-

- 慕瓜9453711 2021-09-20
Matplotlib

- 0赞 · 0采集
-

- weixin_慕后端8345327 2020-12-09
MVC全名是Model View Controller,是模型(model)-视图(view)-控制器(controller)的缩写,一种软件设计典范,用一种业务逻辑、数据、界面显示分离的方法组织代码,将业务逻辑聚集到一个部件里面,在改进和个性化定制界面及用户交互的同时,不需要重新编写业务逻辑。MVC被独特的发展起来用于映射传统的输入、处理和输出功能在一个逻辑的图形化用户界面的结构中。
简单的说, MVC 是一种软件开发的方法,它把代码的定义和数据访问的方法(模型)与请求逻辑 (控制器)还有用户接口(视图)分开来。 这种设计模式关键的优势在于各种组件都是 松散结合 的。这样,每个由 Django驱动 的Web应用都有着明确的目的,并且可独立更改而不影响到其它的部分。 比如,开发者 更改一个应用程序中的 URL 而不用影响到这个程序底层的实现。 设计师可以改变 HTML 页面 的样式而不用接触 Python 代码。 数据库管理员可以重新命名数据表并且只需更改一个地方,无需从一大堆文件中进行查找和替换
简单的说, MVC 是一种软件开发的方法,它把代码的定义和数据访问的方法(模型)与请求逻辑 (控制器)还有用户接口(视图)分开来。 这种设计模式关键的优势在于各种组件都是 松散结合 的。这样,每个由 Django驱动 的Web应用都有着明确的目的,并且可独立更改而不影响到其它的部分。 比如,开发者 更改一个应用程序中的 URL 而不用影响到这个程序底层的实现。 设计师可以改变 HTML 页面 的样式而不用接触 Python 代码。 数据库管理员可以重新命名数据表并且只需更改一个地方,无需从一大堆文件中进行查找和替换
- 0赞 · 0采集
-

- Geekxiong 2020-09-22
sigmoid函数
-
截图0赞 · 0采集
-

- weixin_慕标9554468 2020-05-19
交叉检验,在数据量较少的时候防止过拟合出现的方法。
将训练集划分为n部分,取其中一个为验证集,n-1个为测试集。循环n次。保证所有的部分都充当了一次验证集。将最后分数取平均值
- 0赞 · 0采集
-
- weixin_慕标9554468 2020-05-19
换了优化器:SGD 变成了RMSprop
优化器的含义?
- 0赞 · 1采集
-
- weixin_慕标9554468 2020-05-19
线性与非线性之间多了一个激活函数
不同的激活函数效果不同
relu的结果比较“生硬”
tanh的结果绘制的曲线能够更好的贴合
softmax: 在多分类中常用的激活函数,是基于逻辑回归的。
Softplus:softplus(x)=log(1+e^x),近似生物神经激活函数,最近出现的。
Relu:近似生物神经激活函数,最近出现的。
tanh:双曲正切激活函数,也是很常用的。
sigmoid:S型曲线激活函数,最常用的。
hard_sigmoid:基于S型激活函数。
linear:线性激活函数,最简单的。
- 0赞 · 0采集
-

- 前端侠 2020-03-08
神经网络的进化
-
截图0赞 · 0采集
-
- 前端侠 2020-03-08
线性神经网络与激活函数
激活函数作用是优化
-
截图0赞 · 0采集
-
- 前端侠 2020-03-08
感知器数学模型
-
截图0赞 · 0采集
-
- 前端侠 2020-03-08
感知器-最小神经元
-
截图0赞 · 0采集
-

- 姚骥同学 2020-03-07
import matplotlib.pyplot as plt
index=27
plt.imshow(x_train[index])
- 0赞 · 0采集
-

- MariaBrown 2019-08-28
1.# 交叉检验
k = 4
num_val_samples = len(train_data) // k # //得到的是一个整数
num_epochs = 100
all_scores = [] # 得分
# 进行循环的交叉检验
for i in range(k):
# 首先把验证集取出来,要取出验证集,需要得到验证集两个边界的大小
val_data = train_data[i * num_val_samples: (i + 1) * num_val_samples]
val_targets = train_target[i * num_val_samples: (i + 1) * num_val_samples]
# 构造训练集,因为我们的训练集本身是不连续的,所以需要用个函数连起来
partial_train_data = np.concatenate(
[train_data[: i * num_val_samples],
train_data[(i + 1) * num_val_samples:]],
axis=0)
partial_train_targets = np.concatenate(
[train_target[: i * num_val_samples],
train_target[(i + 1) * num_val_samples:]],
axis=0)
# 使用模型,每进行一折,都要重新构造一个模型出来
model = build_model()
model.fit(partial_train_data, partial_train_targets, epochs=num_epochs, batch_size=1, verbose=0) # 如果输出的话行数有101*100*4,输出太多,所以暂时不输出
val_mse, val_mae = model.evaluate(val_data, val_targets, verbose=0)
all_scores.append(val_mae)
print('第', i + 1, '折,MSE:', val_mse, 'MAE:',val_mae)
- 0赞 · 0采集
-
- MariaBrown 2019-08-28
1.现实生活中的回归问题比较复杂。
2.kaggle社区是一个数据科学的社区,它里面会有很多数据科学家或爱好者在上面可以讨论问题,并且kaggle上会公开一些数据以及举办一些比赛,有的时候一些大公司也会把自己的数据集放出来并且给出奖金让大家做他的题目为他的题目给出一定的方式,然后对比赛比较好的前几名他海会给一定的奖金。
3.波斯顿房价预测是kaggle的一次比赛。
4.交叉检验:k值通常为5或者10.这种方法通常是比赛的打法。

- 0赞 · 0采集
-
- MariaBrown 2019-08-28
1.非线性指的就是不是一条直线,可能是一条曲线,比如说二次、三次、对数等等。
2.本身神经网络是不包含非线性的,可以通过添加层数和激活函数来非线性化。
3.y_data = np.square(x_data) + noise # 这个和线性回归不一样
model = Sequential()
model.add(Dense(5, input_shape=(1,), activation='tanh'))
model.add(Dense(1))
model.compile(optimizer=SGD(), loss='MSE')
- 0赞 · 0采集
-
- MariaBrown 2019-08-28
1.回归:回归分析是统计学上常见的学习方法。通俗来讲,就是现在有几个变量,这些变量之间有一定的相关性,然后我们希望通过几个变量的值去预测其中另外一个变量的变化关系。比如说用时间、城市、房屋大小等等房屋信息来预测房价,股票信息如前几天股价、股票行业等等去预测未来几天的股价的走势,或是未来几天的温度变化。
2.神经网络就是这么强大,使用感知机以及多层感知机就能完成回归以及分类的几个问题。
3.传统的回归模型:传统的线性回归通常采用的是最小二乘法,就是说这些点要拟合出一条直线,这条直线有一定的约束条件,希望图上所有的点到这条直线的距离之和取到最小。
在神经网络中,条件不太一样。采用迭代方式得出这条直线。
2. 损失函数MSE:均方误差,一般用于回归问题。它指的是真实值与预测值的差的平方和再除以点的个数。区别于传统二乘法的线性回归的点到直线。我们希望找到感知机能够使真实值点与预测点距离之和最小。
5.# 采用感知机
model = Sequential()
model.add(Dense(1, input_shape=(1,)))
model.compile(optimizer=SGD(), loss='MSE')
# 因为模型比较简单,不需要迭代太多次
for step in range(5001):
cost = model.train_on_batch(x_data, y_data) # 输出代价函数,也就是损失函数
# 希望能在训练过程中,看到值的变化情况
if step % 500 == 0:
print('step', step, ' cost:', cost)
# cost值越来越小,说明在收敛,也就是达到了代价函数的全局最小值
- 0赞 · 0采集
-
- MariaBrown 2019-08-28
1.如何使用这个模型?我们用模型来对自己的图片分类。
# 图像处理
from skimage.transform import resize
my_image = 'img_test/8.jpg' # 自己图片的路径,可以是相对路径,也可是绝对路径
my_label_y = [1] # 标记一下是否是猫
my_image = np.array(plt.imread(my_image))
plt.imshow(my_image) # 展示图片
num_px = 64
my_image = resize(my_image, (num_px, num_px)) # 重新调整图片大小
my_image = my_image.reshape(1,-1) # 向量,这里已经对里面的值做了归一化,因为上面的resize有一个参数默认可以做归一化
result = cat_model.predict(my_image) # 调用模型
if result > 0.5: # 如果模型预测值大于0.5,我们就认为是猫
print('猫')
else:
print('非猫')
- 0赞 · 0采集
-
- MariaBrown 2019-08-27
1.使用自己的数据集做一个猫咪识别器,流程:

- 0赞 · 3采集
-
- MariaBrown 2019-08-27
1.构建的神经网络:

2.隐藏层一般人脑是理解不了的。
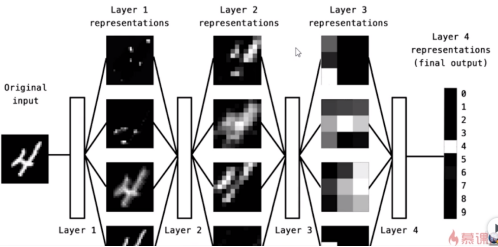
- 1赞 · 1采集
-
- MariaBrown 2019-08-26
1.Keras基础模块:

2.SGD:

- 0赞 · 0采集
-
- MariaBrown 2019-08-26
1.使用命令行启动jupyter:
在指定位置启动:jupyter notebook 路径2.jupyter notebook的前身叫IPython Notebook,后来升级到4.0,将名字改成了jupyter。至于为什么改名,因为它现在不仅可以支持Python,还可以支持其他语言,R、Julia、JS、Scala、Go。
它的名字是由:Julia、Python、R组合而成。
3. 为什么要使用Jupyter呢?
是因为jupyter在编辑过程中,每编辑一段代码就可以运行一段代码,运行的结果也将直接显示在代码下方,方便查看。尤其是在数据科学领域,需要频繁地进行数据清洗,查看,计算,以及画图,所以非常需要这种可交互式的编程环境。并且它的运行以及编辑结果将全部保存在这个文件中。也就是说,当你运行完所有的程序以及代码,你的所有执行过程、结果以及结论都会保存在这个文件当中。后续你只要把这个文件分享给别人,别人就能看到你做的一系列操作。
4. 在command模式下,连续按两次d就可以删除这个段落。
5. 按下这个按钮便可查看所有的指令,并且能够看到在哪个模式下能够执行的指令。

- 0赞 · 0采集
-
- MariaBrown 2019-08-26
1.Tensorflow安装:
CPU版本:conda install tensorflow
GPU版本:conda install tensorflow-gpu
2.Keras安装:conda install keras
- 0赞 · 0采集
-
- MariaBrown 2019-08-26
1.Tensorflow是目前最热门的深度学习框架,且官方支持Keras。
2.Anaconda安装:
1)windows、Mac OS、Linux都已支持Tensorflow
2)Windows用户只能使用Python3.5+(64bit)
3)有GPU可以安装带GPU版本的,没有GPU就安装CPU版本的
4)安装Anaconda,pip版本大于8.1
- 0赞 · 0采集
-
- MariaBrown 2019-08-26
1.总的来说,Keras是目前排名最高的、非框架的深度学习库。Keras是基于其他其他深度学习库之上的开发的一套高层的神经网络API。打个比方,Tensorflow或者Theano是神经网络的巨人,那么Keras就是站在巨人肩膀上的人。Keras最初是由谷歌工程师开发,原因是帮助在Theano上进行快速的原型开发,用业内评价来说,Theano是一个功能非常强大但也是使用非常繁琐的神经网络框架。因此使用Keras可以大大简化开发流程。而在Tensorflow上也有相同的问题。要想学习Tensorflow,就要先学习谷歌的一套编程范式,像计算图、会话、张量的一些概念。因此谷歌工程师决定把Keras扩展到Tensorflow上,并且最近Tensorflow决定把Keras作为它的软件库进行提供。Keras被认为是构建神经网络的未来,几行代码就可以比原生的Tensorflow实现更多的功能。现在,越来越多的框架为Keras提供支持。
2.Keras的特点:
1)高层API:
Keras由纯Python编写而成。以Tesorflow、Theano、CNTK、DeepLearning4j(基于Java语言的神经网络工具包,使用Keras构建的模型可以直接导入到DeepLearning4j,从而可以在Java中使用)为后端。
(说明同一行代码只要对执行的后台进行修改,便能运行在不同的框架下面。)
2)用户友好:
Keras是为人类而不是天顶星人设计的API。Keras的作者在谷歌工作,Keras已经成为Tensorflow的官方API。
(使用Tensorflow编写的代码如果使用Keras实现通常可以将代码量缩小到原来的三分之一)
3)模块性:
网络层、损失函数、优化器、激活函数、正则化方法(各模块之间相互独立)
4)默认参数:
默认参数有研究支持。
5)产品原型发布:
IOS、Android、Python网页应用后端、JVM、树莓派Raspberry Pi
以上特性说明Keras基于快速实验而生,将idea迅速转化为成果。
- 0赞 · 0采集
-
- MariaBrown 2019-08-26
1.
深度神经网络:

- 0赞 · 0采集
-
- MariaBrown 2019-08-26
1. 在神经网络中,激活函数的作用是能够给神经网络加入一些非线性的因素,使得神经网络可以更好地解决较为复杂的问题。如果没有激活函数,那么感知机以及感知机叠加形成的神经网络也没有办法产生非线性。

因此,在现实的复杂问题中,必须引入非线性因素提高模型的表达能力。
2. 通过sigmoid函数,线性网络可以组成逻辑回归或者多层神经网络。
3.线性神经网络与激活函数:

- 0赞 · 0采集
-
- MariaBrown 2019-08-26
1. 最简单的神经网络——感知器

那么计算机的神经网络是不是通过大量的感知器通过数值交流的一个网络呢?
2. 感知器的数学模型:神经网络的搭建就是通过构造下面的数学表达式,通过求解它的权重系数和偏置值来达到神经网络的构建。

感知器是一个相当简单的模型,但是它的作用非常大。在神经网络当中,它的作用可以近似理解为砖块对于房屋建造的作用。同时,它也有很多的发展空间。既可以通过损失函数发展成为支持向量机,也可以通过堆叠发展成神经网络。
- 1赞 · 0采集
-
- MariaBrown 2019-08-26
1.子集关系及出现顺序:

2. 深度神经网络和深度学习在近几年才被大规模应用,但它的前身人工神经网络在1960年被发明出来,但是到2010年才找到了比较好的训练方法。除此之外,大数据的兴起及GPU并行计算的出现,在带来海量计算力的同时,也带来了海量数据,这才使得无法获得足够数据量和计算力的深度学习成为了可能。由此可见,深度学习的兴起和大规模应用是由于算法、数据和计算能力的综合突破才使得神经网络性能显著提高,并且已经在多个领域得到了突破。像是广告的精准投放,自动驾驶、语音识别、影像识别等领域。当前深度学习的发展方向除了在人工神经网络上叠加深度而形成的深度网络之外,更是提出了卷积计算的卷积神经网络和引入时序模式的循环神经网络,这都将原本只能处理结构化数据的神经网络拓展到了非结构化的文字、图像和语音,使得神经网络的应用场景更加广阔。
3. 神经网络尤其是卷积神经网络很大程度上借鉴了人脑的分层认知结构。卷积神经网络之父Yann LeCun说他在发明卷积神经网络的时候借鉴了人脑的视觉处理部分。

- 0赞 · 0采集
-

- 慕数据6397366 2019-07-26
import numpy as np
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.optimizers import SGD
from keras.layers import Dense
x_data = np.random.rand(100)
noise = np.random.normal(0,0.01,x_data.shape)
y_data = 0.1*x_data + 0.2 + noise
plt.scatter(x_data,y_data)
plt.show()
model = Sequential()
model.add(Dense(1,input_shape=(1,)))
model.compile(optimizer=SGD(),loss="MSE")
for step in range(5001):
cost=model.train_on_batch(x_data,y_data)
if step % 500 ==0:
print("step:",step,"cost:",cost)
W,b = model.layers[0].get_weights()
print("W:",W,"b:",b)
y_pred = model.predict(x_data)
plt.scatter(x_data,y_data)
plt.plot(x_data,y_pred,'r-',lw=3)
plt.show()
- 0赞 · 0采集
-
- 悬壶行者 2019-07-08
神经网络框架
-
截图0赞 · 0采集
-

- 潭兄 2019-03-07
1、前向传播
2、反向传播
3、链式求导
- 1赞 · 0采集









