-

- 青山烟雨青衫客 2024-11-09
词频-你文件频率(TF-IDF)
缺点:
词频(TF)和逆文件频率(IDF)的统计和计算都直接从语料统计得出,当增加语料的时候,TF和IDF往往需要重新计算,无法增量更新,每次添加语料,需要重新计算词频。
没有考虑特征词的位置因素对文本的区分度,词条出现在文档的不同位置时,对区分度贡献大小是不一样的。
按照传统TF-IDF,往往一些生僻词的IDF(反文档频率)会比较高、因此这些生僻词往往会被误认为是文档关键词。
- 0赞 · 0采集
-
- 青山烟雨青衫客 2024-11-09
One-Hot缺点:
1.词通常很多,几十万个词,那就需要句子长度x几十万的矩阵才能表示这个句子
2.这种方法效率低下,矩阵包含很多零
3.无法表达相似性
4.新加一个词我们需要重新计算
- 0赞 · 0采集
-
- 青山烟雨青衫客 2024-11-09
One-Hot理解:
先给句子分词,分词组从词表,词表有索引,然后编码形成矩阵
- 0赞 · 0采集
-
- 青山烟雨青衫客 2024-11-09
文本表示方法:One-Hot、TF-IDF、Word2Vec
- 0赞 · 0采集
-

- 落日映江红 2024-09-10
缺点:
浪费空间,不利于计算
体现不出单词间的关系
优点:
长度远小于字典长度
向量加爵代表相似度
可以增量添加新词
- 0赞 · 0采集
-
- 落日映江红 2024-09-10
一个朴素的想法就是,我们把One-Hot中0的位置也利用起来,并且用浮点数来表示词特性,这样我们就可以用固定的,较小的维度来表达海量的信息
- 0赞 · 0采集
-
- 落日映江红 2024-09-09
IDF 是逆文件频率,表示关键词的普遍程度。
如果包含词条i的文档越少,IDF越大,则说明该词条具有很好的类别区分能力。
某一特定词语的IDF,可以由总文件数目除以包含该词语的文件数目,再将得到的商取对数得到。
- 0赞 · 0采集
-

- 丶丨Coud 2024-03-22
不懂的名词儿:
卷积
过拟合
loss
激活函数
embedding层
- 0赞 · 0采集
-

- 慕慕3476723 2023-10-17
试试笔记功能,调阈值
- 0赞 · 0采集
-

- weixin_慕的地1184413 2023-02-25
老师,代码在哪里呀?4章 和5 章
- 0赞 · 1采集
-
- weixin_慕虎4452475 2023-01-02
建模区别:

- 0赞 · 0采集
-

- 慕后端8096530 2022-08-18
1111

- 0赞 · 0采集
-
- 慕后端8096530 2022-08-18
1
 111111
111111- 0赞 · 0采集
-
- 慕后端8096530 2022-08-18
22222
- 0赞 · 0采集
-

- moocer9527 2022-07-27
github

- 0赞 · 0采集
-
- moocer9527 2022-07-27
独热编码的缺点

- 0赞 · 0采集
-
- moocer9527 2022-07-27
独热编码(one-hot)

- 0赞 · 0采集
-
- moocer9527 2022-07-27
文本表示方法

- 0赞 · 0采集
-
- moocer9527 2022-07-27
文本分类任务描述

- 0赞 · 0采集
-
- moocer9527 2022-07-27
文本分类任务描述

- 0赞 · 1采集
-
- moocer9527 2022-07-27
应用——知识点抽取
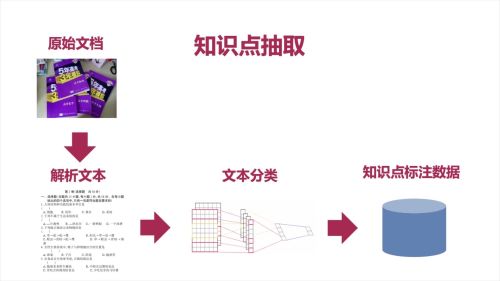
- 0赞 · 0采集
-
- moocer9527 2022-07-27
应用-----非结构化信息提取

- 0赞 · 1采集
-
- moocer9527 2022-07-27
应用--意图识别

- 0赞 · 0采集
-
- moocer9527 2022-07-27
应用,情感分析

- 0赞 · 0采集
-
- moocer9527 2022-07-27
文本分类任务描述

- 0赞 · 0采集
-

- 小风满楼 2021-11-30
我的笔记笔记笔记,自然期刊
- 0赞 · 0采集
-
- 小风满楼 2021-11-30
我的笔记笔记笔记,自然自然
- 0赞 · 2采集
-
- 小风满楼 2021-11-30
我的笔记笔记笔记,自然
- 0赞 · 0采集
-
- 小风满楼 2021-11-30
我的笔记笔记笔记,自然
- 0赞 · 0采集
-
- 小风满楼 2021-11-30
我的笔记啊啊啊 我的笔记啊啊啊 我的笔记啊啊啊 我的笔记啊啊啊 我的笔记啊啊啊
- 0赞 · 0采集








