简述
Kudu 是 Cloudera 开源的新型列式存储系统,是 Apache Hadoop 生态圈的成员之一。它专门为了对快速变化的数据进行快速的分析,填补了以往Hadoop 存储层的空缺。
本篇文章将会介绍几种数据数据同步到 Kudu 的方案选择,然后从功能和使用角度介绍 CloudCanal 如何帮助我们解决数据实时同步到 Kudu。
几种方案
Kudu 是一个存储层组建,若要同步数据到 Kudu 的可以有三种选择
- (基于RDB)选用类似 DataX 这类开源中间件,同时 Kudu 搭建上层 SQL 引擎。可选的 SQL 引擎有:Hive、Impala
- (基于MQ)选用 Kafka 生态,基于 Kafka + Flume + Kudu 实现数据同步。
- (基于编码)开发对应的数据迁移程序,直接将数据写入 Kudu 存储。
如何选择?
基于RDB方案
- 需要 Kudu 上层有一个 SQL 引擎。在官方文档上提到了两种使用Kudu 的方式
- Hive 是基于 MapReduce 架构、Impala 是基于 MPP 架构
- 单纯的数据写入并不需要复杂的计算逻辑,选择 MPP 架构显然更适合一些。
- 这种情况下推荐 Impala + Kudu + DataX
基于MQ方案
- 比较适合源端数据变化有多个不同的消费者,数据同步仅仅是其中一条链路。
基于编码方案
- 比较适合在数据同步过程中需要对数据进行加工。
同步的技术点
建表
- 对于 Kudu 上的建表需要通过 kudu-client 来进行,例如:
List<ColumnSchema> columns = new ArrayList(2);
columns.add(new ColumnSchema.ColumnSchemaBuilder("key", Type.INT32).key(true).build());
columns.add(new ColumnSchema.ColumnSchemaBuilder("value", Type.STRING).build());
List<String> rangeKeys = new ArrayList<>();
rangeKeys.add("key");
Schema schema = new Schema(columns);
client.createTable(tableName, schema, new CreateTableOptions().setRangePartitionColumns(rangeKeys));
- Kudu 由于存储引擎限制,每张表必须要指定 Partition Column。
- 被设置为 Partition 的列不允许 update,如若修改 Partition Column 列的值。需要删除整行数据重新插入。
数据写入
- Kudu 数据写入 Kudu 支持 Insert、Update、Delete、Upsert 四种操作
KuduTable table = client.openTable(tableName);
KuduSession session = client.newSession();
session.setTimeoutMillis(60000);
for (int i = 0; i < 3; i++) {
Insert insert = table.newInsert();
PartialRow row = insert.getRow();
row.addInt(0, i);
row.addString(1, "value " + i);
session.apply(insert);
}
session.flush();
session.close();
数据类型
- Kudu 1.6 之前,不支持 Decimal。因此源端数据类型如果是浮点数只可以选择:float、double、int、string 来承载
- Kudu 1.15 开始,提供了 varchar 类型可以与 数据库的 varchar 相互对应。在此之前应当选择 string 类型。
基于 CloudCanal 快速实现数据同步
前面介绍的三种方式中 RDB方案要求增加配置 SQL 引擎、MQ 方案 则要求增加 Kafka 和 Flume。它们的数据同步链路都较长一旦出现问题,比较不容易排查原因所在。CloudCanal 是采用了第三种方式。
- 从源端直接订阅数据变更
- 通过 kudu-client 直接将数据写入到 Kudu 存储引擎
- 整个过程无需 MQ 或 SQL 引擎的支持。
对比前面两种方式具有下列几个优势
- 资源开销小
- 链路简单高效
- 产品化操作便捷
举个"栗子"
准备 CLOUDCANAL
添加数据源
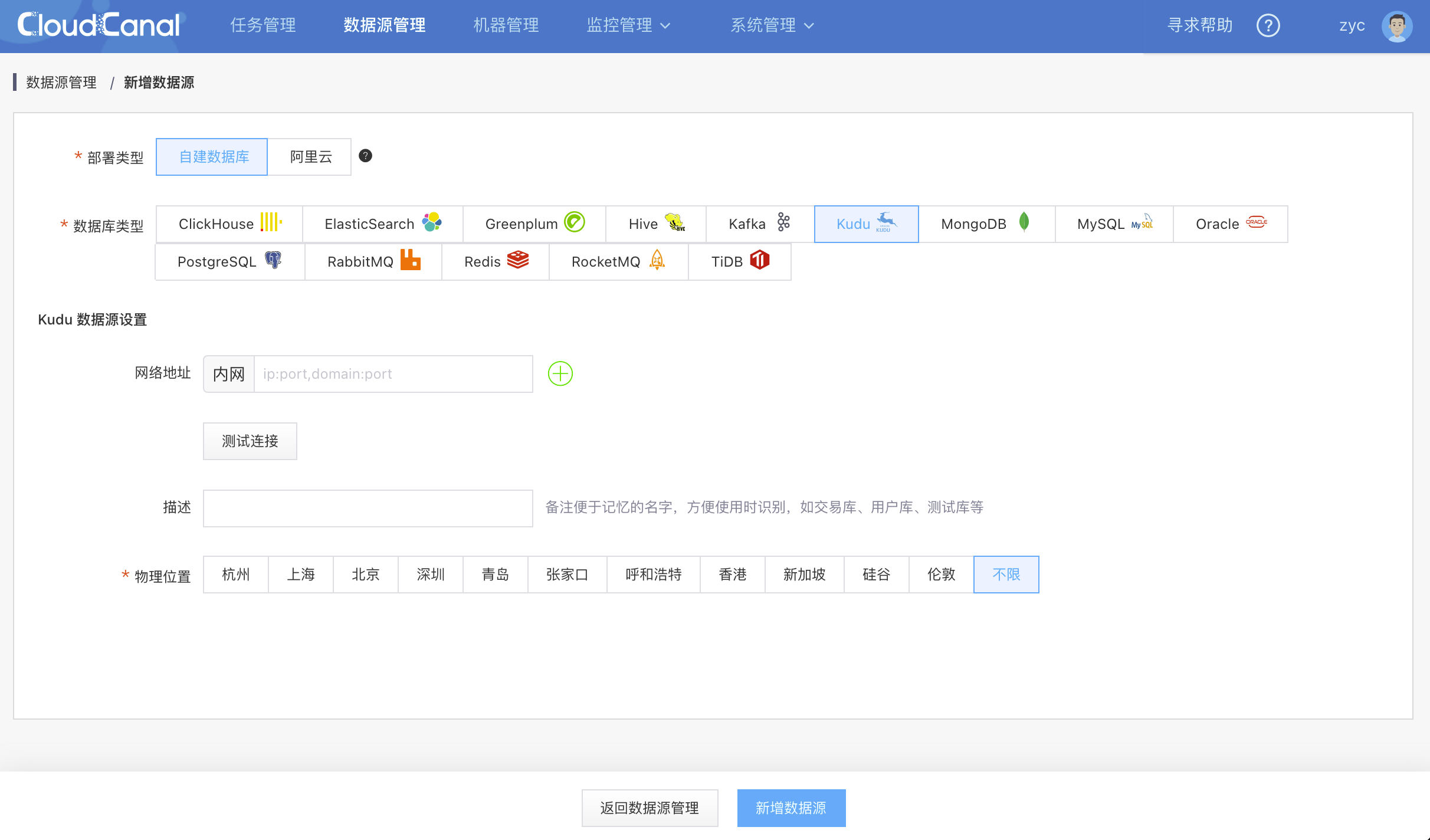{kind=link}
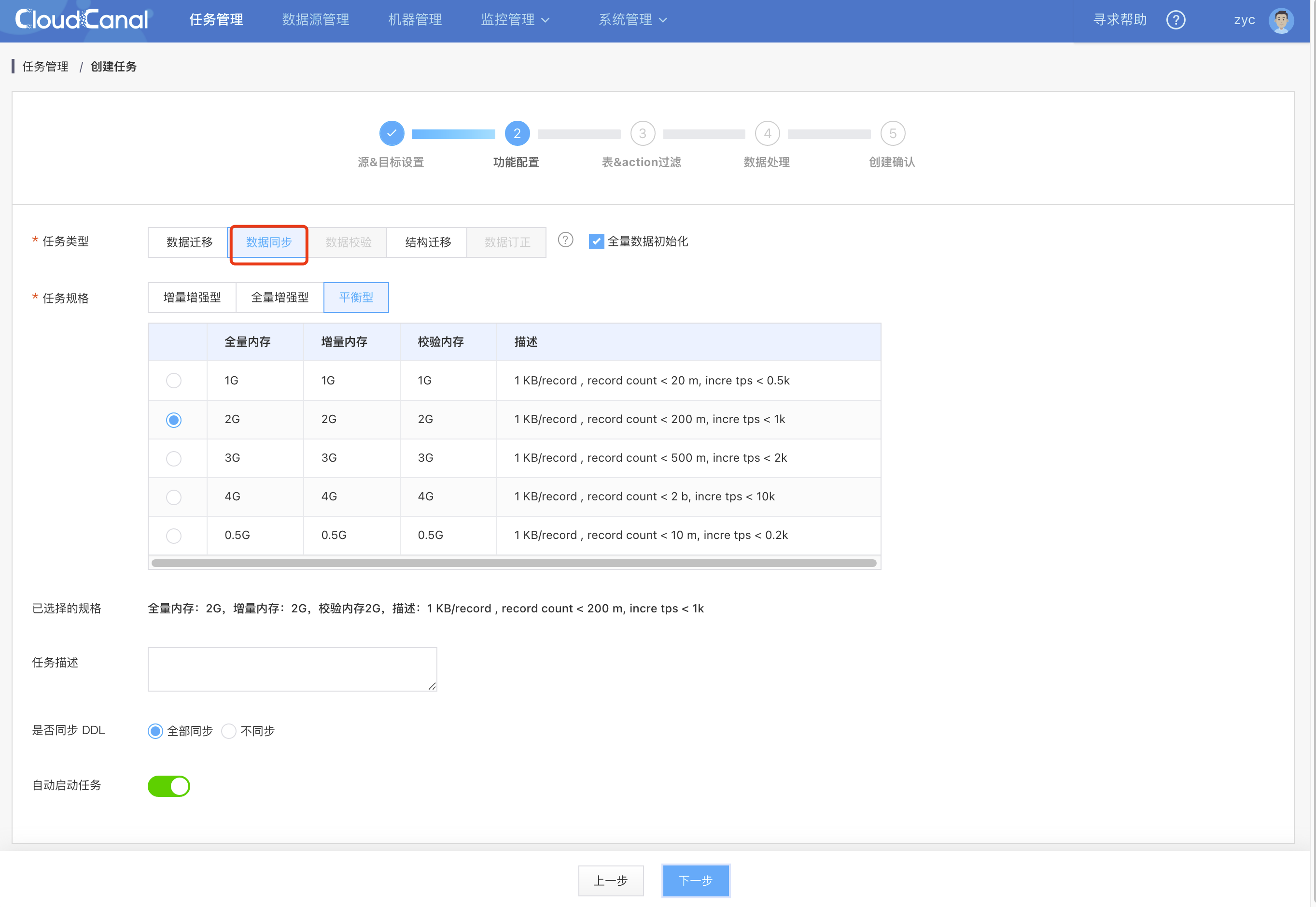
同步任务
{kind=link}
{kind=link}
{kind=link}
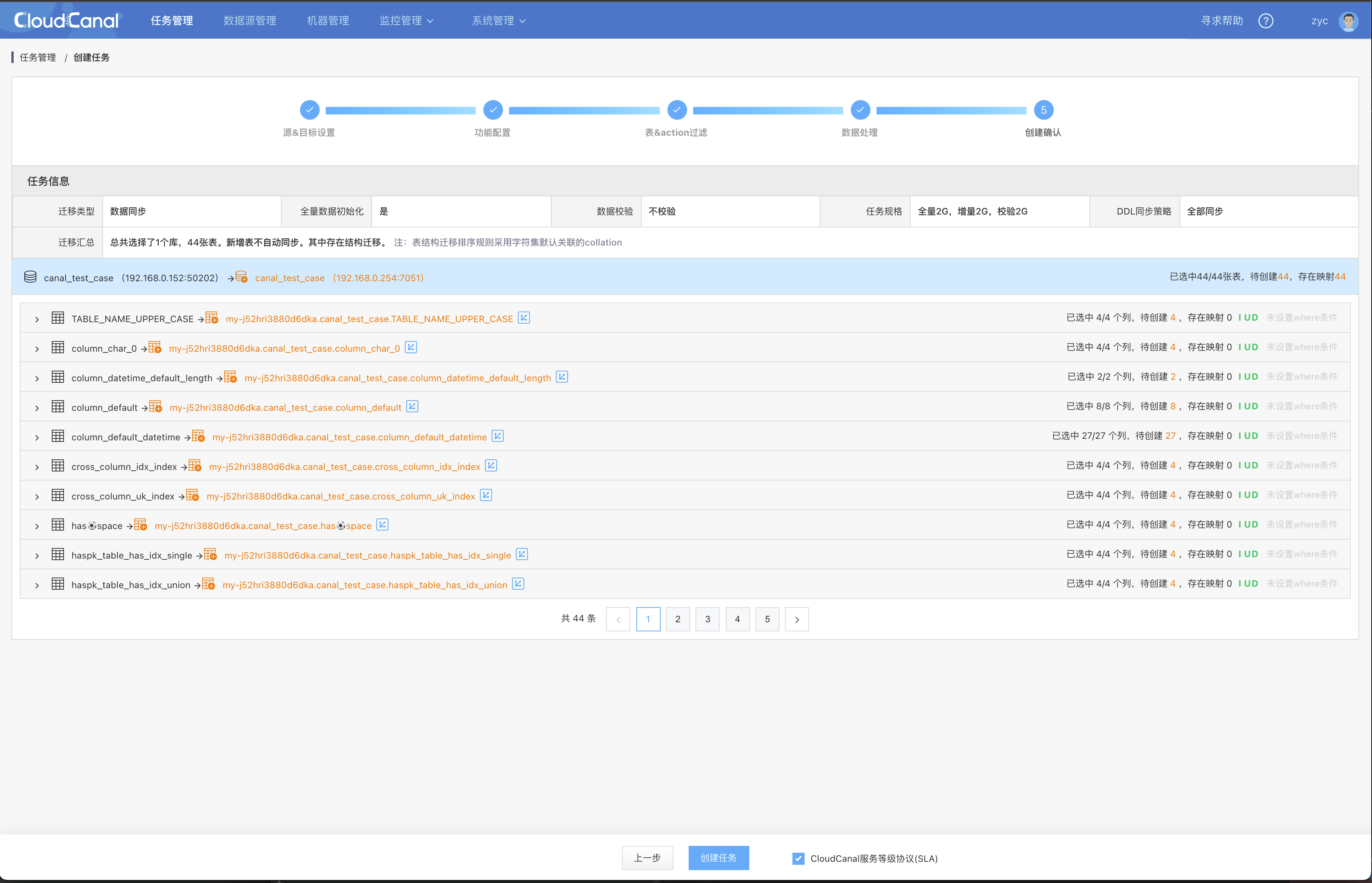{kind=link}
{kind=link}
在最后举例使用 Impala 来查询位于 Kudu 中的数据,如下是建表语句:
CREATE EXTERNAL TABLE `canal_test_case_column_default` STORED AS KUDU
TBLPROPERTIES(
'kudu.table_name' = 'my-j52hri3880d6dka.canal_test_case.column_default',
'kudu.master_addresses' = '192.168.0.254:7051')
{kind=link}
能力和限制
- 支持 MySQL、PostgreSQL、Oracle 作为源端到 Kudu 的同步
- 支持主键变更同步,转换为 Kudu 删除在插入
- 对端 Kudu 要求 1.6 版本
- 不支持源端 无主键表
- 不支持 DDL 增量同步
总结
本文简单介绍了几种将数据同步到 Kudu 的方式,以及基于 CloudCanal 是如何实现实时同步数据到 Kudu。各位小伙伴,如果觉得还不错,请点赞、评论加转发吧。