-

- zrey 2022-03-30
Hbase shell
Create '表名','表名' Describe '表名' is_enabled //查看表是否可用 Drop '表名' Enable Disable '表名' //先禁用,才能删除表 is_disabled List scan '表名' put '表名','rowkey','列簇:列名','value'
- 0赞 · 0采集
-
- zrey 2022-03-29
Hbase/conf/hbase-env.sh
export JAVA_HOME=/jdk export HBASE_MANAGES_ZK =false //禁用自带的zookeeper
hbase-site.xml
<!-- hadoop集群名称 --> <property> <name>hbase.rootdir</name> <value>hdfs://mycluster/hbase</value> </property> <!—是否依赖zookeeper—> <property> <name>hbase.zookeeper.quorum</name> <value>hmaster1,hmater2,hslave1</value> </property> <property> <name>hbase.zookeeper.property.clientPort</name> <value>2181</value> </property> <!-- 是否是完全分布式 --> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!-- 完全分布式式必须为false --> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> </property> <!-- 指定缓存文件存储的路径 --> <property> <name>hbase.tmp.dir</name> <value>/home/hadoop/data01/hbase/hbase_tmp</value> </property> <!-- 指定Zookeeper数据存储的路径 --> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/home/hadoop/data01/hbase/zookeeper_data</value> </property>
regionservers:
添加DataNode的IP或者机器名即可,这个文件把RegionServer的节点列了下来
- 0赞 · 0采集
-
- zrey 2022-03-29
1. zookeeper/conf/zoo_sample.cfg
->zoo.cfg
2. 数据存放目录 zoo.cfg中dataDir -> 创建data/zkdata
3. zoo.cfg中server.1 = hostname:2888:3888
4. 数据节点根目录(zkdata)创建myid文件
zoo.cfg文件
"server.1=hmaster1:2888:3888"这一句中的server.1表示节点编号,"hmaster1"表示这台服务器的主机名,也可以直接指定ip地址,"2888"是ZooKeeper服务间通信的端口,"3888"是ZooKeeper服务与其他服务通信的端口
dataDir指定ZooKeeper的数据目录
autopurge.purgeInterval=1 表示开启日志和镜像文件自动清理功能
- 0赞 · 0采集
-
- zrey 2022-03-29
!Hbase不支持条件查询!

- 0赞 · 0采集
-
- zrey 2022-03-29

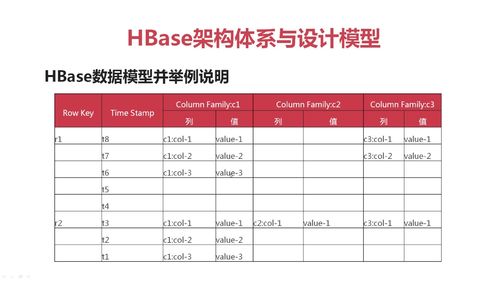
rowkey行键:
1)它是表(table)的主键,table中的记录按照rowkey的字典序进行排序
Column Family列族:
1)HBase表中的每个列,都归属于某个列族。
2)列族是表的schema的一部分(而列不是),即建表时至少指定一个列族。
3)比如我们创建user表,包含info、data两个列族,代码就为create 'user', 'info', 'data'。
Column列:
列肯定是表的某一个列族下的一个列,用列族名:列名表示,比如`info`列族下的`name`列,就表示为`info:name`。
Timestamp时间戳:
这个说的就是可以对表中的Cell多次赋值,每次赋值操作时的时间戳timestamp,可看成Cell值的版本号version number。
- 0赞 · 0采集
-
- zrey 2022-03-29
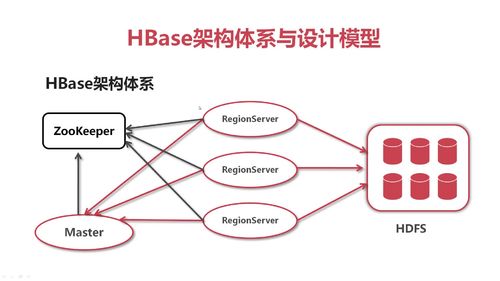
Zookeeper:
① 它实现了HMaster的高可用,多HMaster间进行主备选举。② 保存了HBase的元数据信息meta表。③ 对HMaster和HRegionServer各个节点进行监控。
HRegionServer:
HBase集群中从角色,是集群中的小弟。它主要负责响应客户端的读写数据请求,以及负责管理一系列的Region。
Region:
HBase集群中分布式存储的最小单元,一个Region对应一个Table表的部分数据。简单理解就是表存储在HBase中,并且都是以Region为单位进行存储。
- 0赞 · 0采集
-
- zrey 2022-03-29
容量大:百万列行
面向列:列式存储,面向列权限控制,独立检索。实时动态增加列
多版本:每一列数据存储有多个版本
稀疏性:空的列不占用存储空间,表可以设计的很稀疏
扩展性:底层依赖HDFS。动态增加datanode,不需要迁移
高可靠性:WAL机制保证数据写入不会因为集群异常导致丢失。HDFS本身也有备份
高性能:底层LSM数据结构和Rowkey有序排列架构设计。写入性能高。以树节点相互合并由下往上。region切分,索引和缓存机制使hbase具备随机读取性能
- 0赞 · 0采集
-

- 慕仰3261801 2021-03-06
总结:

- 0赞 · 0采集
-
- 慕仰3261801 2021-03-05
HBase监控WEB页面介绍
hbase-daemon.sh
start-hbase.sh
hbase-daemons.sh
stop-hbase.sh
HBase shell
- 0赞 · 0采集
-
- 慕仰3261801 2021-03-05
配置目录在cf中
- 0赞 · 0采集
-
- 慕仰3261801 2021-03-05
HBase安装说明:
JDK1.7以上
Hadoop-2.5.0以上
Zookeeper-3.4.5
- 0赞 · 0采集
-
- 慕仰3261801 2021-03-05
一个列簇有多个列
一张表列簇不会超过5个
每个列簇中的列数没有限制
列只有插入数据后存在
列在列簇中是有序的
HBase列是动态增加,数据自动切分,高并发读写,不支持条件查询
关系数据库列动态增加吧,数据自动切分,高并发读写,复杂查询
- 0赞 · 0采集
-

- liangshanguang 2021-02-22
- Hbase表模型
-
截图0赞 · 0采集
-
- liangshanguang 2021-02-22
- Hbase架构
-
截图0赞 · 0采集
-
- liangshanguang 2021-02-20
Hbase的特点
-
截图0赞 · 0采集
-
- liangshanguang 2021-02-20
HBase的高性能
-
截图0赞 · 0采集
-

- qq_慕虎1582767 2020-08-25
配置hdfs-site.xml
配置单节点方式 dfs.replication:1
不检查权限 dfs.permissions.enabled:false
-
截图0赞 · 0采集
-
- qq_慕虎1582767 2020-08-25
Hadoop配置
hadoop-env.sh
配置java环境变量
core-site.xml
配置hdfs访问地址,创建hadoop的namenode存放目录,
不配置又默认目录
-
截图0赞 · 1采集
-
- qq_慕虎1582767 2020-08-24
安装需求
JDK1.7以上
Hadoop-2.5.0以上
Zookepper-3.4.5
- 0赞 · 0采集
-
- qq_慕虎1582767 2020-08-24
与关系型数据库对比
区别于关系型数据库,hbase列是动态增加的,关系型数据库是需要提前定好列
数据会自动切分,关系型数据库需要人工干预
自带高并发读写,关系型数据库需要引入缓存一类的插件实现
缺点:不支持条件查询,不能进行复杂查询
-
截图0赞 · 0采集
-
- qq_慕虎1582767 2020-08-24
regionserver管理的region说明
region是regionserver管理区域的划分
regionserver会对region自动切分,也可以通过人工干预方式划分
-
截图0赞 · 0采集
-
- qq_慕虎1582767 2020-08-24
列簇的概念
一张表的类簇尽可能不超过5个,否则容易导致性能下降
每个列簇的列数没有限制
列只有插入数据后才存在,是动态增加的
列在列簇中是有序的
-
截图0赞 · 0采集
-
- qq_慕虎1582767 2020-08-24
列簇举例说明:
基于列,每条数据有一个rowkey,一个timestamp,多个列簇,列簇包括多行数据,具体参照下图
-
截图0赞 · 0采集
-
- qq_慕虎1582767 2020-08-24
列簇举例说明
根据不同的一组列创建列簇
-
截图0赞 · 0采集
-
- qq_慕虎1582767 2020-08-24
列簇概念
hbase是面向列的数据库,建表时不需要创建列,只需要创建列簇
列簇就是根据一组类型的列创建列簇
-
截图0赞 · 0采集
-
- qq_慕虎1582767 2020-08-24
zookeeper调度->hbase存储->hdfs
hbase有两个服务 Master和RegionServer
- 0赞 · 0采集
-
- qq_慕虎1582767 2020-08-24
中文官方文档:http://abloz.com/hbase/book.html
版本选择
官方版:
http://archive.apache.org/dist/hbase
CDH版:
http://archive.cloudera.com/cdh5/
后者是cloudera整合之后的版本,相对比较稳定
- 0赞 · 0采集
-

- 慕工程2104131 2020-07-25
Hbase 的高扩展性,底层依赖HDFS当存储空间不足时可以动态增加DataNode节点。
高可用 底层依赖HDFS 自动备份
高性能 写入性能:底层LSM数据结构和RowKey有序排列在架构上的独特设计。
region切分、主键索引和缓存机制使得Hbase在海量数据下具备一定随机读取性能,该性能针对TRowKey的查询能达到毫秒级别
-
截图0赞 · 0采集
-
- 慕工程2104131 2020-07-25
Hbase 是面向列的存储,支持独立检索。列式存储其数据在表中是按照列存储的可以动态增加列
-
截图0赞 · 0采集
-
- 慕工程2104131 2020-07-25
Hbase数据库的应用场景: 交通、金融、电商、移动等
Hbase分布式文件存储系统 行在亿级以上
-
截图0赞 · 0采集




