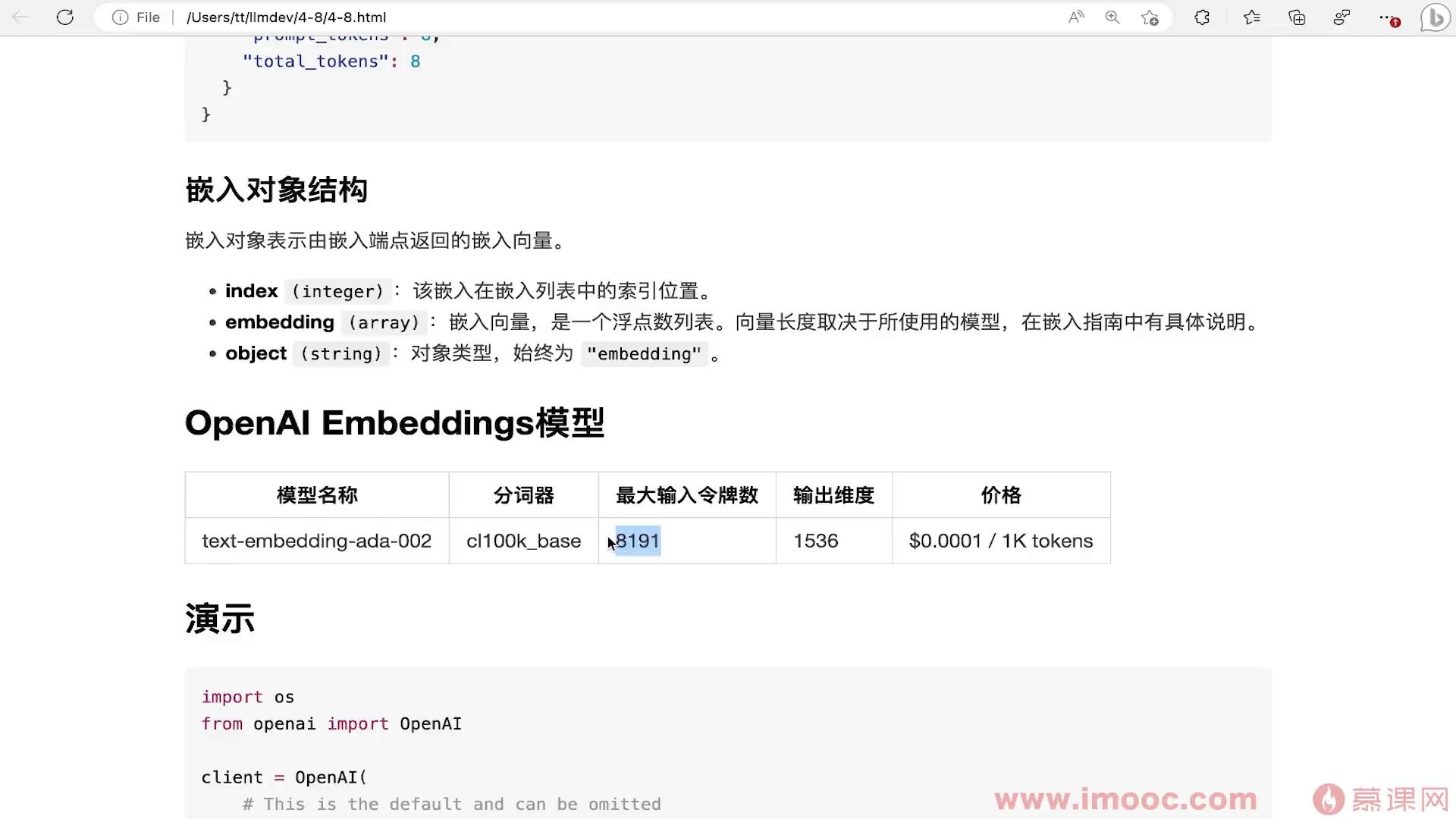
- 0赞 · 0采集
-
- 慕移动9059126 2026-04-10
OpenAI SDK 使用
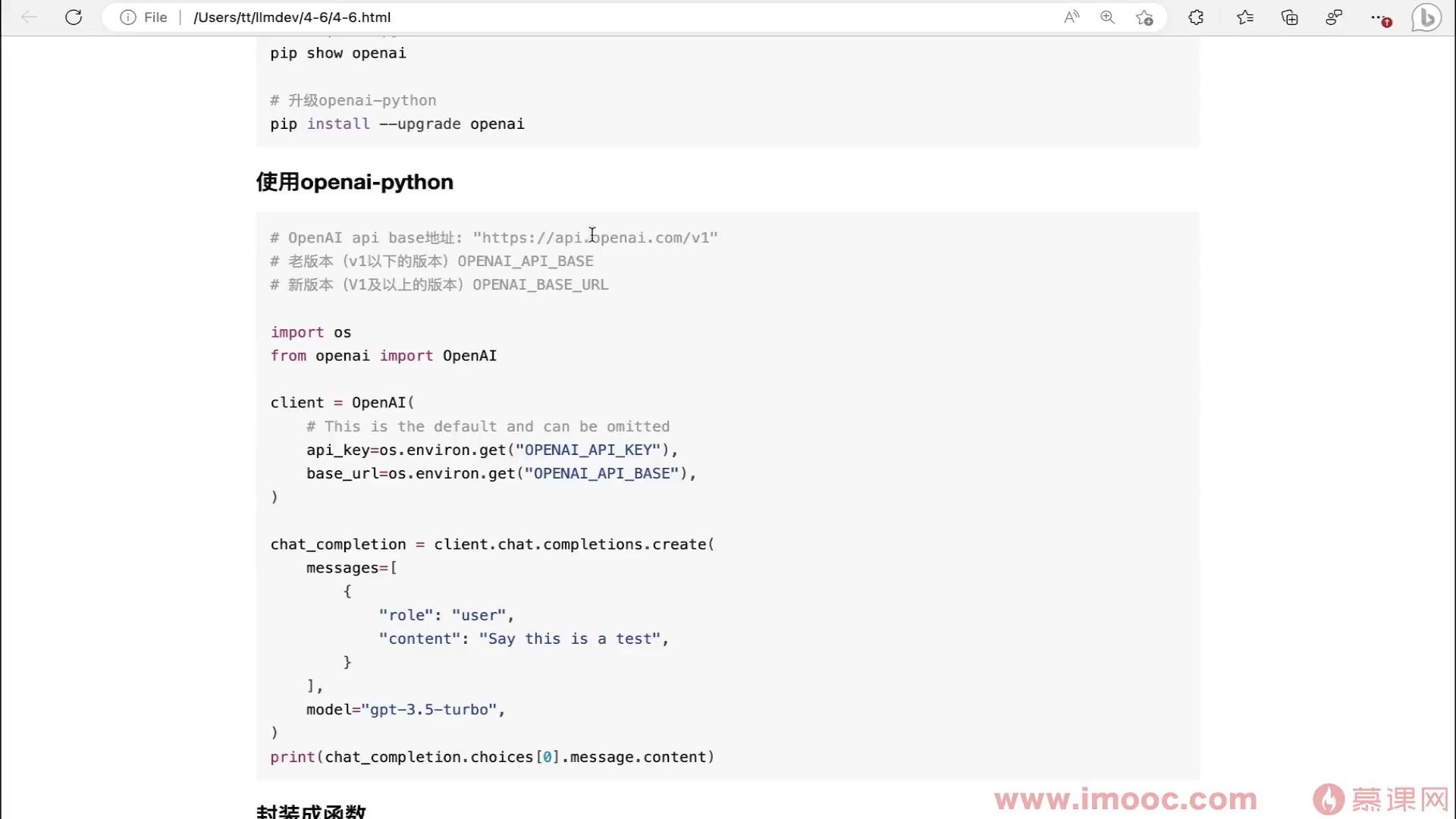
- 0赞 · 0采集
-
- 慕移动9059126 2026-04-10
window设置环境变量
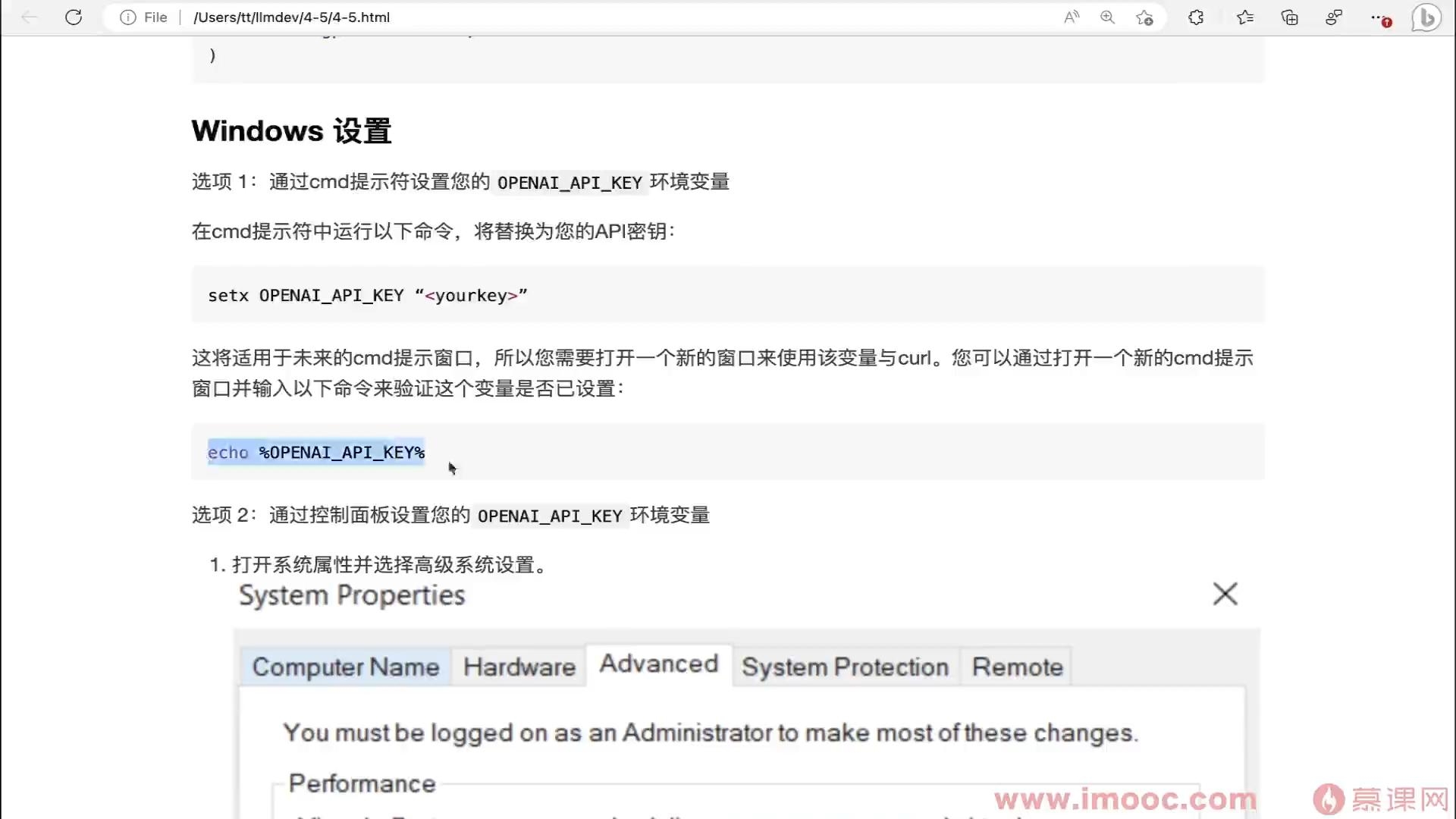
- 0赞 · 0采集
-
- 慕移动9059126 2026-04-09
gpt4free项目
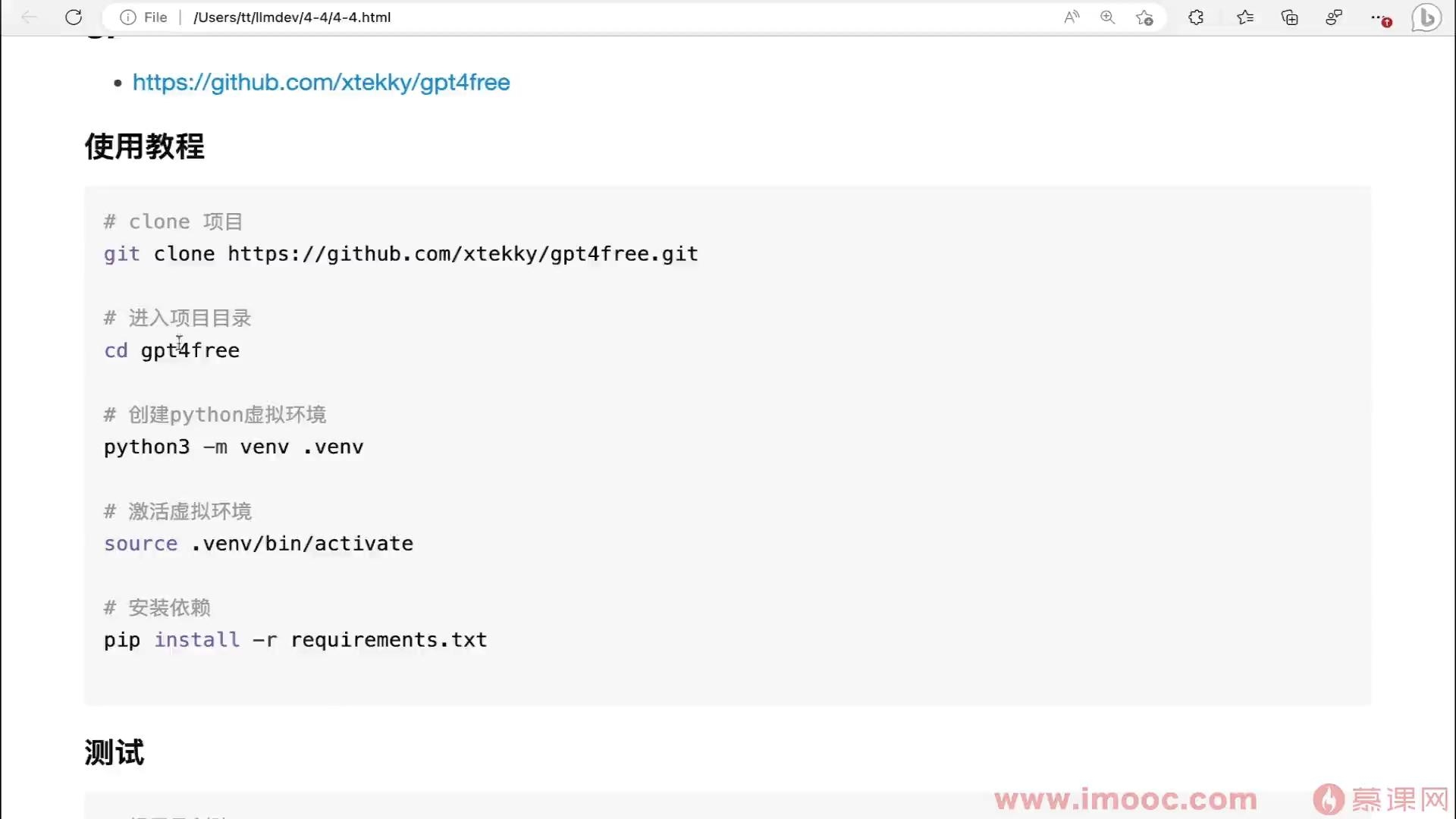
- 0赞 · 0采集
-
- 慕移动9059126 2026-04-09
OpenAI代理服务商,免费回去OpenAI api key
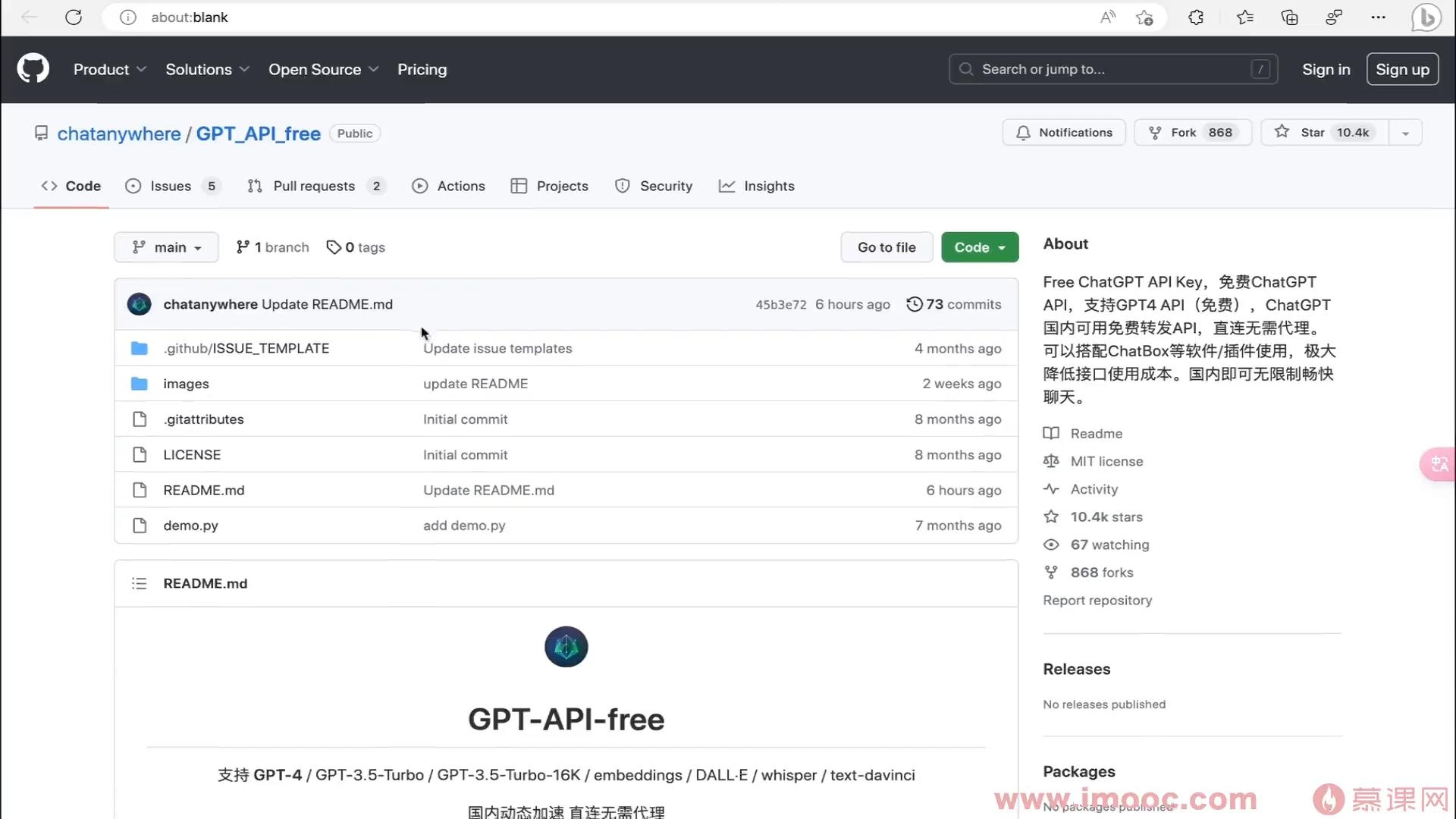
- 0赞 · 0采集
-
- 慕移动9059126 2026-04-09
OpenAI代理,支持有key但是无法访问OpenAI的情况
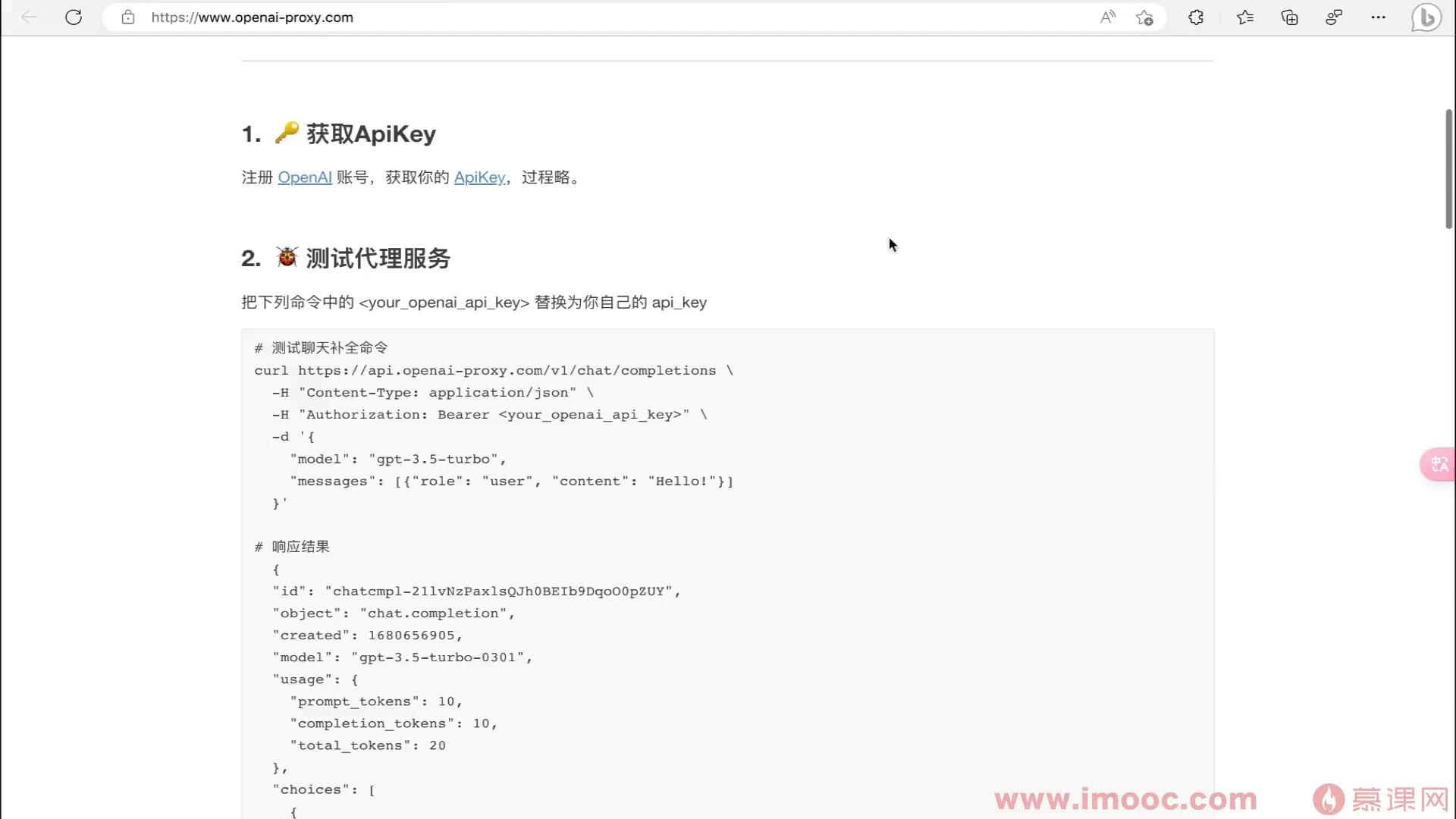
- 0赞 · 0采集
-

- 超人归来2020 2025-08-11
- Embedding大模EmbeddingsEmbeddings是文本的数值表示,可用于衡量两段文本之间的相关性。目前的第二代Embedding模型 text-ewbedding稠
- 0赞 · 0采集
-

- 慕粉1249414174 2025-03-16
从互联网获取数据
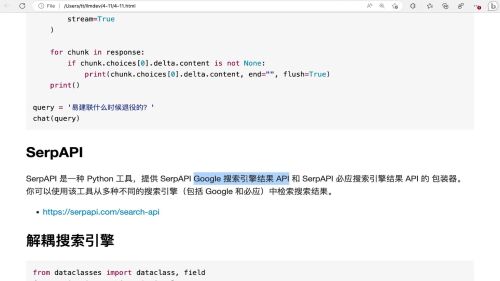
- 0赞 · 0采集
-
- 慕粉1249414174 2025-03-16
创建Python虚拟环境
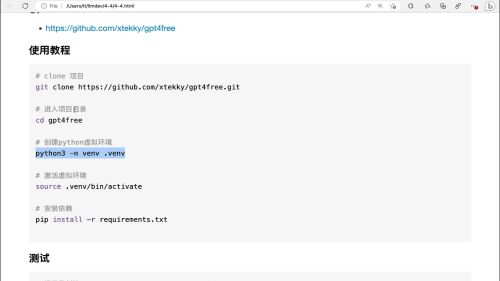
- 0赞 · 0采集
-
- 慕粉1249414174 2025-03-16
免费的chatgpt网站
- 0赞 · 0采集
-

- 一不不 2025-03-03
流式VS非流式对比介绍
非流式输入的问题:
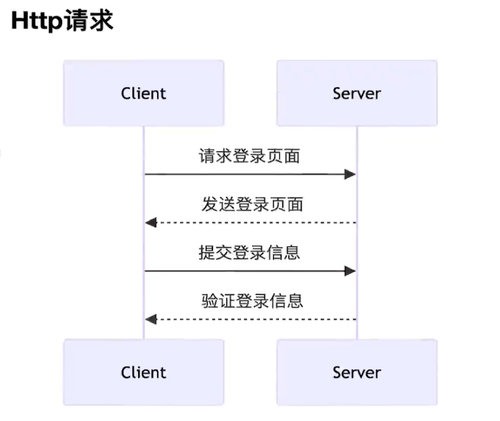
当你从OpenAI请求一个完成内容时,如果你在生成长的完成内容,等待响应可能需要几秒钟的时间。影响用户体验。流式:
http请求:一问一答模式
SSE
服务其发送事件(Server-sent events ,简称SSE),服务器向客户端推送数据,客户端通过事件监听器接收数据。
严格地说,Http协议无法做到服务器主动推送信息,但是,有一种变通方法,就是服务器向客户端声明,接下来要发送的是流信息(streaming)。
也就是说,发送的不是一次性的数据包,而是一个数据流,会连续不断地发送过来。这时,客户端不会关闭连接,会一直等着服务器发过来的新的数据流,视频播放就是这样的例子。本质上,这种通信就是以流信息的方式,完成一次用时很长的下载。
向OpenAI请求流式输出
1、要流式传输完成内容,请在调用聊天完成或完成端点时设置stream=True.
2、使用openai-python库解析OpenAI流式请求的缺点:
1、内容审查问题。请注意,在生产应用程序中使用stream=True会使内容的审核变得更加困难,因为部分完成内容可能更难评估。
向C端用户提供服务的时候,需要注意内容审查问题。
2、无usage字段。流式响应的另一个小缺点是响应不在包括usage字段,告诉你消耗了多少令牌。在接收和组合所有响应后,你可以使用tiktoken自己计算这一点总结:
简单来说:这种流式传输方式使得客户端在长内容生成过程中无需等待整个内容完成,就可以逐步接受到生成的内容,从而提高了响应速度和用户体验。- 0赞 · 0采集
-
- 一不不 2025-03-03
了解Embeddings
什么是Embeddings?(收费)
Embeddings(嵌入)在自然语言处理(NLP)中起着至关重要的作用,他们的主要目的是将高维、离散的文本数据(如单词或短语)转换为低维、连续的向量表示。这些向量不仅编码了词本身的含义,还捕捉到了词语之间的语义和句法关系。通过Embeddings,原本难以直接处理的文本数据可以被机器学习模型理解和操作。
它就是将 【不可计算】【非结构化】的词转化为【可计算】【结构化】的向量。
把文本数据翻译成机器能识别的语言为什么需要将词或句子转成Embeddings?
1、保留语义信息
2、简化模型输入
3、便于计算和优化
4、下游任务泛化能力Embeddings在OpenAI中的使用
1、创建嵌入向量:通过调用OpenAI的API,您可以创建一个代表输入文本的嵌入向量。
2、请求方法及URL
https://api.openai.com/v1/embeddings
3、请求参数:
input:必填
model:必填 text-embedding-ada-002应用:
1、搜索(通过与查询字符串的相关性对结果进行排序)
2、聚类(根据相似性将文本字符串分组)
3、推荐(推荐具有相关文本字符串的项目)
3、异常检测(识别与其他项关联度较低的离群点)
4、多样性测量(分析相似性分布)
5、分类(根据最相似标签对文本字符串进行分类)- 0赞 · 0采集
-
- 一不不 2025-02-12
学会给OpenAI大模型下达指令
Comletions API
补全,即补全用户输入的内容。它允许用户输入一段文本(prompt),然后由AI模型自动生成接下来的文本内容。
也叫补全接口或完成接口
应用
Chat Completions API
特性:
1、对话历史管理:能记住之前的对话内容,以便生成连贯的回答
2、适应性回复:模型会根据对话的上下文来调整其回答的风格和内容
3、更加自然的交流:生成的文本更符合人类的聊天习惯,包括非正式的语言、俚语等。- 0赞 · 0采集
-
- 一不不 2025-02-11
OpenAI大模型家族介绍
模型概览:
多模态大模型:具有多种能力的大模型
文本大模型:文生文
视觉大模型:文生图
语音大模型:文转语音,或语音转文本
Embedding大模型:将文本转换成浮点数,方便计算机理解文本的含义。常用于比较两段文本的相似度。
审查大模型:常用于检查文本是否包含敏感信息,或者文本是否违背人类的价值观。多模态大模型
GPT-4是一个大型多模态模型(接受文本或图像输入并输出文本),它可以比我们以前的任何模型都更准确地解决难题,这得益于它更广泛的通用知识和更高级的推理能力。收费使用,针对聊天进行了优化。
多语言能力应用:
文本大模型:GPT-3.5
推荐使用GPT-3.5-turbo而不是其他GPT-3.5模型,因为它成本更低,性能更优
视觉大模型:DALL*E
语音大模型:TTS、Whisper
Embedding大模型:Embeddings是文本的数值表示,可以用于衡量两段文本之间的相关性。Embdedding对于搜索、聚类、推荐、异常检测和分类任务很有用。
审查大模型:Moderation- 0赞 · 0采集
-
- 一不不 2025-02-11
OpenAI大模型家族介绍
不能访问Open AI怎么办?
了解Embeddings
流式VS非流式对比介绍
项目实战
- 0赞 · 0采集
-

- 程序小工 2024-09-01
流式输出的场景:
需要大模型执行一段时间的情况,避免用户等待,可以一点一点的输出
非流式:

使用的是http请求,不能主动向客户端推送数据
流式:----SSE:服务器发送事件


响应结构:



非流式响应结构:


object的结构差异:
非流式=chat.completion
流式=chat.completion.chunk
choices的结构差异:
非流式=index、message.role、message.content、logprobs、finish_reason
流式=index、delta.role、delta.content、finish_reason
usage差异:
非流式=prompt_tokens、completion_tokens、total_tokens
流式=没有该参数


逐行读取流式返回结果:

bit类型=>字符串: line.decode('utf-8').lstrip('data: ')
字符串=>字典(json) : json.loads()
print使用知识点:
默认输出后会带换行符,如果不需要换行,需要执行换行符类型
print(str, end=''): 不换行直接输出
openai-python库: 使用支持SSE协议的已有客户端库,简化实现逻辑

处理返回结果



- 0赞 · 1采集
-
- 程序小工 2024-08-31
embeddings 是什么和有什么用

怎么用:

使用示例:

响应:

响应参数说明:

常用模型:

模型使用代码

应用场景:

- 0赞 · 0采集
-

- shineLover 2024-08-28
SerpAPI是一种 Pyhon 工具,提供 SerpAPI Google 搜索引擎结果 AP|和 SerpAPI 必应搜索引擎结果 API 的 包装器你可以使用该工具从多种不同的搜索引擎(包括 Google 和必应)中检索搜索结果。
- 0赞 · 0采集
-
- shineLover 2024-08-28
不输出换行符:print("输出", end='')
使用openai-python库
流式输出时,可设置滑动窗口实现内容审查
使用tiktoken库计算token消耗
- 0赞 · 0采集
-
- shineLover 2024-08-27
角色:
system
user
assistant
- 0赞 · 0采集
-
- shineLover 2024-08-27
openai-python
pip install openai
- 0赞 · 0采集
-
- shineLover 2024-08-27
环境变量设置KEY
- 0赞 · 0采集
-
- shineLover 2024-08-27
1个token≈4个英文字符
1个token≈3/4个单词
100个token≈75个单词
- 0赞 · 1采集
-
- shineLover 2024-08-27
OPENAI大模型家族:
多模态大模型:
GPT-4
GPT-4 Turbo版{剪枝和蒸馏后的版本}
文本大模型
GPT-3.5
视觉大模型
DALL·E
语音大模型
TTS
Whisper
Embedding大模型
text-embedding-ada-002
审查大模型
Moderation
- 1赞 · 0采集
-
- 程序小工 2024-08-19
一、输入约束


二、输出约束
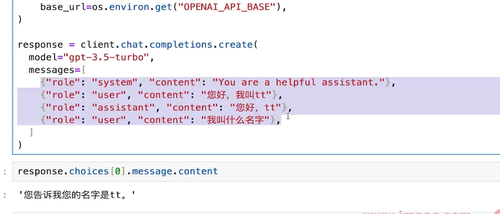
一般的响应格式: response.choices[0].message.content


通过messages角色设定的内容,告诉大模型之前的数据
- 0赞 · 0采集
-
- 程序小工 2024-08-19
openAI 的api调用

- 0赞 · 0采集
-
- 程序小工 2024-07-31
推荐项目
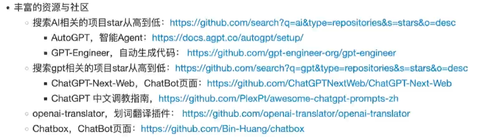
AutoGPT: https://github.com/Significant-Gravitas/AutoGPT
GPT-Engineer: https://github.com/gpt-engineer-org/gpt-engineer
ChatGPT-Next-Web: https://github.com/ChatGPTNextWeb/ChatGPT-Next-Web
- 1赞 · 1采集





