-

- zrey 2022-04-01
DataFrame Spark平台的分布式弹性数据集
DataFrame以 RDD为基础的分布式数据集, 是Row对象的集合
DataSet是 DataFrame的一个特例, 强类型数据集

DF 对 RDD的优势:
DF提供数据的结构信息
DF定制化内存管理, 数据存放于JVM堆外内存
DF先转换为逻辑计划在执行,对任何语言执行效率一样
DF提供更丰富API
DataSet 对比DataFrame优点:
具备DF优点
Api面向对象
#创建DataFrame方法: 读文件或者 RDD转换为DF sparkSession.read.json() sparkSession.read.csv() #RDD转化为DF #通过自定义的case class object MyProject{ case class Person(name:String, age:Int) #两个列name和age def main(args: Array[String]): Unit={ val sparkSession = SparkSession .builder() .master(master="local") #本地运行 .getOrCreate() val sparkContext = sparkSession.sparkContext val rdd = sparkContext.textFile("") val rowRDD = rdd.map(_.split(" ")) #每一行空格切割 .map(x =>Person(x(0),x(1).toInt)) #rdd和caseClass关联 #执行toDF()方法将RDD转换为DF import sparkSession.implicits._ val df = rowRDD.toDF() df.show() sparkSession.stop() } } #通过自定义schema #val rdd后开始 val schemaField = "name, age" val schemaString = schemaField.split(",") val schema = StructType( List( StructField(schemaString(0).StringType, nullable=true), StructField(schemaString(1).IntegerType, nullable=true) ) ) #生成Row类型参数RDD val rowRDD = rdd.map(_.split(" ")) .map(x =>Row(x(0),x(1).toInt)) val df = sparkSession.createDataFrame(rowRDD,schema) #转换成df#DataFrame转换为RDD val rdd = df.rdd #创建Dataset: #df转化为dataset import sparkSession.implicits_ val ds = df.as[Person] #因为Row对象是Person对象 #rdd转换为dataset import sparkSession.implicits_ val ds = sparkSession.createDataset(rdd) ##RDD和datatset toDS() rdd->Dataset rdd() Dataset->rdd ##Dataset和DataFrame toDF() Dataset->DataFrame as[ElementTyle] Dataframe->dataset
- 0赞 · 0采集
-
- zrey 2022-04-01
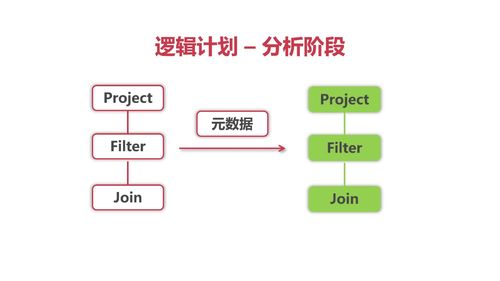
Spark SQL 逻辑计划- 物理计划 -优化





- 0赞 · 0采集
-
- zrey 2022-04-01
Spark SQL 分布式SQL引擎
底层依赖RDD, 处理结构化数据的一个模块
入口:SparkSession (2.0之后)
//Scala 不需要hive则不需要hivesupport val spark = SparkSession.builder().enableHiveSupport().getOrCreate
Spark SQL和hive区别:
Hive基于Mapreduce框架实现SQL操作
Spark SQL拥有Catalyst优化器, 支持不同数据源
Spark SQL没有自己的存储, Hive集成HDFS
SparkSQL没有自己的元数据管理,要依赖Hive

Spark SQL 访问 Hive 仓库:
1. SPARK_HOME/conf 下添加 hive-site.xml
2. 启动 thriftserver服务 : SPARK_HOME/sbin/start-thriftserver.sh
- 0赞 · 0采集
-

- 慕粉1318052700 2020-03-08
- 事实表,类似于全量表,维度表类似于增量表
-
截图0赞 · 0采集
-

- qq_慕移动5288259 2019-12-25
66666666666666
- 0赞 · 0采集
-

- 慕粉7532284 2019-11-26
- spark sql区别与hive 1. spark sql在内存中运算 2. spark sql 依赖catalst进行sql解析 3. spark sql访问hive数据方式:spark sql—》thriftServer解析器—》metadata—》hive元数据
-
截图1赞 · 2采集
-

- 慕莱坞8135860 2019-10-30
- 记笔记
-
截图0赞 · 0采集
-

- weixin_慕容4284592 2019-10-24
sparksql和hive对比
sparksql有catalyst优化器
sparksql 如何访问hive:hive-site.xml放到SPARK_HOME/conf
然后/$SPARK_HOME/sbin/start-thriftserver.sh
- 0赞 · 4采集
-

- 精慕门8449894 2019-09-04
- 很好
- 0赞 · 0采集







数据加载中...