-

- 慕尼黑7553735 2022-03-14
n=100
while n<999:
i=int(n/100)
j=int(n/10%10)
k=int(n%10)
result=i*i*i+j*j*j+k*k*k
if n==result:
print(n)
n=n+1
print("所有的水仙花数")- 0赞 · 0采集
-
- 慕尼黑7553735 2022-03-12
.append(数据)#函数,追加一个元素放到列表最后
books.append("儒林外史")#插到最后一排
.insert(索引,数据)#插入一个元素到列表相应位置
books.append(4,"儒林外史")#插到第5个
books[4]='儒林外史"#更新一个数据,列表[4]=新数据
列表.pop(索引)#删除数据
books.pop(4)#删除books第5个数据
- 0赞 · 0采集
-
- 慕尼黑7553735 2022-03-12
if 判断条件 :
python语句1
elif 判断条件 :
python语句2
else:
python语句3
多重分支,前面的条件如果符合一条,后面的判断都会取消
- 0赞 · 0采集
-
- 慕尼黑7553735 2022-03-12
not or and
not级别最高
or次之
and最低
not(),先判断()里,如果是True,结果就是Flase
- 0赞 · 0采集
-

- 梦藏欢 2021-08-22
- 列表中多个数据之间,用半角逗号隔开
- 0赞 · 0采集
-
- 梦藏欢 2021-08-22
- 括号()里的优先运算
- 0赞 · 0采集
-
- 梦藏欢 2021-08-22
print不换行

- 0赞 · 0采集
-

- 谁知道猪的幸福 2021-05-07
# coding=utf-8
movies = []
mov = {"year":1902,"title":"月球之旅","director":"乔治斯·梅利斯","description":"历史上第一部科幻电影"}
movies.append(mov)
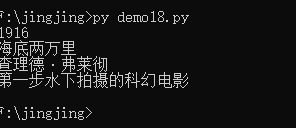
mov1 = {"year":1916,"title":"海底两万里","director":"查理德·弗莱彻","description":"第一步水下拍摄的科幻电影"}
movies.append(mov1)
y = 1916
for m in movies:
if y == m["year"]:
print(m["year"])
print(m["title"])
print(m["director"])
print(m["description"])
- 0赞 · 0采集
-
- 谁知道猪的幸福 2021-05-07
# coding=utf-8
col1 = ["玩具","饮料","唇彩"]
col2 = ["手办","卡片","唇彩"]
col3 = ["卡片","饮料","手套"]
row = [col1,col2,col3]
for col in row:
for box in col:
print(box)
print("==============")

- 0赞 · 0采集
-
- 谁知道猪的幸福 2021-05-07
#while
# coding=utf-8
n = 100
while n < 1000:
i = int(n/100)
j = int(n/10)%10
k = n %10
if n == i*i*i+j*j*j+k*k*k:
print(n,end="")
print("是水仙花数")
n = n+1

- 0赞 · 0采集
-
- 谁知道猪的幸福 2021-05-07
# coding=utf-8
for n in range(100,1000):
i = int(n/100)
j = int(n/10)%10
k = n %10
if n == i*i*i+j*j*j+k*k*k:
print(n,end="")
print("是水仙花数")

- 0赞 · 0采集
-
- 谁知道猪的幸福 2021-05-07
#range 左闭右开
# coding=utf-8
for i in range(10,15):
print(i)

- 0赞 · 0采集
-
- 谁知道猪的幸福 2021-05-07
# coding=utf-8
books = ["三国演义","水浒传","西游记"]
for book in books:
if book != "西游记":
print(book)

- 0赞 · 0采集
-
- 谁知道猪的幸福 2021-05-07
# coding=utf-8
i = 1
res = 3
while i <= 10 :
print(res)
res = res * 3
i = i + 1
print("循环结束")

- 0赞 · 0采集
-
- 谁知道猪的幸福 2021-05-07
# coding=utf-8
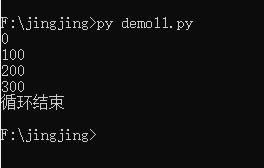
i= 0
while i < 4:
print(i*100)
i = i+1
print("循环结束")
- 0赞 · 0采集
-
- 谁知道猪的幸福 2021-05-07
列表字典组合
# coding=utf-8
stus = []
stu1 = {"no":"111","name":"张三","age":23,"nation":"汉","birthday":"1998-01-01","father":{"name":"张建国","company":"中国移动","job":"客户经理"},"mother":{"name":"吴燕玲","company":"师大附中","job":"语文老师"}}
stus.append(stu1)
print(stus)
name = stus[-1]["name"]
print(name)
stu2 = {"no":"112","name":"李四","age":23,"nation":"汉","birthday":"1998-01-01","father":{"name":"李建国","company":"中国联通","job":"客户经理"},"mother":{"name":"张丽丽","company":"人民医院","job":"外科医生"}}
stus.append(stu2)
print(stus)
name = stus[-1]["name"]
print(name)
fatherName = stus[-1]["father"]["name"]
print(fatherName)

- 0赞 · 0采集
-
- 谁知道猪的幸福 2021-05-07
列表字典组合
# coding=utf-8
stus = []
stu1 = {"no":"111","name":"张三","age":23,"nation":"汉","birthday":"1998-01-01","father":{"name":"张建国","company":"中国移动","job":"客户经理"},"mother":{"name":"吴燕玲","company":"师大附中","job":"语文老师"}}
stus.append(stu1)
print(stus)
name = stus[-1]["name"]
print(name)
stu2 = {"no":"112","name":"李四","age":23,"nation":"汉","birthday":"1998-01-01","father":{"name":"李建国","company":"中国联通","job":"客户经理"},"mother":{"name":"张丽丽","company":"人民医院","job":"外科医生"}}
stus.append(stu2)
print(stus)
name = stus[-1]["name"]
print(name)
fatherName = stus[-1]["father"]["name"]
print(fatherName)
- 0赞 · 0采集
-
- 谁知道猪的幸福 2021-05-07
列表字典组合
# coding=utf-8
stus = []
stu1 = {"no":"111","name":"张三","age":23,"nation":"汉","birthday":"1998-01-01","father":{"name":"张建国","company":"中国移动","job":"客户经理"},"mother":{"name":"吴燕玲","company":"师大附中","job":"语文老师"}}
stus.append(stu1)
print(stus)
name = stus[-1]["name"]
print(name)
stu2 = {"no":"112","name":"李四","age":23,"nation":"汉","birthday":"1998-01-01","father":{"name":"李建国","company":"中国联通","job":"客户经理"},"mother":{"name":"张丽丽","company":"人民医院","job":"外科医生"}}
stus.append(stu2)
print(stus)
name = stus[-1]["name"]
print(name)
fatherName = stus[-1]["father"]["name"]
print(fatherName)
- 0赞 · 0采集
-
- 谁知道猪的幸福 2021-05-07
#键值对存储key不能重复,value可以重复
# coding=utf-8
lisa = {"name":"Lisa","age":23}
print(lisa)
print(lisa["age"])
lisa["age"] = 26
lisa["height"] = 166
print(lisa)
lisa.pop("age")
print(lisa)

- 0赞 · 0采集
-
- 谁知道猪的幸福 2021-04-01
左闭右开[0:2]取第一个和第二个
反向索引最后一个下标是-1
# coding=utf-8
books = ["红楼梦","三国演义","水浒传","西游记","聊斋志异"]
print(books[0:4])
print(books[0:-1])

- 0赞 · 0采集
-
- 谁知道猪的幸福 2021-04-01
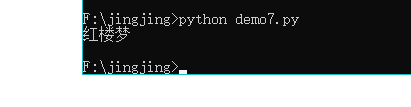
# coding=utf-8
books = ["红楼梦","三国演义","水浒传","西游记","聊斋志异"]
print(books[0])
- 0赞 · 0采集
-
- 谁知道猪的幸福 2021-04-01
int取整
%取余
# coding=utf-8
n=154
a=int(n/100)
b=int(n%100/10)
c=n%10
print(a)
print(b)
print(c)
re=a*a*a+b*b*b+c*c*c
if n==re:
print(n,end="")
print("是水仙花数")
else:
print(n,end="")
print("不是水仙花数")
154除以100取余54,54除以10等于5.4取整为5

- 0赞 · 0采集
-
- 谁知道猪的幸福 2021-04-01
# coding=utf-8
score = 30
if score >=60:
print("考试通过!")
if score >= 90:
print("名列前茅,重点表扬")
else:
print("继续努力,潜力巨大")
else:
print("考试未通过,还需努力")

注意缩进
-
截图0赞 · 0采集
-

- 汪正 2021-03-13
整型(整数)不需要加双引号,加了双引号就是字符串
- 0赞 · 0采集
-
- 汪正 2021-03-13
双引号一定标识字符串
- 0赞 · 0采集
-
- 谁知道猪的幸福 2021-03-11
# coding=utf-8
la = "德语"
if la == "德语" :
print("Ich liebe dich")
elif la == "韩语" :
print("사랑해")
elif la == "英语" :
print("I love you")
else :
print("我爱你")
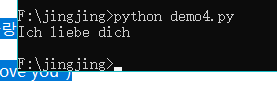
由于是用记事本打开编辑的所以对编码有要求最终保存为utf-8 文件开头对应utf-8 猜测是这个原因,也许我用个正经编辑器就不会这样
- 0赞 · 0采集
-
- 谁知道猪的幸福 2021-03-11
注意 () not and or的优先级
# coding=gbk
r1 = 1 != 1 or 8 < 2 and 6 > 3
print(r1)
r2 = 1 != 1 or not 8 < 1 and 6 > 3
print(r2)
r3 = 1 != 1 or not (8 < 1 and 6 > 3)
print(r3)
x = 700
re = (1000 - x) * 30
print(re)
if(re >= 1 and re <= 10000) :
print("结果落在区间内")
else :
print("结果未落在区间内")

- 0赞 · 0采集
-
- 谁知道猪的幸福 2021-03-11
# coding=gbk
x=1600
re = (1000-x)*30
print(re)
if re >10000 :
print("结果大于10000")
else :
print("结果小于10000")

True False 首字母是大写的
- 0赞 · 0采集
-
- 谁知道猪的幸福 2021-03-11
# coding=gbk
if 8 > 6 :
print("判断条件成立")
else :
print("判断条件不成立")

- 0赞 · 0采集
-
- 谁知道猪的幸福 2021-02-23
yntaxError: Non-ASCII character '\xe5' in file index.py on line 7, but no encoding declared; see http://python.org/dev/p
开头加# -*- coding: UTF-8 -*-
不好使就加#coding=gbk 总有一款适合你

- 0赞 · 0采集



