-

- Keyro 2025-08-25
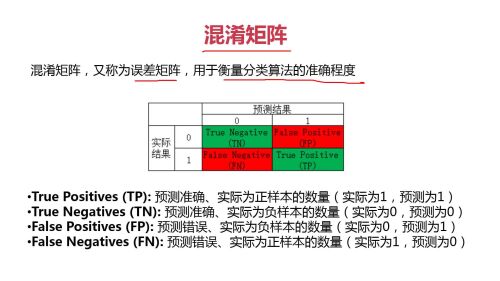
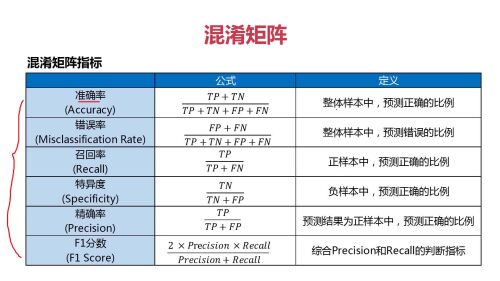
 混淆矩阵
混淆矩阵- 0赞 · 0采集
-
- Keyro 2025-08-25
 使用准确率进行模型评估的局限性
使用准确率进行模型评估的局限性- 0赞 · 0采集
-
- Keyro 2025-08-25
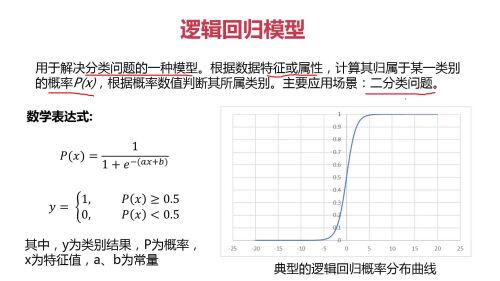 逻辑回归模型
逻辑回归模型- 0赞 · 0采集
-
- Keyro 2025-08-25
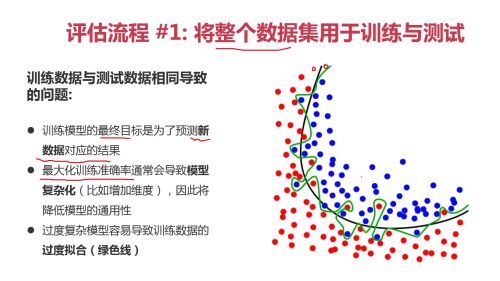
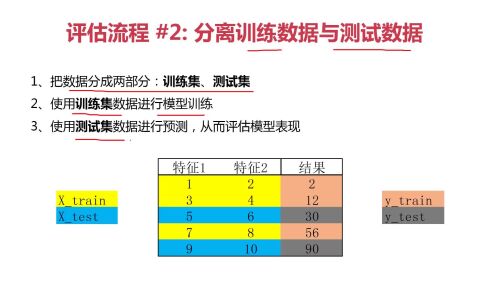
 模型训练与测试
模型训练与测试- 0赞 · 0采集
-
- Keyro 2025-08-25
 模型评估流程
模型评估流程- 0赞 · 0采集
-
- Keyro 2025-08-25
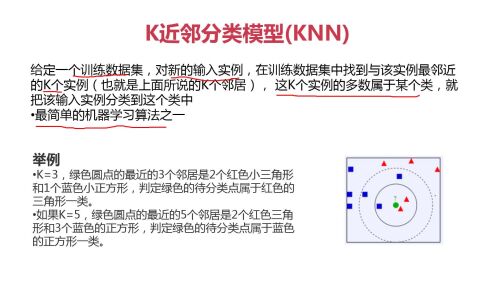
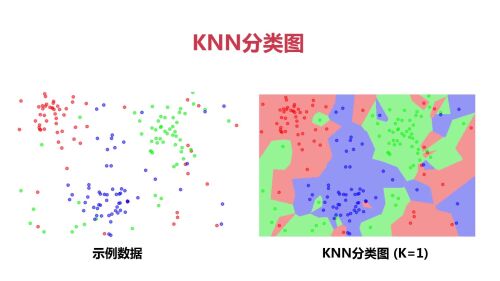 KNN近邻分类模型
KNN近邻分类模型- 0赞 · 0采集
-
- Keyro 2025-08-25
 常用分类算法
常用分类算法- 0赞 · 0采集
-

- 慕工程7062656 2025-02-17
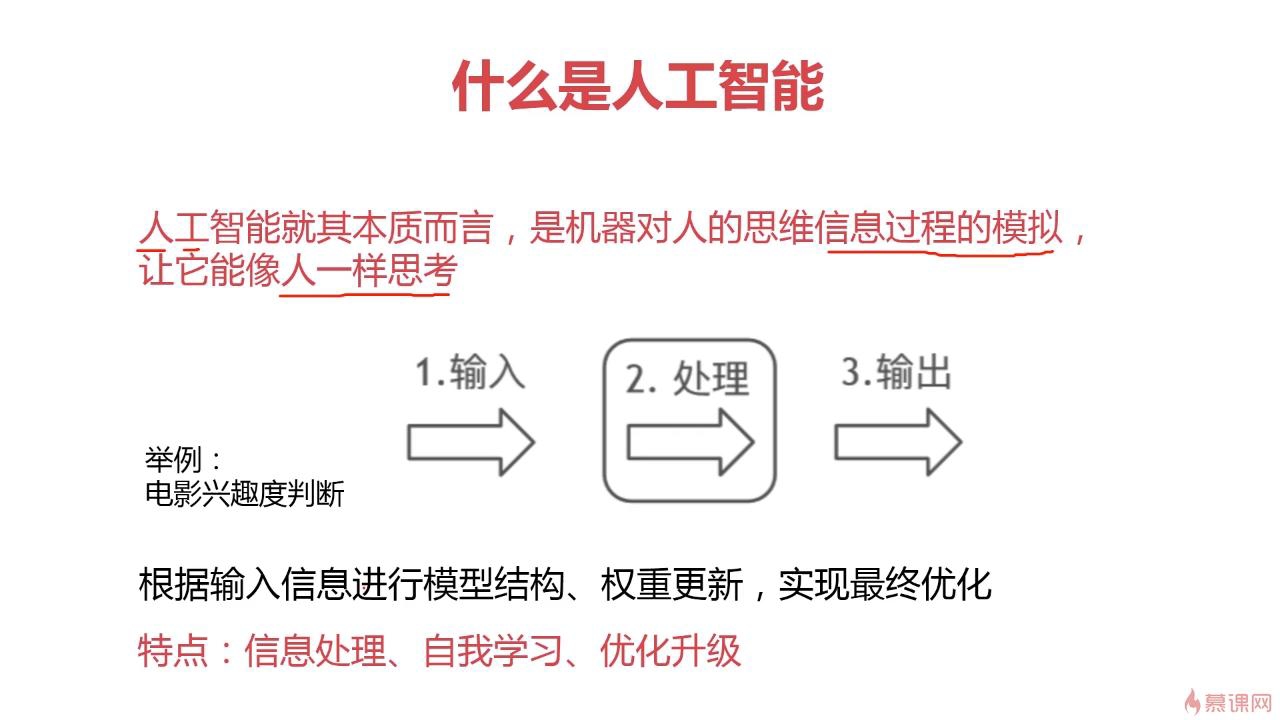
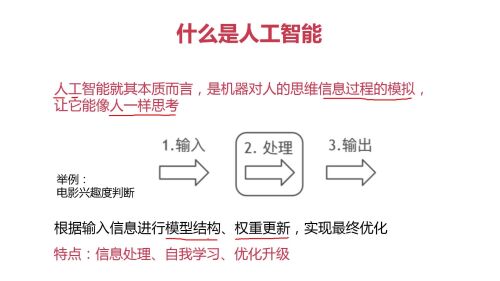
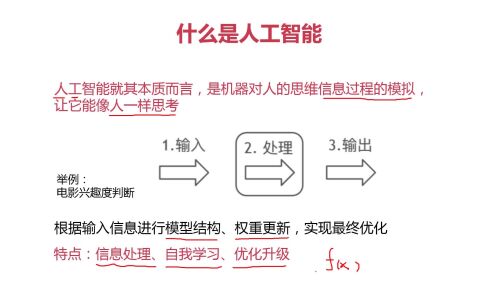
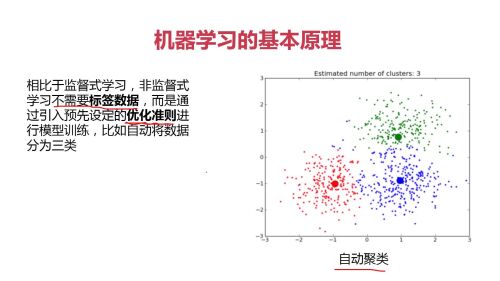
人工智能的本质,就是机器人像人一样思考问题
- 0赞 · 0采集
-

- Seachal 2024-11-17
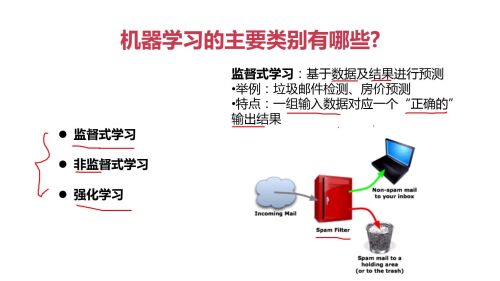
人工智能核心方法:机器学习、深度学习
机器学习是一种实现人工智能的方法,
深度学习是一种实现机器学习的技术。
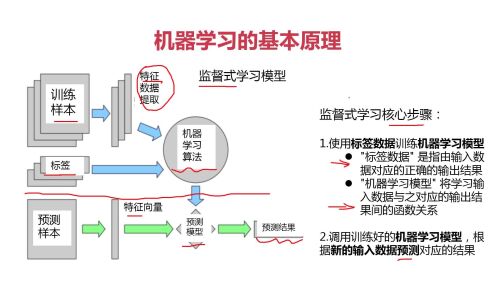
机器学习:使用算法来解析数据、从中学习,然后对真实世界中的事件做出决策和预测。
深度学习:模仿人类神经网络、建立模型。
深度机器学习:
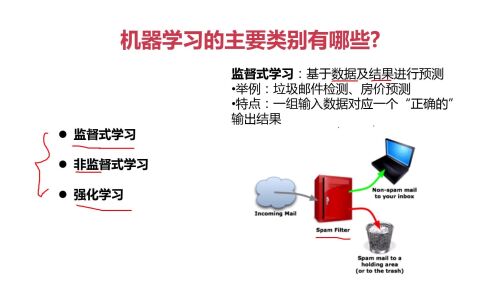
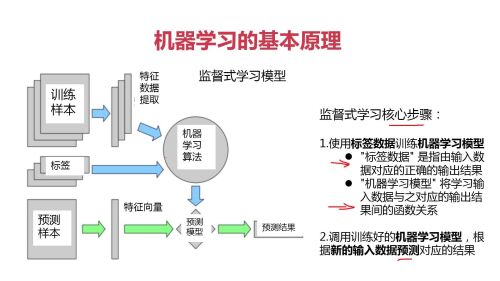
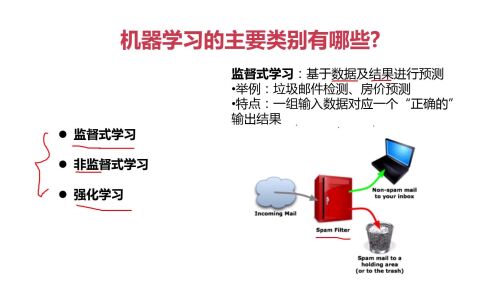
监督式学习:基于数据及结果进行预测;
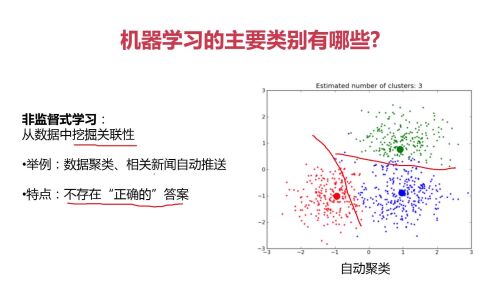
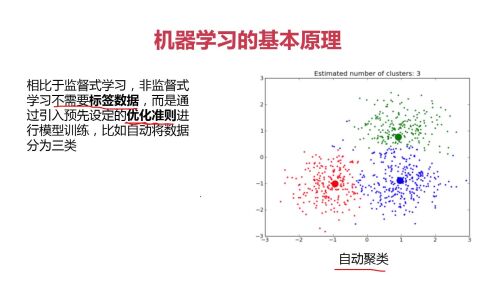
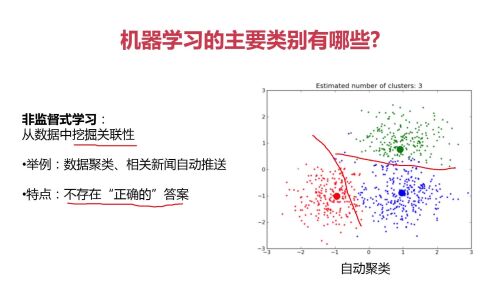
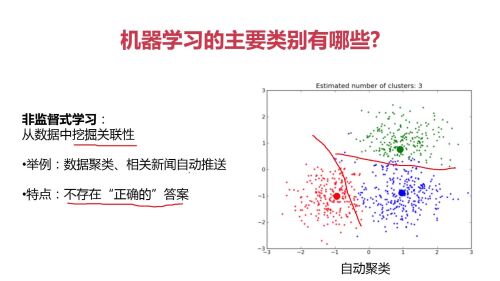
非监督式学习:从数据中挖掘关联性; (不存在正确答案)
强化学习:


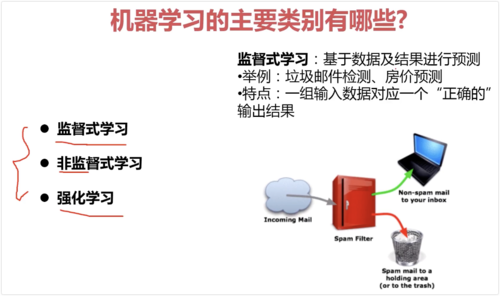
- 0赞 · 0采集
-

- 扶云归 2024-09-10
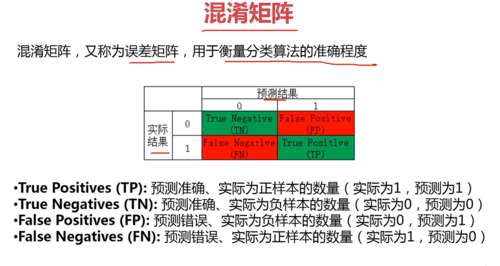
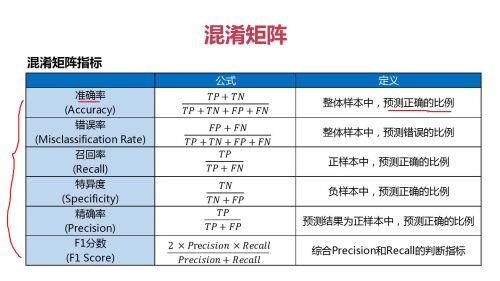

1
- 0赞 · 0采集
-

- 慕标6411234 2024-06-26
1-1 课程介绍


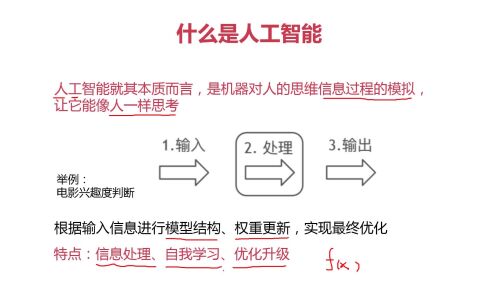

- 0赞 · 0采集
-
- 慕标6411234 2024-06-26

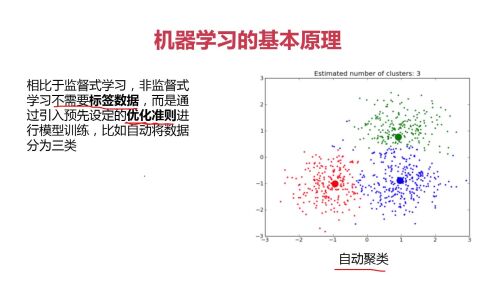
1-2
- 0赞 · 0采集
-
- 慕标6411234 2024-06-26
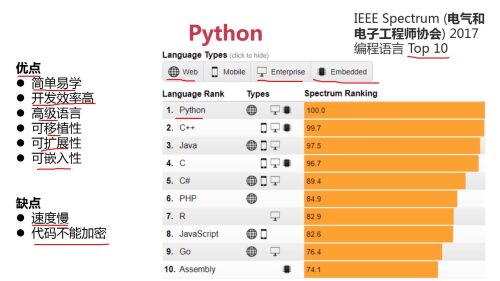 可移植性:多平台开发一次; 可嵌入性:例如C++中直接调用Python写好功能模块
可移植性:多平台开发一次; 可嵌入性:例如C++中直接调用Python写好功能模块 官网:
官网:
- 0赞 · 0采集
-

- 酒饱饱 2024-04-18
了解
- 0赞 · 0采集
-

- weixin_慕侠6048814 2023-12-20
 .笔记.
.笔记.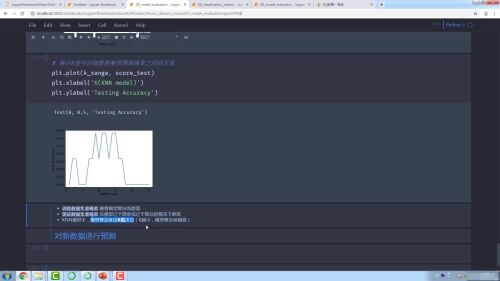
- 0赞 · 0采集
-
- weixin_慕侠6048814 2023-12-19
笔记.

- 0赞 · 0采集
-
- weixin_慕侠6048814 2023-12-19
记

- 0赞 · 0采集
-
- weixin_慕侠6048814 2023-12-19
笔记

- 0赞 · 0采集
-
- weixin_慕侠6048814 2023-12-19
笔记

- 0赞 · 0采集
-

- 慕斯卡6411321 2023-11-26

实战
- 0赞 · 0采集
-
- 慕斯卡6411321 2023-11-26

核心算法
- 0赞 · 0采集
-
- 慕斯卡6411321 2023-11-26
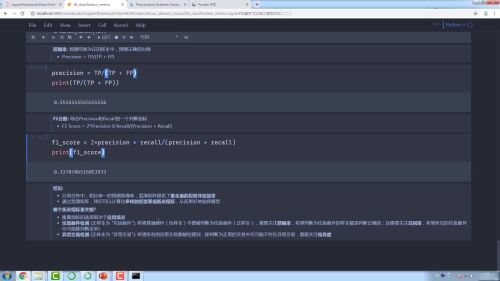
结论部分记在这里
- 0赞 · 0采集
-
- 慕斯卡6411321 2023-11-26

混淆矩阵指标的特点和选择指标的介绍
- 0赞 · 0采集
-
- 慕斯卡6411321 2023-11-26
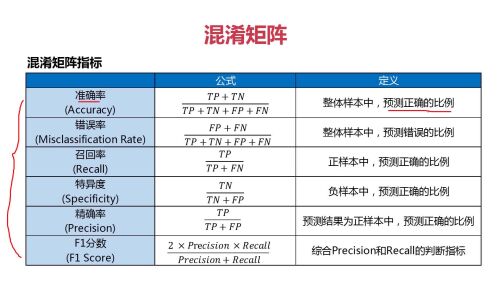
混淆矩阵的主要指标
- 0赞 · 0采集
-
- 慕斯卡6411321 2023-11-26
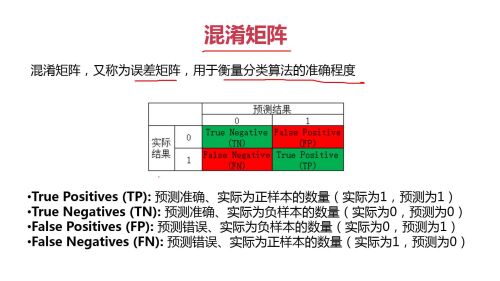
介绍了混淆矩阵的作用
- 0赞 · 0采集
-
- 慕斯卡6411321 2023-11-26
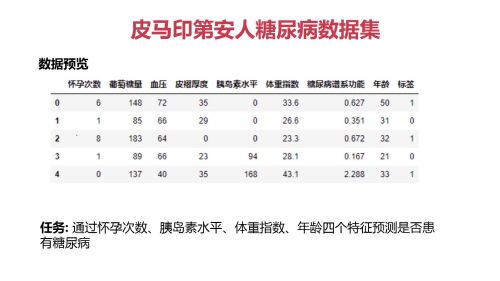
介绍任务
- 0赞 · 0采集
-
- 慕斯卡6411321 2023-11-26

数据集大致介绍
- 0赞 · 0采集
-
- 慕斯卡6411321 2023-11-26
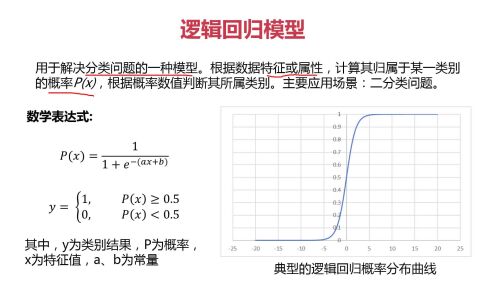
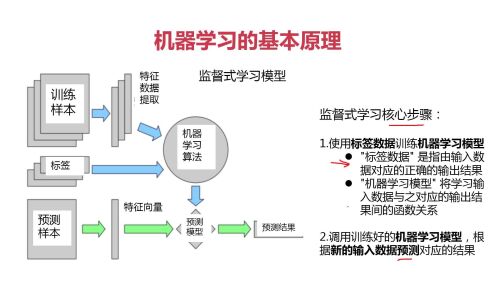
这是回归模型的数学表达式及模型展示
- 0赞 · 0采集
-

- 慕先生5153271 2023-11-11
- iris数据集,机器学习
- 0赞 · 0采集
-

- 慕少7339756 2023-08-01

分类的两个模型:
K近邻:找input数据(图片绿色的点)最邻近的N个数据,都是哪类的 (图片上,附件3个两个红,一个蓝)。找到 点最多的那个类(蓝,有两个点),就把input点(绿色),归为该类(蓝色)。
逻辑回归分类:(通常用于2分类)通过模型,得到input点 属于某类的概率,小于0.5认为上A类,大于0.5认为上B类。
- 0赞 · 0采集





 官网:
官网:




数据加载中...