简述
本文介绍如何通过 CloudCanal,五分钟内创建一条长期稳定运行的 MySQL -> ElasticSearch (以下简称 ES) 实时数据迁移同步链路 。
技术内幕
限流
MySQL 到 ES 数据迁移同步过程中,往往会面临源端写入对端 RPS 较大问题,导致 ES 负载较大,影响业务对 ES 的正常读写。CloudCanal 为了应对这个情况,提供限流能力。同步任务创建完毕后,可在 任务详情 -> 参数设置 对源端流量进行限流。
{kind=link}
时区处理
CloudCanal 允许用户在创建数据迁移同步任务时指定时区。写入ES 时,源端时间类型数据将会格式化并带上时区信息 , 支持用户在跨国、跨地域场景下使用。
自动创建索引和 Mapping 结构
CloudCanal 迁移同步任务支持自动将源端数据库表结构映射成 ES 索引,该过程中允许用户在 列(column/field) 级别上,个性化设置自己需要的索引和 Mapping 结构。这些设置包括:
- 每个列可以指定是否需要索引
- 可以对 text 类型的 field 设置 ES mapping 中的分词器(标准分词器)
- 索引分片数、副本数自定义设置
映射已建索引
用户可能已经在 ES 中提前建好了索引,这种情况下 CloudCanal 会自动探测,并允许用户配置映射,一张表可映射对端一个索引。
内置 _id 生成和 routing field 指定
写入 ES 时候 _id 用于唯一标识一个 doc。CloudCanal 数据同步默认遵循以下原则:
- routing 使用 _id 值
- 单主键表,会默认使用源端关系表的主键列的列值作为 _id 的值
- 多主键表,会通过分隔符$连接多个主键列的值,组成唯一的 _id 值
- 无主键表,会将所有列的值通过$连接,生成唯一的 _id 值
举个"栗子"
准备 CloudCanal
- 如没有安装 CloudCanal,请参考[《CloudCanal安装教程》]安装。下面例子介绍如何创建一个 MySQL->ElasticSearch 的迁移同步任务。
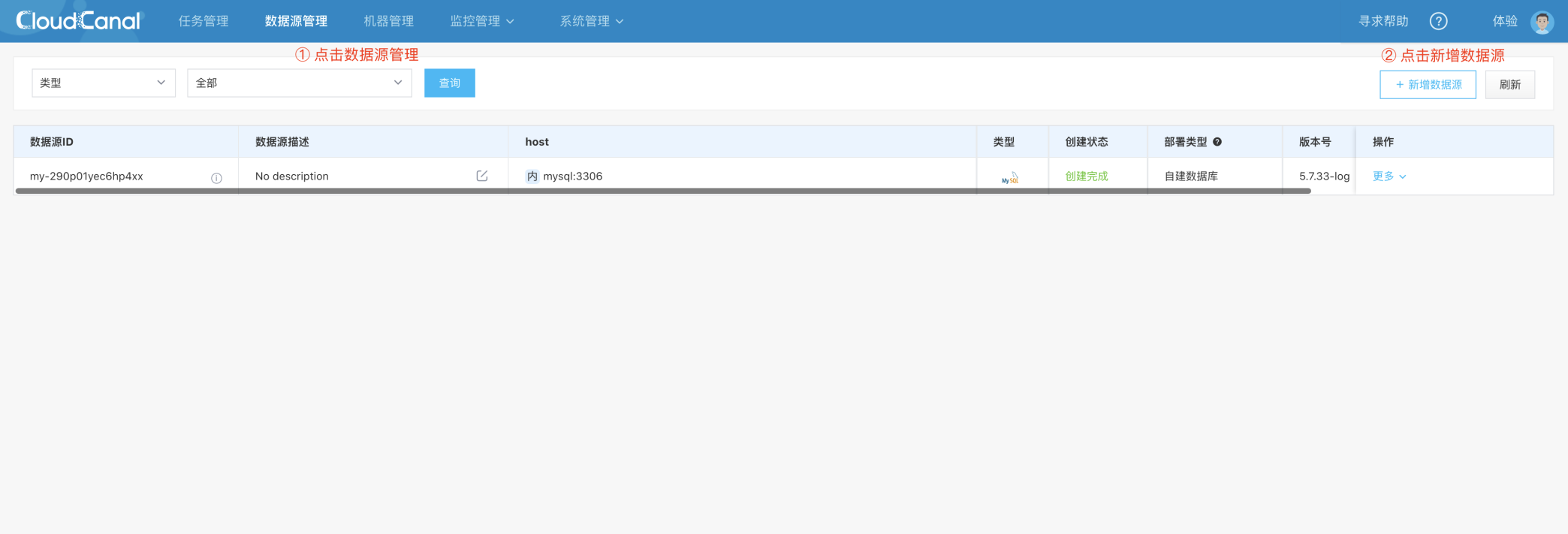
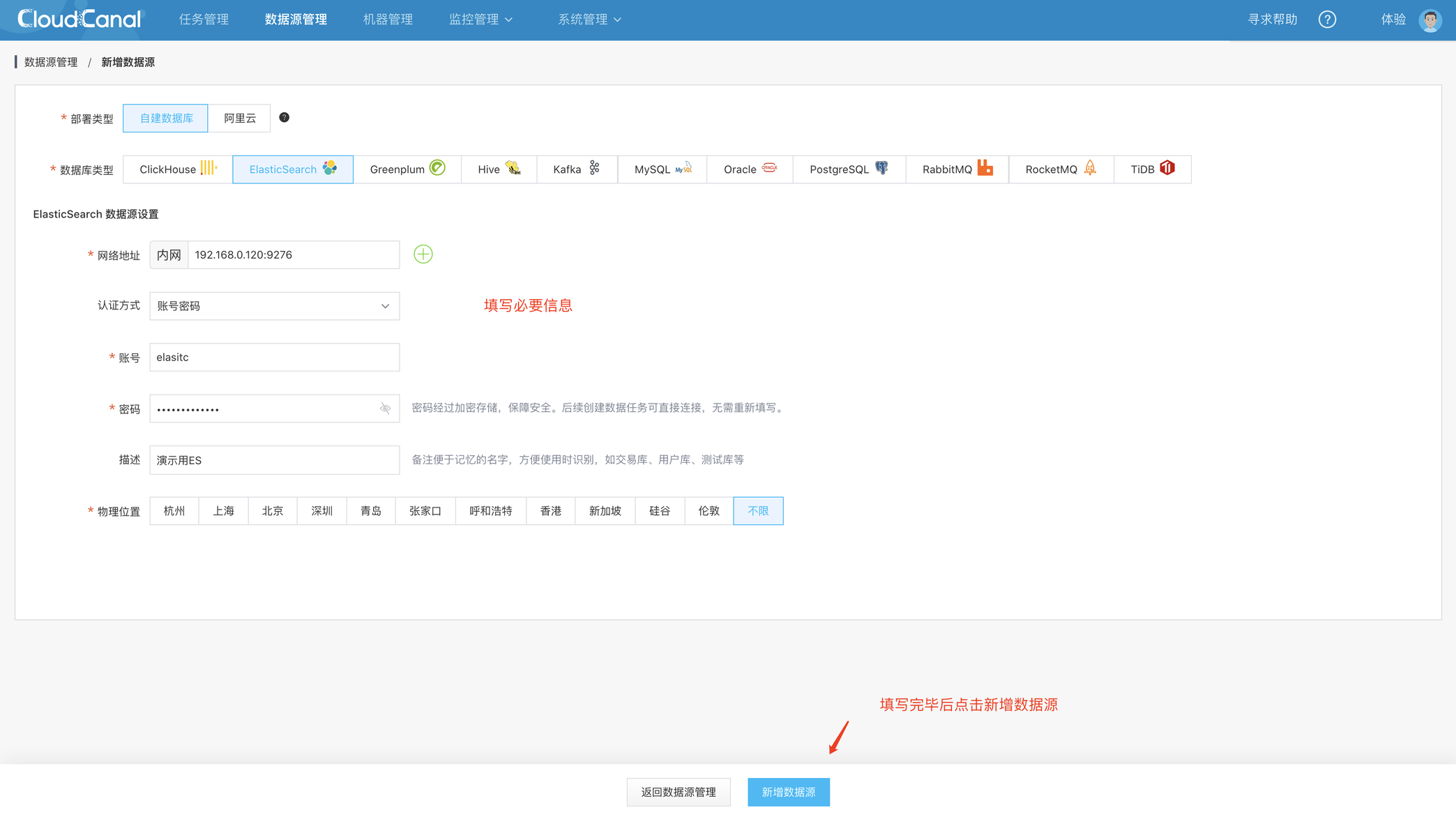
添加数据源
{kind=link}
{kind=link}
创建任务
{kind=link}
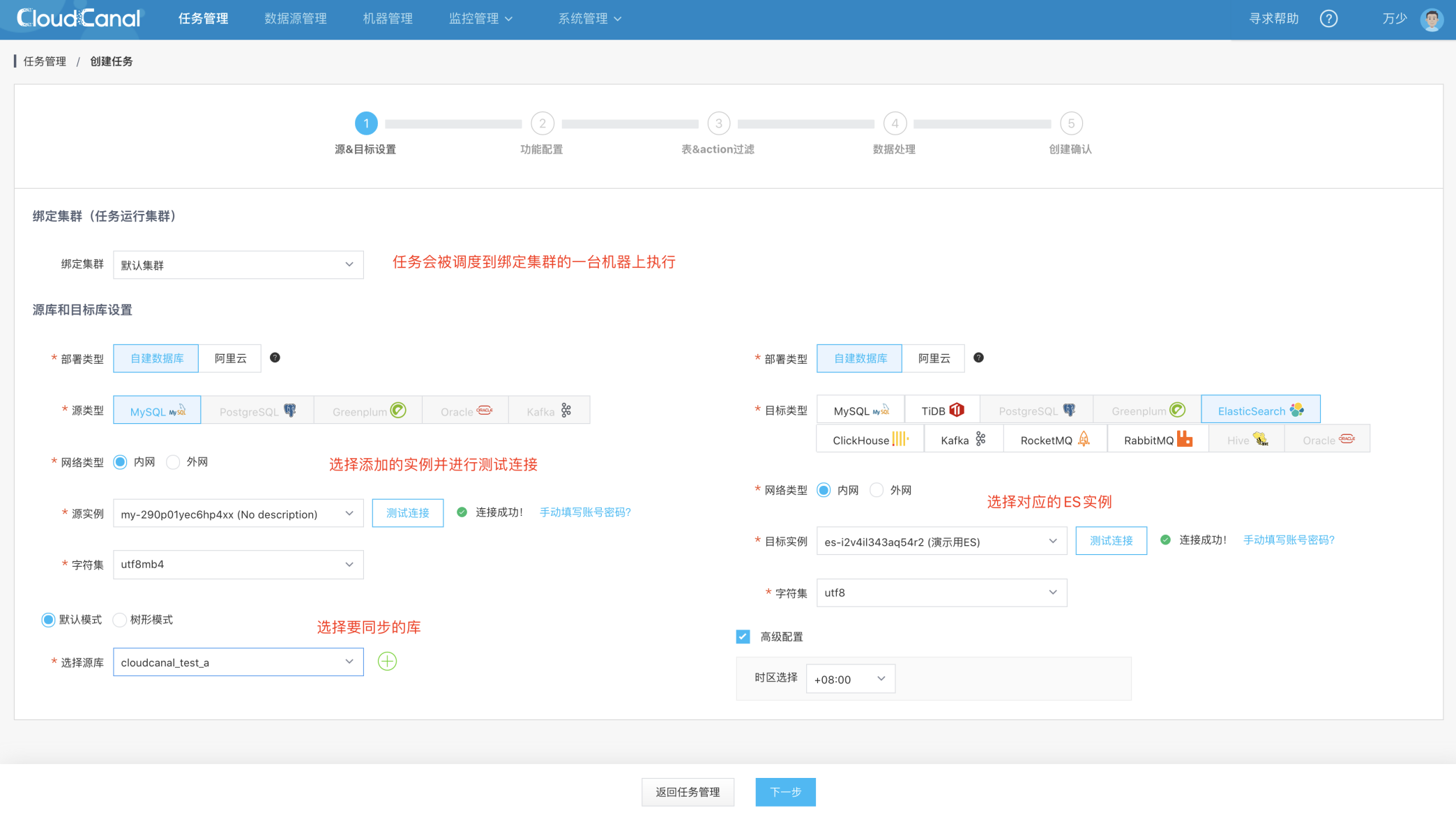
数据源设置
{kind=link}
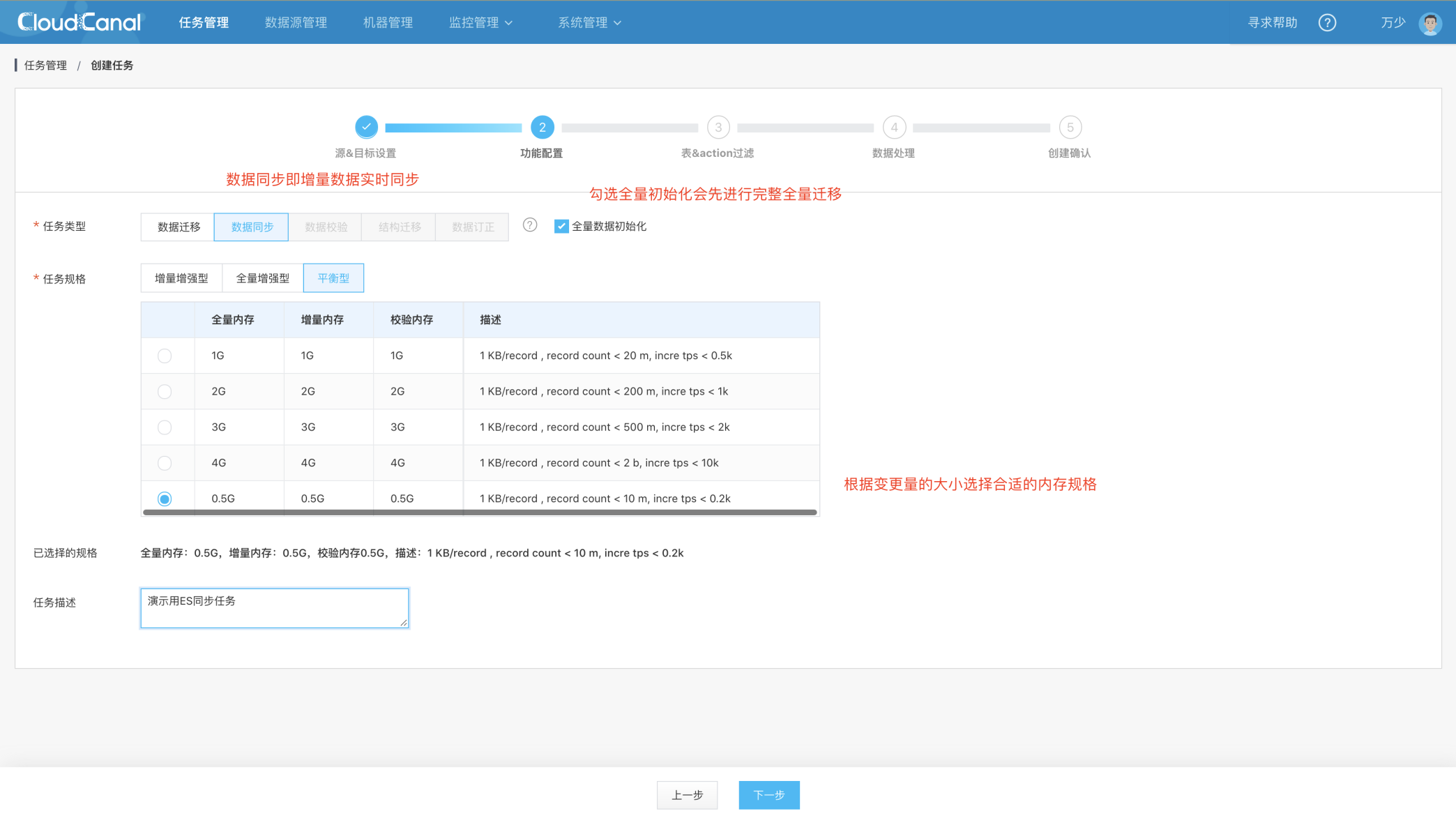
功能配置
{kind=link}
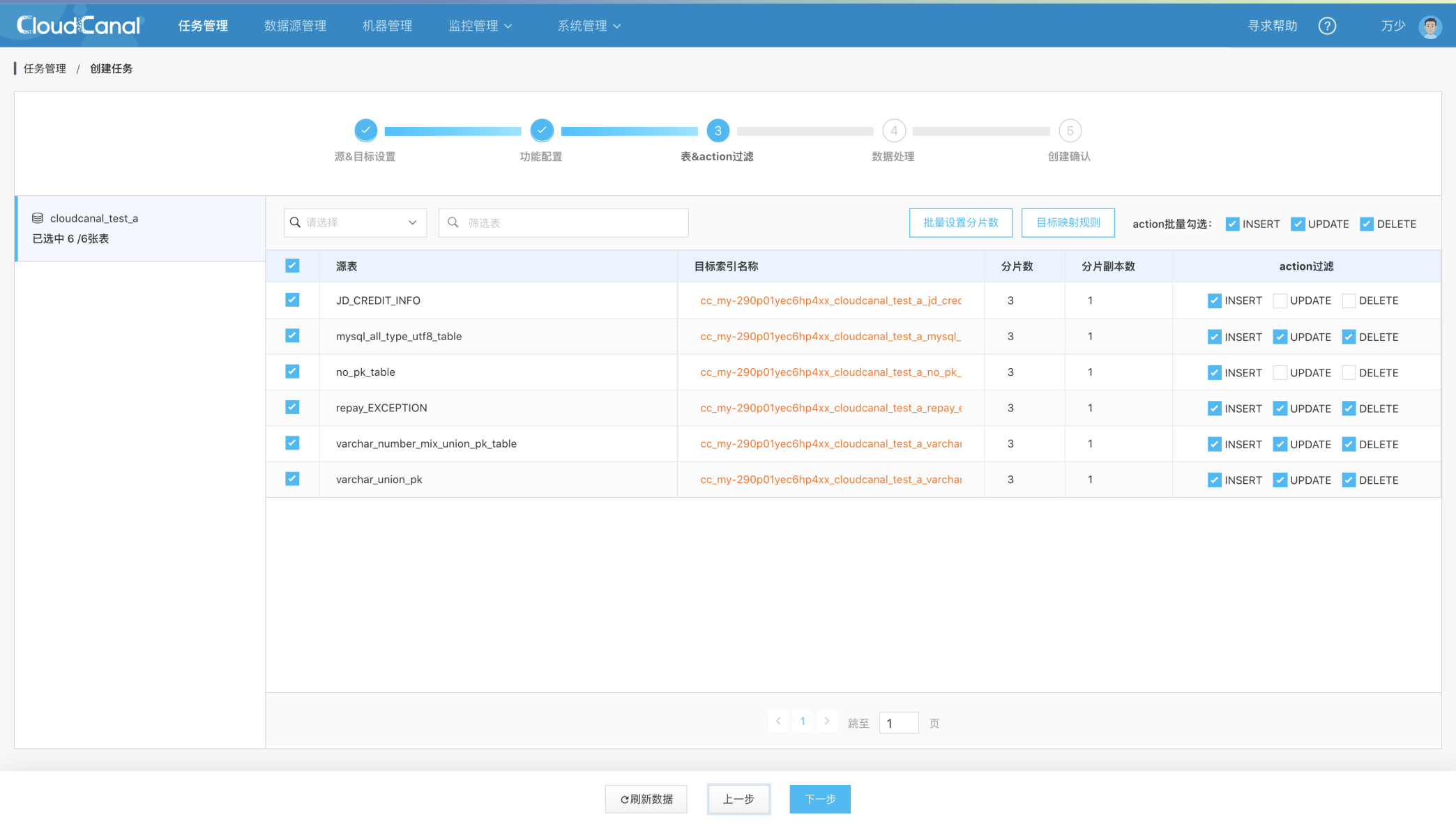
表&ACTION过滤
{kind=link}
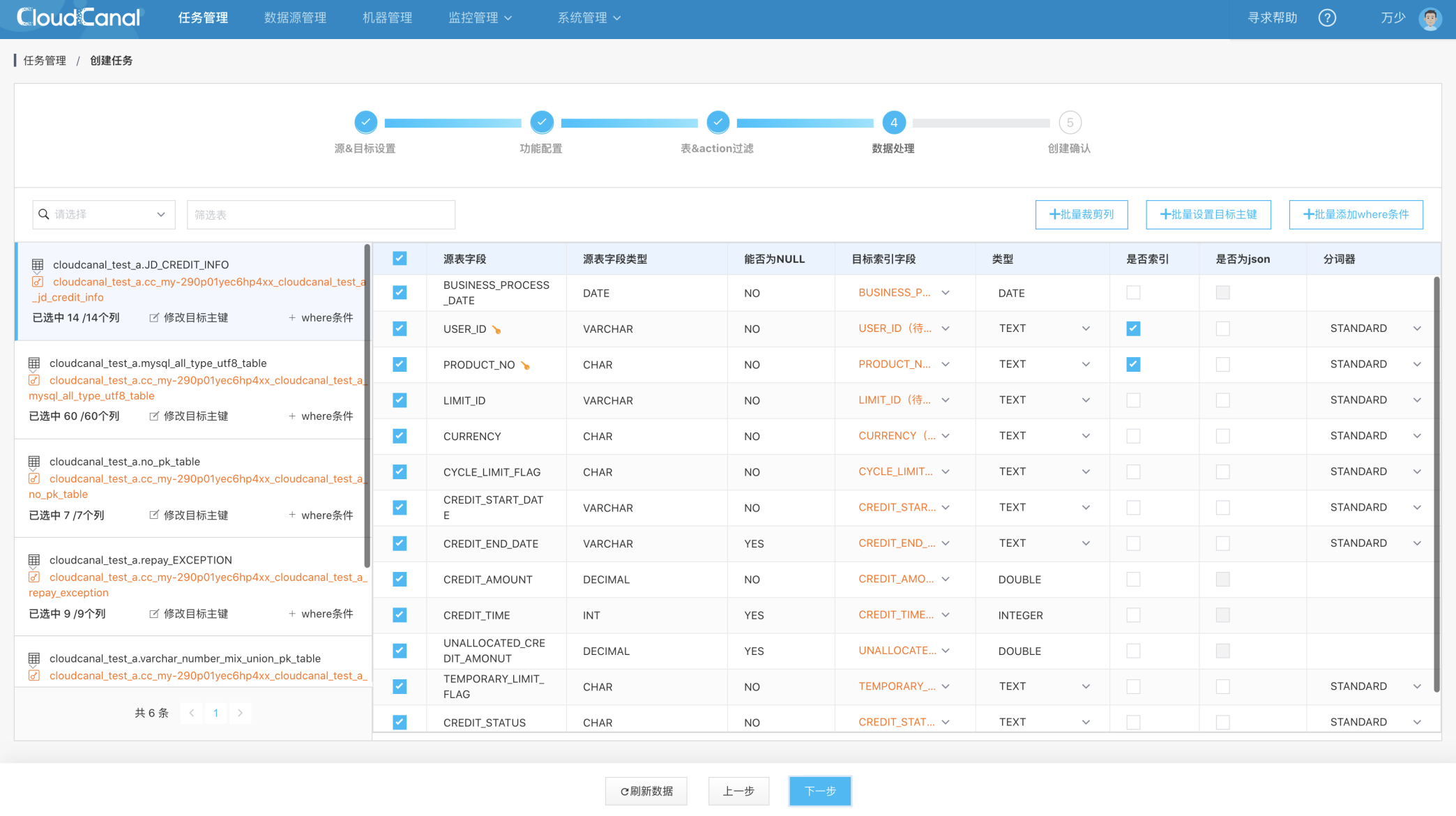
数据处理
{kind=link}
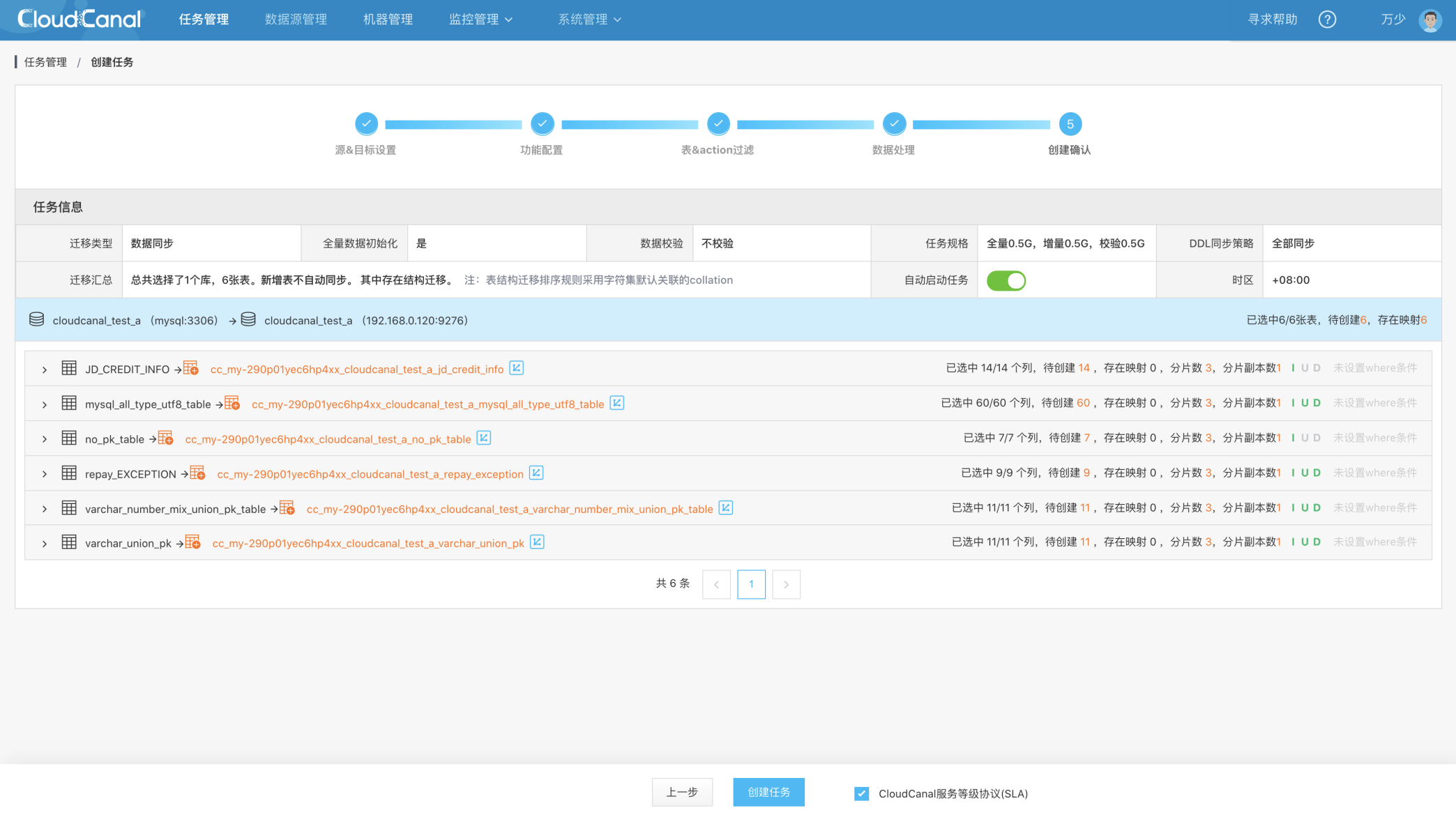
创建确认
{kind=link}
查看任务状态
{kind=link}
{kind=link}
总结
本文简单介绍了如何使用 CloudCanal 快速构建 MySQL->ElasticSearch 数据迁移同步链路,更多的源端和目标端陆续开放。各位小伙伴,如果觉得还不错,请点赞、评论加转发吧。