-

- 慕圣7776394 2023-02-07
高可用 分布式 水平拓展不需要关心
- 0赞 · 0采集
-

- 慕无忌2366688 2022-05-02
ES 集群就是一个或者多个拥有相同的Cluster.namespace 节点所组成的。
共同承担着数据以及负载的压力。
当有节点加入集群或者从集群当中移除
整个集群将会平均分布所有的数据。
例如下图
新加node3

信的node刚进来,集群之前选举出来的主节点就会感知到,并且做后续的一系列的管理和负载编排工作。
主节点负责集群范围内的所有变更,比如增加索引,删除索引,或者增加删除索引等等。
用户可以将请求发送到集群的任意节点,每一个节点都知道任意文档存储的位置,并且能够将我们的请求直接转发到我们所需文档的具体节点,最后将结果展示给客户端。
ES对于集群内部管理是透明的。
- 0赞 · 1采集
-

- 慕无忌9467384 2022-03-12

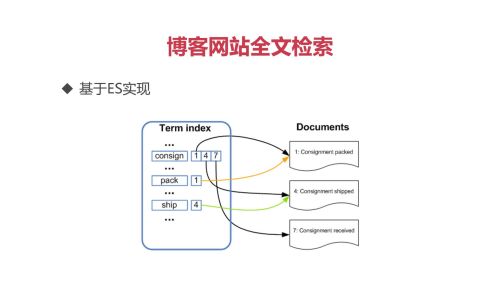
倒排索引
- 0赞 · 0采集
-

- 慕宸 2021-11-02
基于ES实现大数据量搜索

1、新增/删除节点时,主节点都会平均分配所有数据
2、客户端可以将请求发送到任意节点。
- 0赞 · 0采集
-

- 艾衡 2021-08-20
倒排索引
把用户一长串的词进行拆分
形成独立的最小词源
通过算法整合出来
更好的分布式和水平扩展的能力
任何节点都可以成为主节点
用户可以将请求发送到集群的任一个节点
- 0赞 · 0采集
-
- 艾衡 2021-08-20
倒排索引
把用户一长串的词进行拆分
形成独立的最小词源
通过算法整合出来
更好的分布式和水平扩展的能力
任何节点都可以成为主节点
用户可以将请求发送到集群的任一个节点
- 0赞 · 0采集
-

- mracale 2020-05-09
倒排索引规则
-
截图0赞 · 0采集
-

- 小木思琼 2020-04-08
ES在存入数据的时候,就会对数据进行分词,对查询搜索效率提升
- 0赞 · 0采集
-

- 追风之神 2020-04-02
ES搜索的原理:倒排索引
-
截图0赞 · 0采集
-

- 慕姐50055 2020-01-03
倒排索引工作原理
1.存入数据时使用分词器拆分数据
2.不同的词源指向不同的Documents(等同于MySQL中的Row)
3.ES会维护最小词源到DocumentID的映射(一个词源可以对应多个)
4.检索关键词时,ES会拆分最小词源,由于数据会存在不同的Document,根据不同的词源,可以共同定位到包含所有关键词的Document,根据权重,返回(例如:查询ABC,根据A可知存有A数据的ID有1.5.7,B数据的ID有2.5.8,D数据的ID有5.9.8,可知同时包含ABC的ID为5)
- 2赞 · 3采集
-

- 慕九州9097652 2019-12-29
就没大哥写笔记的吗,这讲的很好啊,就是没听懂
- 0赞 · 0采集









