-

- 潮听哥 2022-11-15

HDFS写流程
客户端向NameNode发起写数据请求
分块写入DataNode节点,DataNode自动完成副本备份
DataNode向NameNode汇报存储完成,NameNode通知客户端

HDFS读流程
客户端向NameNode发起读数据请求
NameNode找出距离最近的DataNode节点信息
客户端从DataNode分块下载文件
- 0赞 · 0采集
-
- 潮听哥 2022-11-15

HDFS分布式文件系统:存储是大数据技术的基础
HDFS总结
普通的成百上千的机器
按TB甚至PB为单位的大量的数据
简单便捷的文件获取
HDFS概念
数据块:数据块是抽象块而非整个文件作为存储单元,默认大小为64M,一般设置为128M,备份X3
NameNode:管理文件系统的命名空间,存放文件元数据,维护着文件系统的所有文件和目录,文件与数据块的映射,记录每个文件中各个快所在数据节点的信息
DataNode:存储并检索数据块,向NameNode更新所存储块的列表
HDFS优点:
适合大文件存储,支持TB、PB级的数据存储,并有副本策略
可以构建在廉价的机器上,并有一定的容错和恢复机制
支持流式数据访问,一次写入,多次读取最高效
HDFS缺点:
不适合大量小文件存储
不适合并发写入,不支持文件随机修改
不支持随机读等低延时的访问方式
- 0赞 · 0采集
-

- 慕虎0477422 2022-03-15
两个思考问题 :
1.数据块的大小设置为多少合适为什么?
hadoop数据块的大小一般设置为128M,如果数据块设置的太小,一般的文件也会被分割为多个数据块,在访问的时候需要查找多个数据块的地址,这样的效率很低,而且如果数据块设置太小的话,会消耗更多的NameNode的内存;而如果数据块设置过大的话,对于并行的支持不是太好,而且会涉及系统的其他问题,比如系统重启时,需要重新加载数据,数据块越大,耗费的时间越长。
2.NameNode有哪些容错机制,如果NameNode挂掉了怎么办?
NameNode容错机制,目前的hadoop2可以为之为HA(高可用)集群,集群里面有两个NameNode的节点,一台为主节点,一台为从节点(备用节点),两者的数据时刻保持一致,当主节点出现问题时,备用节点可以自动切换,用户基本感知不到,这样就避免了NameNode的单点问题。
HDFS写流程:

写流程:
1.客户端向NameNode发起写数据2.分块写入DataNode节点,DataNode自动完成副本备份
3.DataNode向NameNode汇报存储完成,NameNode通知客户端
HDFS读流程:

1.客户端向NameNode发起读数据的请求;
2.NameNode找出距离最近的DataNode节点信息返回给客户端 ;
3.客户端从DataNode上面分块的下载文件;- 0赞 · 0采集
-
- 慕虎0477422 2022-03-15
Hadoop 是一个开源的大数据框架;也是是一个分布式计算的解决方案;
那么Hadoop+HDFS(分布式文件系统)+MapReduce(分布式计算);
Hadoop 核心:HDFS 分布式文件系统:存储是大数据计算的基础,没有这个做不了大数据;
MapReduce(分布式计算):编程模型,分布式计算是大数据应用的解决方案;
HDFS总结:有很多特性支持大数据的存储,为了大量数据横跨成百上千的机器,用数据跟本地调用一样简单,HDFS自动搞定;
1、普通的成百上千的机器;
2、按TB甚至PB为单位的大量数据;
3、简单便捷的文件获取;
概念:1、数据块;数据块是抽象概念的块而非整个文件作为存储单元;
块默认大小64M,一般设置128M,(副本策略)备份X3;比如存10M文件,那么这个文件独占一个文件,如果300M文件,那么会占3份;这样会简化存储数据的设计,提升数据的容错能力和扩容性;;
2、NameNode;主 ,管理文件系统的命名空间和存放文件元数据;维护着文件系统的所有文件和目录,文件和数据库的映射;
记录每个文件各个块所在数据节点的信息;
如果namenode挂了咋办?百度
3、DataNode 从的关系,一般一个namenode主,多个从;
datanode ,存储并检索数据块,向namenode更新所存块的列表;
HDFS优点:
1、适合大文件的存储,支持TB、PB级的数据存储,并有副本策略;
2、可以构建在廉价的机器上,并有一定的容错和恢复机制;
3、支持流式数据访问,一次写入,多次读取取最高效;
缺点:
1、不适合大量小文件存储;
2、不适合并发写入,不支持文件随机修改,只能后续添加apd;
3、不支持随机读等低时延的访问方式;
问题;1、数据块的大小设置多少合适?为啥?
2、namenode有哪些容错机制,他如果挂掉咋办?- 0赞 · 0采集
-

- 慕田峪6251699 2021-11-30
HBase简介

- 0赞 · 0采集
-
- 慕田峪6251699 2021-11-30
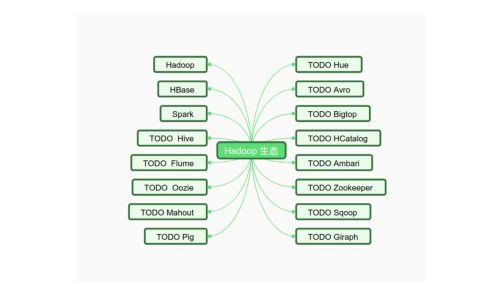
Hadoop生态
- 0赞 · 0采集
-
- 慕田峪6251699 2021-11-30
Hadoop总结

- 0赞 · 0采集
-
- 慕田峪6251699 2021-11-30
Hadoop

- 0赞 · 0采集
-
- 慕田峪6251699 2021-11-30
Hadoop的基础架构
- 0赞 · 0采集
-
- 慕田峪6251699 2021-11-30
Hadoop基础架构
- 0赞 · 0采集
-
- 慕田峪6251699 2021-11-30
HDFS写流程和读流程


- 0赞 · 0采集
-

- William阿千 2021-11-04
Hadoop基础与演练
大数据是一个概念也是一门技术,是在以Hadoop为代表的大数据平台框架上进行各种数据分析的技术。
大数据包括了以Hadoop和Spark为代表的基础大数据框架
还包括实时数据处理,离线数据处理;数据分析,数据挖掘和用机器算法进行预测分析等技术
大数据的前景
PC时代->移动互联网->物联网
PC->云计算->大数据
大数据肯定是一个好的方向,大数据的相关人才还是稀缺的,现在学大数据还不晚,坚持地走下去就行了!
- 0赞 · 0采集
-

- ssslever 2021-08-07
mapreduce编程模型:

yarn 资源管理器:
resourcemanagerapplicationmaster
nodemanager
- 0赞 · 0采集
-
- ssslever 2021-08-07
hadoop有主节点和一套备用节点,主节点挂了就直接用备用节点。解决namenode的单点问题。
hdfs 写流程:

hdfs读流程:

- 0赞 · 0采集
-
- ssslever 2021-08-07
hdfs的存储单元为数据块。
一个hdfs由1个Namenode和多个datanode组成。
namenode:
datanode:存储检索数据块,向namenode更新数据列表。
- 0赞 · 0采集
-

- NEKOAIMO 2021-01-12
———————————————————
-
截图0赞 · 0采集
-

- weixin_慕少1427560 2020-11-24
hdfs总结
-
截图0赞 · 0采集
-
- weixin_慕少1427560 2020-11-24
hadoop核心
-
截图0赞 · 0采集
-
- weixin_慕少1427560 2020-11-24
什么是大数据
-
截图0赞 · 0采集
-

- 慕九州6348563 2020-09-02
问题回顾:
数据块的大小设置为多少比较合适?
一般设置为128MB,设置过小,访问时数据时效率不高,对NameNade的内存消耗严重。数据块设置过大,降低对并行的支持
会使数据重启的时间延长。
如果NameNode挂掉了怎么办?
配用高可用集群ha存在两个NameNode节点,一个处于active请求状态,另一个处于standby备份状态,两者数据时刻保持一致
- 0赞 · 1采集
-
- 慕九州6348563 2020-09-02
hadoop是什么?
1.开源的大数据框架
2.分布式计算的解决方案
3.hadoop=HDFS(分布式文件系统)+MapReduce(分布式计算)
hadoop的核心?
1.HDFS分布式文件系统:存储大数据技术的基础
2.MapReduce编程模型:分布式计算提供处理大数据应用的解决方
HDFS概念
1.数据块
抽象的单个文件作为单元存储单元,默认大小为64MB,一般设置为128M,备份X3
2.NameNode
管理文件系统的命名空间,存放文件元数据
维护文件系统的所有文件和目录,文件于数据块的映射
记录每个文件中各个块所在数据节点的信息
3.DataNode
存储并检索数据块
向NameNode发送并更新所存储的列表
HDFS的优缺点
1.优点
适合大文件,可以构建在廉价的机器上,并有一定的容错和恢复机制,支持流式数据访问,一次写入,多次读取最高效
2.缺点
不适合小文件存储,不适合并发写入,不支持随机修改和随机读等低延时的访问方式
问题1:如果NameNode挂掉了怎么办?
将SecondaryNameNode中数据拷贝到namenode存储数据的目录
- 0赞 · 0采集
-
- 慕九州6348563 2020-09-02
大数据的定义
大数据是一个概念和一门技术,以hadoop 为代表的大数据平台框架上进行各种数据分析的技术 包括以hadoop,spark为代表的基础大数据框架还包括实时处理数据,离线处理数据;数据分析,数据挖掘和用机器算法进行预测分析等技术
- 0赞 · 0采集
-

- 慕工程2104131 2020-07-25
MapReduce 原理
-
截图0赞 · 0采集
-
- 慕工程2104131 2020-07-25
HDFS 的读流程
-
截图0赞 · 0采集
-
- 慕工程2104131 2020-07-25
HDFS 的写流程
(1) 首先客户端向NameNode发起写数据请求,NameNode保存的各个DataNode状态,检索的DataNode1、2、3有空间可以存储
(2)客户端将分块儿数据写入DataNode,DataNode完成自动备份
(3)DataNode向NameNode汇报存储完成,NameNode通知客户端
-
截图0赞 · 1采集
-
- 慕工程2104131 2020-07-25
Hadoop优缺点:适合大量文件TB、PB级的文件存储有副本出策略,适合一次写入多次读取;
不适合小规模数据以及随机读取这种场景
-
截图0赞 · 0采集
-
- 慕工程2104131 2020-07-25
Hadoop 是大数据存储与计算的分布式解决方案,其中HDFS大叔模具存储而MapReduce是大数据计算的解决方案
NameNode 存储文件元数据、维护文件系统的所有文件和目录以及文件与数据块的映射。记录每个文件中各个块所在数据节点的信息。
-
截图0赞 · 0采集
-

- 喵了喵大神 2020-07-24
下载,更改权限
-
截图0赞 · 0采集
-
- 喵了喵大神 2020-07-24
实验步骤1 将本地文件上传到hdfs中
-
截图0赞 · 0采集
-
- 喵了喵大神 2020-07-24
常用的hdfs shell命令
-
截图0赞 · 0采集












