相信大家都知道Python入选山东小学教材、浙江省信息高考的事儿,那么如果有一天Python正式进入高考,会有哪些题目?你又能不能做出来呢?
那么今天就斗胆出一回题,请诸位高才作答——
1、送分题
完形填空:人生苦短,_______。
答案:我用Python
2、基础题
简答:这两个参数是什么意思:*args,**kwargs?我们为什么要使用它们?(某面试题)
答案:如果我们不确定要往函数中传入多少个参数,或者我们想往函数中以列表和元组的形式传参数时,那就使要用*args;如果我们不知道要往函数中传入多少个关键词参数,或者想传入字典的值作为关键词参数时,那就要使用**kwargs。args和kwargs这两个标识符是约定俗成的用法,你当然还可以用*bob和**billy,但是这样就并不太妥。
3、实操题
项目考核:如何用Python爬取《王者荣耀》皮肤图片?(新手爬虫实战案例)
答案:
以下是参考答案
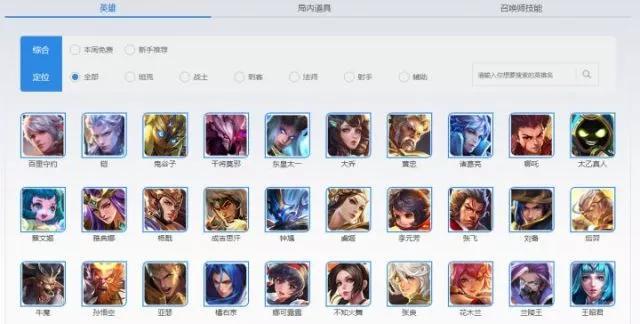
首先进入所有英雄列表,你会看到下图
{kind=link}
在这个网页中包含了所有的英雄,头像及英雄名称。
单个英雄
点击其中一个英雄的头像,例如第一个“百里守约”,进去后如下图:
网址为https://pvp.qq.com/web201605/herodetail/196.shtml
{kind=link}
网址中196.shtml以前的字符都是不变的,变化的只是196.shtml。而196是“百里守约”这个英雄所对应的数字,要想爬取图片就应该进入每个英雄皮肤图片所在的网址,而所有英雄的网址的关键就是每个英雄对应的数字。那么这些数字怎么找呢?
英雄数字
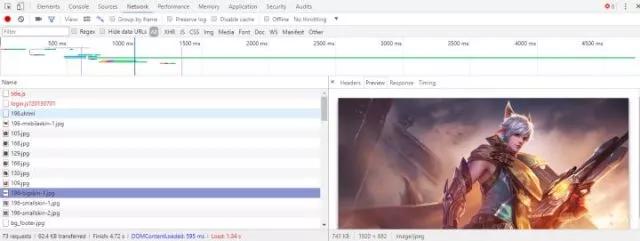
在所有英雄列表中,打开浏览器的开发者工具,刷新,找到一个json格式的文件,如图所示:
{kind=link}
这时就会看到所有英雄对应的数字了。在上图所示的Headers中可以找到该json文件对应的网址形式。将其导入Python,把这些数字提取出来,然后模拟出所有英雄的网址即可
小节代码如下(Ubuntu(Linux)系统):
#爬取王者荣耀英雄图片 #导入所需模块 import requests import re import os #导入json文件(里面有所有英雄的名字及数字) url='http://pvp.qq.com/web201605/js/herolist.json' #英雄的名字json head={'User-Agent':'换成你自己的head'} html = requests.get(url,headers = head) html=requests.get(url) html_json=html.json() #提取英雄名字和数字 hero_name=list(map(lambda x:x['cname'],html_json)) #名字 hero_number=list(map(lambda x:x['ename'],html_json)) #数字下载图片
现在可以进入所有英雄的网址并爬取网址下的图片了。进入一个英雄的网址,打开开发者工具,在NetWork下刷新并找到英雄的皮肤图片(记住是大图)。如图所示:
{kind=link}
然后在Headers中查看该图片的网址。会发现皮肤图片是有规律的。我们可以用这样的方式来模拟图片网址:'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/'+str(v)+'/'+str(v)+'-bigskin-'+str(u)+'.jpg',在该网址中只有str(v)与str(u)是改变的(str( )是Python中的一个函数),str(v)是英雄对应的数字,str(u)只是图片编号,例如第一个图片就是1,第二个就是2,第三个……而一个英雄的皮肤应该不会超过12个(可以将这个值调到20等)。接着就是下载了。
下载的代码如下(有些地址要换成你自己的):
下载的代码如下(有些地址要换成你自己的):
{kind=link}
执行完上面的代码后只需要执行main函数就行了
爬取下来的图片是这样,每个文件夹里面是该英雄对应的图片,如下图:
{kind=link}
以上呢就是整理的几个Python考题了,不知道你会做几道呢?