-

- 霜花似雪 2022-11-22
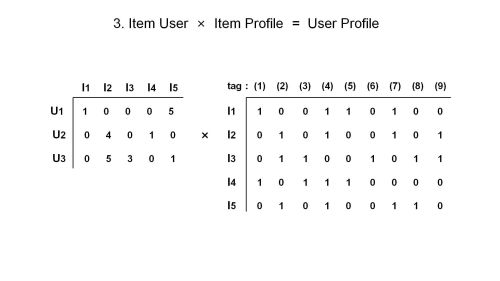
基于内容的推荐算法








- 0赞 · 0采集
-
- 霜花似雪 2022-11-21
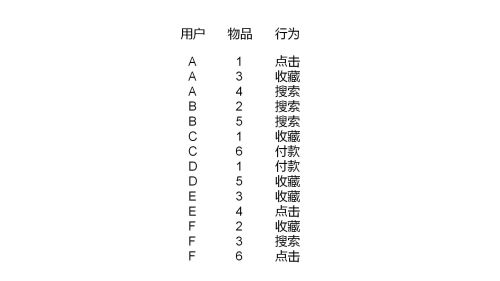
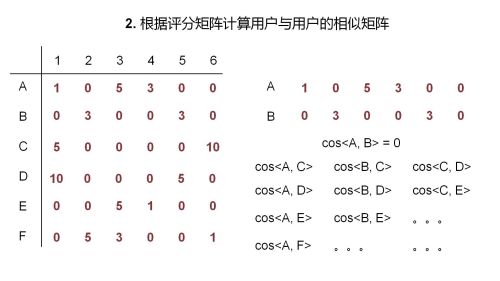
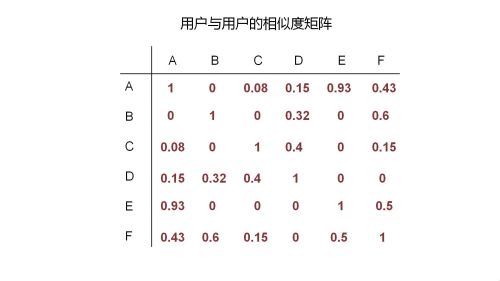
基于用户的推荐算法







- 0赞 · 0采集
-
- 霜花似雪 2022-11-21
物品推荐算法实现步骤

- 0赞 · 0采集
-
- 霜花似雪 2022-11-21
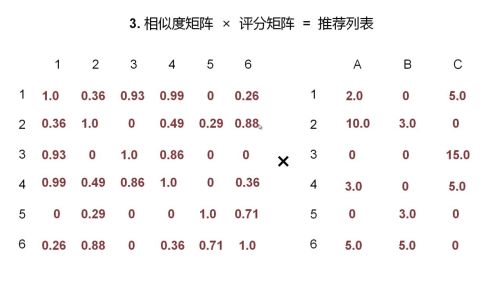
基于物品的协同过滤推荐算法
步骤:
1、根据用户行为列表计算用户、物品的评分矩阵
2、根据用户、物品的评分矩阵计算物品与物品的相似度矩阵
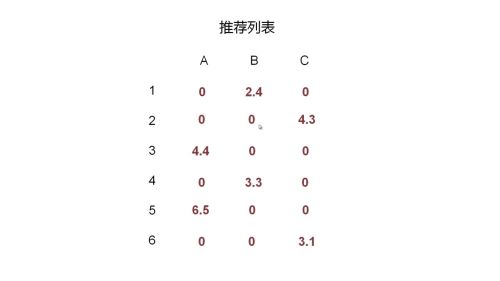
3、相似度矩阵 x 评分矩阵 = 推荐列表
4、将推荐列表与评分矩阵进行比较,在推荐列表中置零已经评过分的物品,剩下的数据就是要给客户推荐结果

- 0赞 · 0采集
-
- 霜花似雪 2022-11-21
物品推荐算法











- 0赞 · 0采集
-
- 霜花似雪 2022-11-21
二维向量的余弦相似度



- 0赞 · 0采集
-
- 霜花似雪 2022-11-20
矩阵乘法






- 0赞 · 0采集
-
- 霜花似雪 2022-11-20
分布式缓存


如何使用DistributedCache?





- 0赞 · 0采集
-
- 霜花似雪 2022-11-20
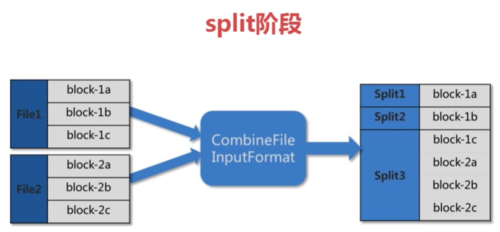
分片输入




- 0赞 · 0采集
-
- 霜花似雪 2022-11-20
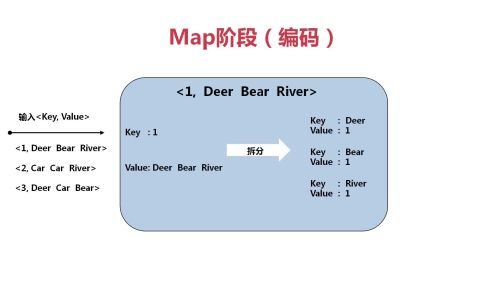
Map -> Reduce








- 0赞 · 0采集
-
- 霜花似雪 2022-11-20
从分片输入到Map







- 0赞 · 0采集
-
- 霜花似雪 2022-11-20
MapReduce






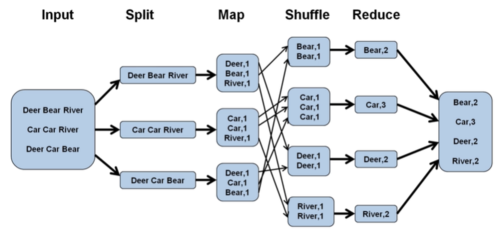
- 0赞 · 0采集
-
- 霜花似雪 2022-11-20


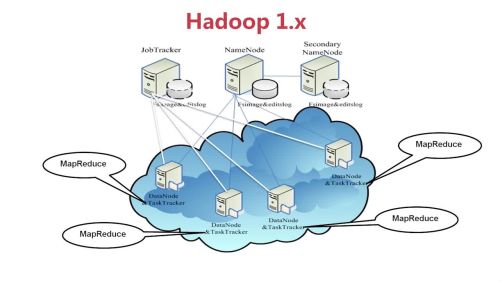
Hadoop2.0移除了原有的JobTracker和TaskTracker,改由Yarn平台的ResourceManager负责集群中所有资源的统一管理和分配,NodeManager管理Hadoop集群中单个计算节点

- 0赞 · 0采集
-

- 慕数据4084466 2021-10-04
 过程
过程- 0赞 · 0采集
-

- 钢管舞学员 2021-08-29
- 1.先在setup初始化方法中,把第二个数组加入到缓存中
-
截图0赞 · 0采集
-
- 钢管舞学员 2021-08-29
输出的文件内容

- 0赞 · 0采集
-
- 钢管舞学员 2021-08-29
MapReduce作业要有3个类
Mapper类 Mapper的泛型有4种类型的参数Mapper<mapper输入的key即行号LongWritetable,mapper输入的value类型即一行文本Text,mapper输出的key类型Text,mapper输出的value类型Text>
1)首先创建2个私有的输出变量
2)重写map方法()
在这个方法中我们需要做什么呢(行->列,列->行)?
理解元数据的表示含义,并且将元数据分解成我们所需要的中间数据。
Reduce类(继承Reduce方法)
Reduce<Text,Text,Text,Text> 有4个参数,
1.Reduce输入key的类型(与mapper输出的key的类型一致,Text)
2.Reduce输入value的类型(与mapper输出的value的类型一致,Text)
3.Reduce输出key的类型(Text类型)
4.Reduce输出value的类型(Text类型)
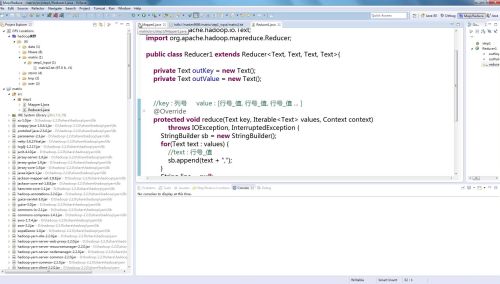
创建流程
1.创建2个私有的输出变量
2.创建reduce流程
主方法类(MR1)
创建流程
1.定义1个文件输入路径的私有变量,
2.定义一个文件的输出路径私有变量
3.定义HDFS的地址
4.定义一个run方法(
创建一个job配置类(返回类型是整型),作业的配置
设置hdfs的地址
创建一个job实例,就是我们要执行的作业(a.设置一个主类,b.设置mapper类,设置Reduce类)
设置mapper的输出类型
设置输出Reduce的类型
设置输入和输出路径(FileSystem类),并将输出的路径设置到job中
最后,返回作业运行的状态,如果作业运行成功,返回1,如果运行失败返回-1
)

5.运行一个主方法,来运行这个作业
定义一个变量,来表示作业运行的结果。如果返回是1,打印运行成功,如果是-1,运行失败
- 0赞 · 0采集
-
- 钢管舞学员 2021-08-29
MapReduce作业要有3个类
Mapper类 Mapper的泛型有4种类型的参数Mapper<mapper输入的key即行号LongWritetable,mapper输入的value类型即一行文本Text,mapper输出的key类型Text,mapper输出的value类型Text>
1)首先创建2个私有的输出变量
2)重写map方法()
在这个方法中我们需要做什么呢(行->列,列->行)?
理解元数据的表示含义,并且将元数据分解成我们所需要的中间数据。
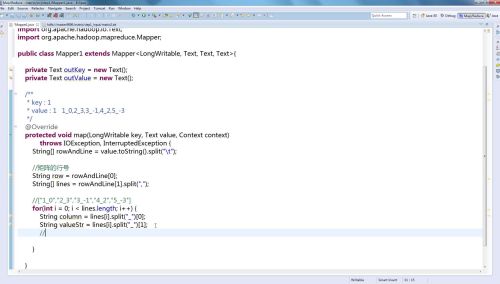
2.Reduce类(继承Reduce方法)
Reduce<Text,Text,Text,Text> 有4个参数,
1.Reduce输入key的类型(与mapper输出的key的类型一致,Text)
2.Reduce输入value的类型(与mapper输出的value的类型一致,Text)
3.Reduce输出key的类型(Text类型)
4.Reduce输出value的类型(Text类型)
创建流程
1.创建2个私有的输出变量
2.创建reduce流程

3.主方法类
- 0赞 · 0采集
-
- 钢管舞学员 2021-08-29
MapReduce作业要有3个类
Mapper类 Mapper的泛型有4种类型的参数Mapper<mapper输入的key即行号LongWritetable,mapper输入的value类型即一行文本Text,mapper输出的key类型Text,mapper输出的value类型Text>
1)首先创建2个私有的输出变量
2)重写map方法()
在这个方法中我们需要做什么呢(行->列,列->行)?
理解元数据的表示含义,并且将元数据分解成我们所需要的中间数据。

Reduce类
主方法类
- 0赞 · 0采集
-
- 钢管舞学员 2021-08-29
矩阵处理2----------矩阵相乘

- 0赞 · 0采集
-
- 钢管舞学员 2021-08-29
矩阵处理1----------将第2个矩阵行转换成列,列转换成行
---------转换成功后的结果(
没转换前:左矩阵的行向量*右矩阵的列向量
转换后:左矩阵的行向量*右矩阵的行向量
)

- 0赞 · 0采集
-
- 钢管舞学员 2021-08-29
矩阵处理1----------将第2个矩阵行转换成列,列转换成行

- 0赞 · 0采集
-
- 钢管舞学员 2021-08-29
矩阵处理1
要计算2个矩阵相乘,那么需要2个连续的MapReduce的操作相乘

- 0赞 · 0采集
-
- 钢管舞学员 2021-08-29
矩阵的表示方法
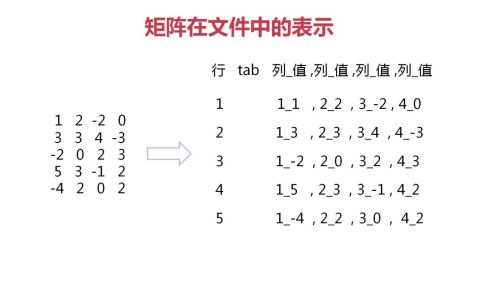
- 0赞 · 0采集
-
- 钢管舞学员 2021-08-29
矩阵相乘的例子

- 0赞 · 0采集
-
- 钢管舞学员 2021-08-29
总结

- 0赞 · 0采集
-
- 钢管舞学员 2021-08-29
如何使用分布式缓存-----第二步

- 0赞 · 0采集
-
- 钢管舞学员 2021-08-29
如何使用分布式缓存-----第二步

- 0赞 · 0采集
-
- 钢管舞学员 2021-08-29
如何使用分布式缓存-----第一步

- 0赞 · 0采集
-
- 钢管舞学员 2021-08-29
如何使用分布式缓存-----第一步

- 0赞 · 0采集


 过程
过程
















