PostgreSQL 是一个强大且多功能的关系型数据库系统,但查询的效率会显著影响性能。下面,我们将探索几种优化方法,并附带示例,帮助你让 PostgreSQL 查询更顺畅,达到更好的性能。
1. 索引:快速查找的关键索引对于加快数据检索至关重要。它们就像数据库表中的目录一样。让我们来看一个简单的例子:
假设你有一个,员工表:
创建员工表
CREATE TABLE employees (id 自增主键 zìzēng zhǔjiàn,
名字 VARCHAR(100)
部门名称 VARCHAR(100);
薪水字段:数字
;
如果你经常通过部门查询员工,建议创建一个索引:
创建名为 idx_department 的索引,针对 employees 表中的 department 字段;
现在的查询如下:
SELECT * FROM 员工 WHERE 部门 = ‘销售’;
运行速度会快很多,因为PostgreSQL利用索引快速找到相关行。
查询, 性能对比
PostgreSQL 对整个员工表执行了顺序扫描(全表扫描)。这意味着它会逐行扫描,直到找到所有符合条件的行。这个过程会很慢,特别是在数据量很大的时候。
索引的影响: 在索引前后,使用 EXPLAIN 命令来查看:
- 之前:由于Seq Scan成本高昂。
- 之后:使用Index Scan降低成本。
虽然检索所有列可能很有吸引力,但这可能会带来不必要的负担。始终只选择你需要的列:
SELECT * FROM 员工 WHERE salary > 50000;
用法:
以下是一个SQL命令:
SELECT 名字, 工资 FROM 员工表 WHERE 工资 > 50000;
这减少了需要传输和处理的数据量,提升了性能表现。
3. 使用连接 vs 子查询连接通常比子查询更有效率。考虑下面的例子:
如果你想找到这些员工的薪水高于他们部门的平均薪资,你可以写一个子查询来实现。
SELECT 姓名 FROM 员工表 WHERE 薪资 > (SELECT AVG(薪资) FROM employees表 WHERE 名称 = Sales```
)
**查询性能比较:** 连接操作通常会更快,尤其是在适当索引的情况下,因为这样可以让数据库使用高效的算法来合并数据表。
**可读性**:对于关系简单的,连接可以使查询更易读。
**复杂度**:多个联接会使查询更加复杂,更难维护和管理。
而是用一个连接词,比如“和”“但是”。
```sql
SELECT e.name注:在SQL语句中,一般直接使用英文字段名,所以这里保持为 SELECT e.name 更好。如果数据库中的字段名 name 被翻译成中文 ‘名称’,则可以写成 SELECT e.名称。
FROM 员工表e
JOIN (
查询 部门, AVG(薪资) 为 平均薪水
FROM employees
按部门进行分组查询
avg_dept ON e.department = avg_dept.department
其中 e.工资 > avg_dept.平均工资 ;
连接操作可以更高效,尤其是在适当索引的支持下。
查询性能的比较:
- 模块化:子查询可以将复杂的逻辑分解成更易管理的部分。
- 清晰性:可以澄清意图,尤其是在逻辑天然具层次结构的情况下。
- 性能:子查询可能效率较低,特别是对于相关子查询,它们需要为外部查询中的每一行都运行。
- 开销:根据PostgreSQL如何优化它们,它们可能会在执行计划中增加不必要的复杂性。
使用 EXPLAIN 命令来查看执行计划,这对于优化非常重要。
比如说,这个...
```EXPLAIN SELECT * FROM employees WHERE department = '“市场营销”';
找找看:
* **Seq Scan** :表示顺序扫描;如果表很大且这种情况频繁出现,考虑添加索引。
* **Index Scan** :表示正在使用索引,这通常是希望看到的情况。
## 这有助于分辨如下事项等:
* 不准确的统计信息导致不佳的连接/扫描选择
* 维护活动(如 VACUUM 和 ANALYZE)不够充分
* 受损的索引需要执行 REINDEX
* 索引定义与查询不匹配
* work_mem 设置过低,导致无法在内存中进行排序和连接
* 连接顺序的不当选择在编写查询时导致性能不佳
* ORM 配置错误
* EXPLAIN 是 PostgreSQL 中非常有用的工具,能够节省大量时间
# PostgreSQL 查询优化统计说明
* 查询优化器根据存储在 `pg_statistic` 中的统计信息来计算成本。然而,这些数据是以非人类可读的格式存储的,因此不适合直接查看。为了更好地了解表和行的统计信息,可以查看 `pg_stats`。
* 假设这些内部统计信息有偏差(例如,表膨胀或过多的连接导致启发式查询优化器启动)。这样,可能会选择次优计划,导致查询性能不佳。统计数据不好并不一定是个问题;它们可能不会实时更新,很大程度上取决于 PostgreSQL 的内部维护机制。因此,定期执行数据库维护是必要的,包括频繁执行 `VACUUM` 和 `ANALYZE`。
* 如果没有准确的统计信息,你可能会遇到类似这样的情况:
```解释如下查询:解释 SELECT * FROM hospitalization_discharge WHERE visit_times < 2; (从hospitalization_discharge表中选择visit_times小于2的记录)```

在查询前加上 EXPLAIN 后,查询计划会被打印出来,但查询本身不会被执行。因此,我们无法确定存储在数据库中的统计信息是否准确,也无法确定某些操作是否因需要昂贵的 I/O 而未完全在内存中完成。如果与 ANALYZE 一起使用,查询将被执行,并且会打印出查询计划及其内部操作。
如果我们来看上面的第一个查询语句,并且运行 EXPLAIN ANALYZE (而不是 EXPLAIN),我们就能看到:
在 PostgreSQL 中执行如下查询:EXPLAIN 分析 SELECT * FROM hospitalization_discharge WHERE visit_times < 2
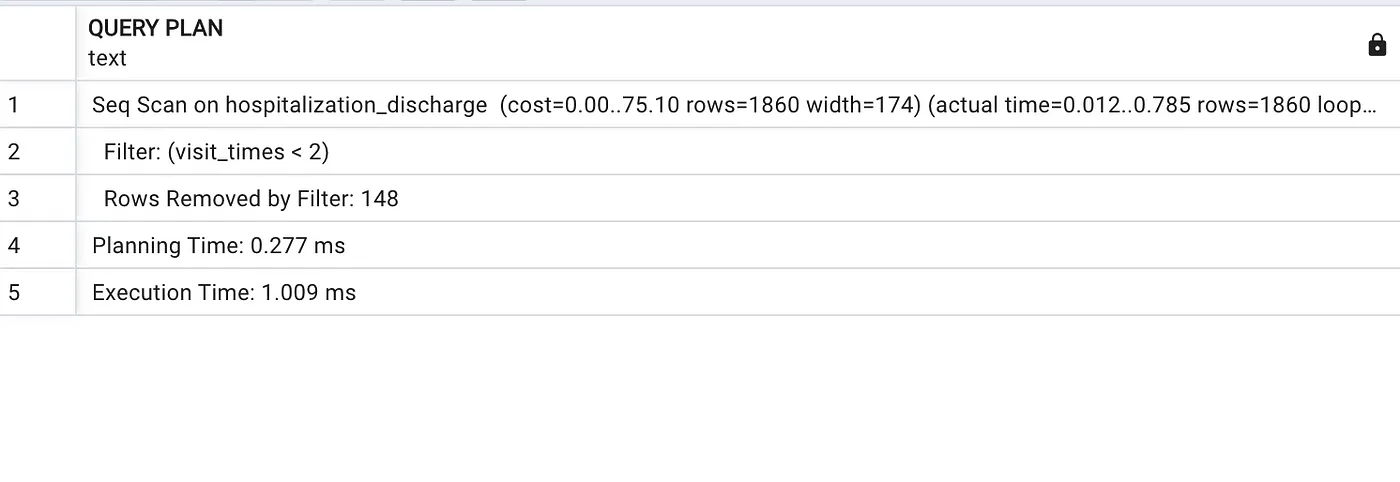
信息还包括实际时间和行数,以及计划时间和执行时间。
**5\. 数据类型优化(例如,将数据从一种类型转换为另一种类型)**
选择合适的数据类型对性能来说非常重要。比如,如果你有一个只用来存储小整数的列,可以使用SMALLINT。
创建产品表。
注:具体列定义需根据实际需求补充。
id 序列型 PRIMARY KEY,
名字 VARCHAR(100)
股票代码 SMALLINT
);
这可以减少存储空间并提高缓存性能。
## 6\. 通过事务处理限制锁定
锁可能会拖慢你的查询速度,尤其是在高并发场景下。为了尽量减少锁问题:
* 保持交易简洁。例如,当你需要更新多行时,批处理更新可以有所帮助:
开始吧
更新 employees 表,将 salary 字段设置为 salary * 1.1,其中 department 为 ‘工程部门’;
COMMIT;
通过使交易简洁,就能减少锁的时间。
## 7\. 维护保养
定期维护对保持最佳性能至关重要。你可以使用以下命令:
* **VACUUM**:清理存储空间,提升性能。
清空员工;
* **分析**:更新查询优化器的统计信息。
分析一下公司里的员工,
## 8\. 利用物化视图来
对于不需要实时数据的复杂查询情况,可以考虑采用物化视图。物化视图会将查询结果物理地存储起来,从而提升性能。
比如说:
```sql
CREATE MATERIALIZED VIEW department_avg_salary AS部门平均薪资如下:
下面的SQL语句创建了一个物化视图,用于存储每个部门的平均薪资。
SELECT 部门, AVG(工资) as avg_salary
FROM employees
按部门分;
;
你可以随时刷新这个视图,这样可以快速访问各部门平均薪资,不必每次都重新计算。
性能调优中的扫描类型和连接类型的快速回顾
每种连接类型和扫描类型都有其适用的时间和场合。有些人一看见“顺序扫描”这个词就感到害怕,却没有考虑是否有更合适的方式来访问数据。例如,对于只有两行的表,在这种特定情况下,查询优化器不会选择先扫描索引,然后再从磁盘中检索数据,而会选择直接扫描表并提取数据,而不接触索引。在这种情况下,以及对于大多数小表来说,顺序扫描会更高效。
回顾PostgreSQL支持的各种联接和扫描类型:
扫描种类
逐个扫描
- 从磁盘进行暴力读取
- 扫描整张表
- 对小表来说较快
查看索引:
- 扫描索引中的所有/某些行;查找堆组织表中的行
- 造成随机寻址,对于传统的机械硬盘来说效率较低
- 当从大表中提取少量行时,比顺序扫描要快
仅索引扫描,
- 扫描索引中的所有或某些行
- 不需要在表中查找行,因为我们需要的值已经在索引中了
位图扫描:
- 扫描索引,生成一个要访问页面的位图。
- 只在表中查找对应记录来获取所需的行。
连接方式
嵌套循环:
- 为外层表的每一行在内层表中查找匹配的行
- 启动迅速,最适合小规模的表
合并联接:
- 在已排序的数据集上执行拉链操作
- 适合处理大表
- 如果需要额外排序,启动成本会比较高
哈希 join:
- 构建内部表值的哈希,扫描外部表查找匹配项
- 仅适用于等值查询
- 启动耗时但执行迅速
再次强调,每种扫描类型和连接方式都有其适用之处。重要的是查询优化器要有准确的统计数据来参考。
最后优化 PostgreSQL 查询涉及智能的索引策略、高效编写 SQL、理解执行计划和定期维护的结合。通过应用这些技术和示例,你可以显著提升 PostgreSQL 数据库的性能,从而使得查询响应更快,数据处理更高效。祝你优化顺利!