-

- dravenxiaokai 2026-03-13
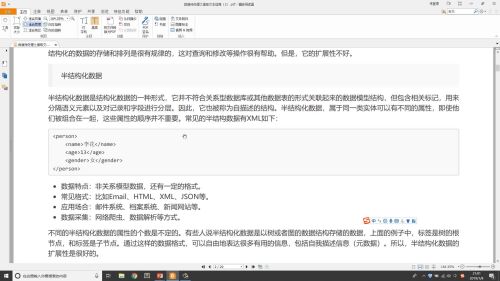
结构化的数据的存储和排列是很有规律的,这对查询和修改等操作很有帮助。但是,它的扩展性不好。
半结构化数据是结构化数据的一种形式
- 0赞 · 0采集
-

- 单挑谁怕谁 2025-12-21
需补充扩展知识

- 0赞 · 0采集
-

- 超人归来2020 2025-08-28
如果需要处理 PDF,更推荐使用纯 Python 库(跨平台、无需依赖外部软件):
PyPDF2/PyPDF4:合并、拆分、提取文本、添加水印等基础操作。
pdfplumber:更精准的文本提取(支持复杂排版)。
PyMuPDF(fitz):高效的文本提取、页面操作、转换格式等。
reportlab:生成 PDF 文档(从空白页创建内容)。
综上,win32com 可以间接操控 PDF 软件,但并非处理 PDF 的最优选择,纯 Python 库通常更轻便、高效。
编辑分享
给PDF添加水印的具体操作步骤
如何将PDF转换为Word格式?
怎样使用win32com提取PDF中的图片?
- 0赞 · 0采集
-

- 慕慕6459754 2025-02-18

基础层 采集层 数据处理层 应用层
基础层:基础信息采集;采集层:数据结构搭建,数据模型搭建;处理层:数据清洗,标准化数据格式;应用层:数据分析结论输出,深度挖掘;
- 0赞 · 0采集
-
- 慕慕6459754 2025-02-18
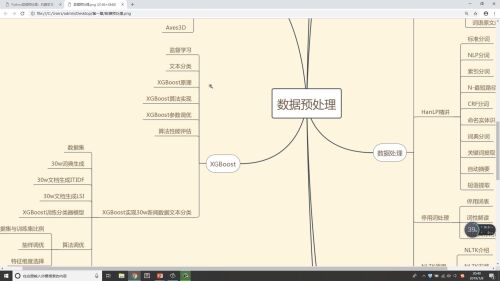
数据预处理:
数据集成
数据清洗
数据处理
数据变换
数据归纳
可视化技术
XGBoost--实现30W数据文本分析
- 0赞 · 0采集
-

- 为何永远放不开 2024-06-24

文件操作方法
- 0赞 · 0采集
-
- 为何永远放不开 2024-06-24
网络爬虫,有时间学习下- 0赞 · 0采集
-

- 遇见未来的你 2024-02-06

课程思维导图
- 0赞 · 0采集
-
- 遇见未来的你 2024-02-06

开发环境说明
- 0赞 · 0采集
-
- 遇见未来的你 2024-02-06
30万条数据分析
训练分类器
算法调优
- 0赞 · 0采集
-
- 遇见未来的你 2024-02-06


数据预处理流程
数据清理
数据集成
数据变换
数据归约
- 0赞 · 0采集
-
- 遇见未来的你 2024-02-06

数据处理往往比算法模型和调参带来的效果更好
文本信息处理,稍作改动也支持图片和语音
- 0赞 · 0采集
-
- 遇见未来的你 2024-02-06


什么是数据预处理
- 0赞 · 0采集
-

- 扶云归 2023-09-02
遍历读取文件
算法思路:
·遍历文件的类TraversalFun:TraversalDir、AllFiles
·遍历目录文件TRaversalDir:AllFiles(self.rootDir)
·递归遍历文件AllFiles(self,rootDir)
·判断是否为文件isfile:打印出文件名
·判断是否是目录isdir:递归遍历
- 0赞 · 0采集
-
- 扶云归 2023-09-02
算法思路:
·定义文件路径和转存路径:split
·修改新的文件名:TranType(filename,typename)、fnmatch
·设置完整的保存路径:join
·启动应用程序格式转换:Dispatch
·保存文本:SaveAs
- 0赞 · 0采集
-
- 扶云归 2023-09-02
PDF转TXT的算法实现
算法思路:
·定义文件路径和转存路径:split
·修改新的文件名:fnmatch
·设置完整的保存路径:join
·启动应用程序格式转换:Dispatch
·保存文本:SaveAs
- 0赞 · 0采集
-
- 扶云归 2023-09-02
Word转TXT算法实现
算法思路:
·定义文件路径和转存路径:split
·修改新的文件名:fnmatch
·设置完整的保存路径:join
·启动应用程序格式转换:Dispatch
·保存文本:SavaAs
- 0赞 · 0采集
-
- 扶云归 2023-09-02
结构化数据:
结构化数据是指可以使用关系型数据库表示和存储,表现为二维形式的数据。一般特点是:数据以行为单位,一行数据表示一个实体的信息,每一行数据的属性是相同的。
·数据特点:关系模型数据,关系数据库表示
·常见格式:比如MySQL、Oracle、SQL Server等
·应用场合:数据库、系统网站、数据备份、ERP等
·数据采集:DB导出、SQL等方式
·优缺点:结构化的数据的存储和排列是很有规律的,这对修改和查询等操作很有帮助。但是,它的扩展性不好。
半结构化数据:
半结构化数据是结构化数据的一种形式,它并不符合关系型数据库或其他数据表的形式关联起来的数据模型结构,但包含相关标记,用来分隔语义元素以及对记录和字段进行分层。因此,它也被称为自描述的结构。半结构化数据,属于同一类实体可以有不同的属性,即使他们被组合在一起,这些属性的顺序并不重要。
·数据特点:非关系模型数据,还有一定的格式
·常见格式:比如Email、HTML、XML、JSON等
·应用场合:邮件系统、档案系统、新闻网站等
·数据的采集:网络爬虫、数据解析等方式
·优点:不同的半结构化数据的属性的个数是不定的。有些人说半结构化数据是以树或者图的数据结构存储的数据,标签是树的根节点,和标签是子节点。通过这样的数据格式,可以自由地表达很多有用的信息,包括自我描述信息(元数据)。所以,半结构化数据的扩展性是很好的。
非结构化数据:
就是没有固定结构的数据。各种文档、图片、视频/音频等都属于非结构化数据。对于这类数据,我们一般直接整体进行存储,而且一般存储为二进制的数据格式。
·数据特点:没有固定格式的数据
·常见格式:Word、PDF、PPT、图片、音视频等
·应用场合:图片识别、人脸识别、医疗影像、文本分析等
·数据采集:网络爬虫、数据存档等方式
- 0赞 · 0采集
-
- 扶云归 2023-09-02
数据清理:通过填写缺失的值、光滑噪声数据、识别或删除离群点并解决不一致性来清理数据。目标:格式标准化,异常数据清理,错误纠正,重复数据的清除。
数据集成:将数据由多个数据源合并成一个一致的数据存储,如数据仓库。
数据变换:通过平滑聚集,数据概化,规范化等方式将数据转换成适用于的形式。如把数据压缩到0.0-1.0数值区间。
数据归约:往往数据量非常大,得到数据集的归约表示,它小得多,但仍接近保持原数据的完整性,结果与归约前结果相同或几乎相同。
- 0赞 · 0采集
-
- 扶云归 2023-09-02
数据预处理简而言之就是将原始数据装进一个预处理的黑匣子之后,产生出高质量数据用来适应相关技术或者算法模型。
·将原始数据的数据直接进行分类模型训练,分类器准确率和召回率都比较低。因此我们原始数据存在很多干扰项,比如的,是等这些所谓停用词特征对分类起的作用不大,很难达到工程应用。
·我们将原始数据放进预处理黑匣子后,会自动过滤掉干扰数据,并且还会按照约定的方法体现每个词特征的重要性,然后将词特征压缩变换在数值型矩阵中,再通过分类器就会取得不错的效果,可以进行工程应用。
预处理前:不完整、偏态、噪声、特征比重、特征维度、缺失值、错误值等问题。
- 0赞 · 0采集
-

- 参牟 2022-12-21

文件抽取资料
- 0赞 · 0采集
-
- 参牟 2022-12-17

word 转换tet思路
- 0赞 · 0采集
-
- 参牟 2022-12-17
三类数据类型:结构化数据,半结构化数据,非结构化数据

- 0赞 · 0采集
-

- 异凉聪 2022-03-21
#coding=utf-8 import os,fnmatch from win32com import client as wc from win32com.client import Dispatch def Word2Txt(filepath,savePath=''): dirs,filename = os.path.split(filePath) new_name="" if fnmatch.fanmatch(filename,'*.doc'): new_name = filename[:-4]+'.txt' elif fnmatch.fnmatch(filename,'*.docx'): new_name = filename[:-5]+'.txt' else: print("格式不正确") return if savePath == '': savePath = dirs else: savePath = savePath word2txtPath = os.path.join(savePath,new_name) print('-->',word2txtPath) wordapp = wc.Dispatch('word.Application') mytxt = wordapp.Documents.Open(filePath) if __name__=='__main__': filePath = os.path.abspath(r'../../*.doc') word2Txt(filePath)- 0赞 · 0采集
-

- Zhyan 2021-10-18
 总结
总结- 0赞 · 0采集
-

- akabla 2021-03-25
1.数据集成
-
截图0赞 · 0采集
-
- akabla 2021-03-25
1.why
-
截图0赞 · 0采集
-
- akabla 2021-03-25
特征预处理
不完整、偏态、噪声、特征比重、特征纬度、缺失值、错误值等问题;
存在完整、正态、干净、特征和事、特征纬度合理、无缺失值
-
截图0赞 · 0采集
-
- akabla 2021-03-25
1.特征预处理
- 0赞 · 0采集
-
- akabla 2021-03-25
数据预处理
谓词、停用词
特征压缩变换
- 0赞 · 0采集










 总结
总结