-

- 慕标8771067 2023-07-26
- https协议是带小🔒标记的是安全的
http没有 - 0赞 · 0采集
-

- 2020064680 2023-05-08
Xpathl路径表达式
Xpath使用路径表达式来选取XML文档(或是HTML文档)中的节点或节点集
路径表达式:
/div:从根节点开始选取div节点
//a:选取文档中所有的a节点而不考虑其位置
@class:选取名为class的属性
. :选取当前节点
.. :选取当前节点的父节点
ctrl+shift+x 打开Xpath
/div/a :从根节点开始选取div节点下的a节点
/div/a[@class='header-wrapper' ]
- 0赞 · 0采集
-

- 精慕门8204034 2023-03-15
请求头
- 0赞 · 0采集
-

- 宝慕林9239103 2022-04-10
etree用来添加HTML和body标签
data = """ <div> <ul> <li class="item-0"><a href="link1">first</a></li> <li class="item-in"><a href="link2"><span class="bold">second</span></a></li> <li class="item-0"><a href="link3">third</a></li> </ul> </div> """ html = etree.HTML(data)

2.获取第一个li的a标签
1.print(html.xpath("//li/a[@href='link1']")) 2.print(html.xpath("//li[1]/a[1])3.获取第二个li的span标签
1.#因为span是li的后代元素,所以要用两个// 2.print(html.xpath("//li//span"))4.获取最后一个li里面的href(last的使用)
print(html.xpath("//li[last()]/a/@href"))- 0赞 · 0采集
-
- 宝慕林9239103 2022-04-09
设置代理——隐藏请求
- 0赞 · 0采集
-
- 宝慕林9239103 2022-04-09
第二遍没太听懂
- 0赞 · 0采集
-

- Snow_pear__Apple 2021-11-25
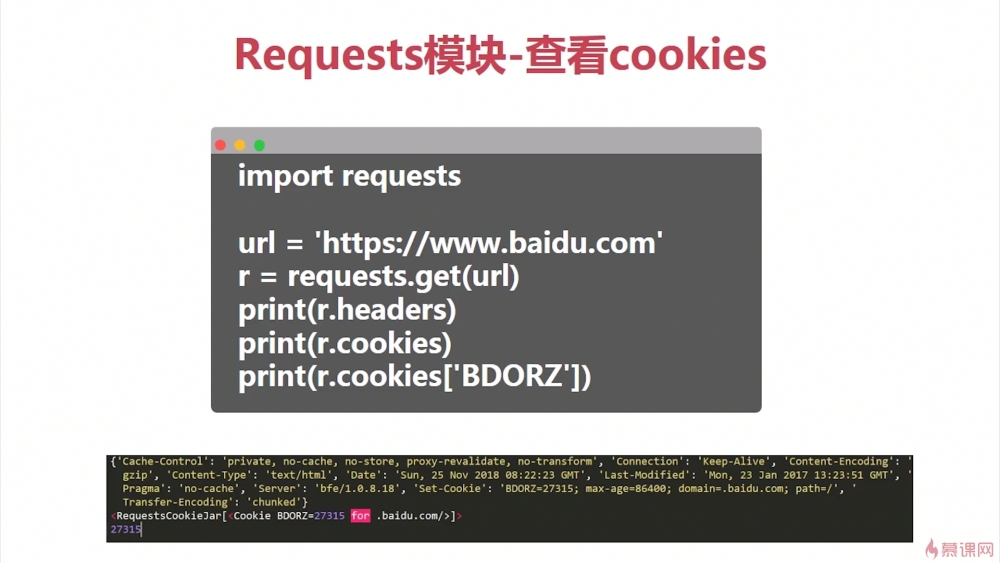 百度的返回头如何设置 cookies
百度的返回头如何设置 cookies- 0赞 · 0采集
-
- Snow_pear__Apple 2021-11-25
百度的返回头如何设置 cookies
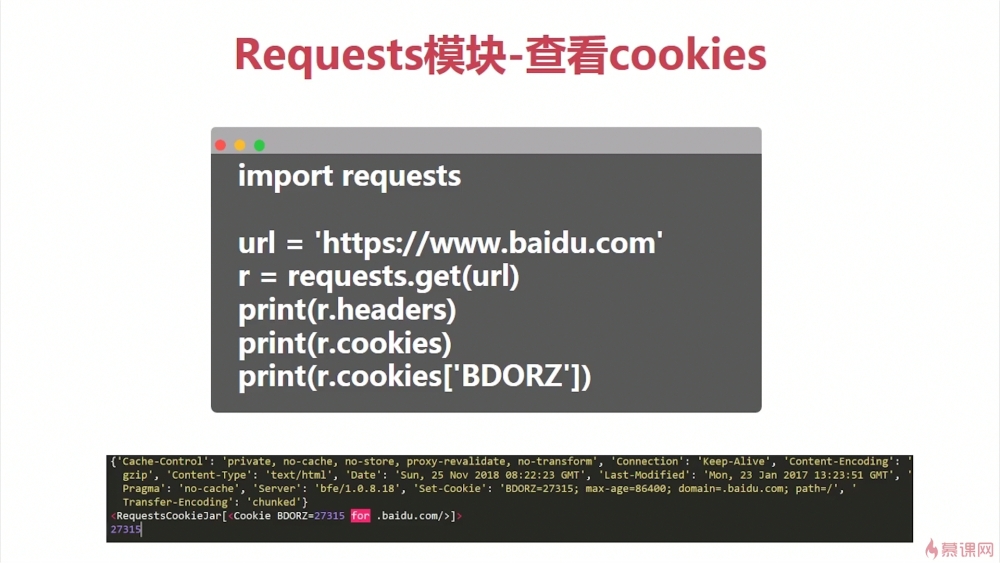
- 0赞 · 0采集
-

- Yuumi 2021-10-25

- 0赞 · 0采集
-
- Yuumi 2021-10-25

- 0赞 · 0采集
-
- Yuumi 2021-10-25
关闭校验:verify=False
指定证书:verify='xxx'(某个路径)
- 0赞 · 0采集
-

- cloverwang 2021-10-19
session信息

- 0赞 · 0采集
-
- cloverwang 2021-10-19

Requests模块构造URL

- 0赞 · 0采集
-
- cloverwang 2021-10-19

PUT方法
- 0赞 · 0采集
-
- cloverwang 2021-10-19
HTTP POST方法用于提交数据(如表单)

- 0赞 · 0采集
-
- cloverwang 2021-10-19

Head方法请求部分信息
- 0赞 · 0采集
-
- cloverwang 2021-10-19
HTTP方法GET

- 0赞 · 0采集
-
- cloverwang 2021-10-19

request是一个Python三方库
- 0赞 · 0采集
-

- Nevada0 2021-07-11
import pymongo # 指定客户端连接mongodb pymongo_client = pymongo.MongoClient("mongodb://localhost:27017") # 指定数据库名称 pymongo_db = pymongo_client["imooc"] # 创建集合,创建表 pymongo_collection = pymongo_db["pymongo_test"] data = { "name": "imooc", "flag": 1, "url": "https://www.imooc.com" } mylist = [ {"name": "imooc", "flag": "123", "url": "https://www.imooc.com"}, {"name": "taobao", "flag": "456", "url": "https://www.imooc.com"}, {"name": "qq", "flag": "761", "url": "https://www.imooc.com"}, {"name": "知乎", "flag": "354", "url": "https://www.imooc.com"}, {"name": "微博", "flag": "954", "url": "https://www.imooc.com"} ] # pymongo_collection.insert_one(data) # pymongo_collection.insert_many(mylist) # result=pymongo_collection.find({},{"_id":0,"name":1,"url":1,"flag":1}) # result=pymongo_collection.find({},{"_id":0,"name":1,"url":1,"flag":1}) # result=pymongo_collection.find_one() # print(result) # for item in result: # print(item) # 大于一百 # find_result=pymongo_collection.find({"flag":{"$gt":100}}) # 首字母t # find_result=pymongo_collection.find({"name":{"$regex":"^t"}}) # for item in find_result: # print(item) # pymongo_collection.update_one({"name":{"$regex":"^t"}},{"$set":{"name":"baidu"}}) # pymongo_collection.delete_one({"name":"微博"}) pymongo_collection.delete_many({})- 0赞 · 0采集
-
- Nevada0 2021-07-11
import requests from lxml import etree from pymongo.collection import Collection import pymongo print("开始0") class Dangdang(object): mongo_client=pymongo.MongoClient(host="localhost",port=27017) dangdang_db=mongo_client["dangdang_db"] def __init__(self): self.header = { "Host": "bang.dangdang.com", "Connection": "keep-alive", "Cache-Control": "max-age=0", "Upgrade-Insecure-Requests": "1", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9", "Referer": "http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-2", "Accept-Encoding": "gzip,deflate", "Accept-Language": "zh-CN,zh;q=0.9" } self.dangdang=Collection(Dangdang.dangdang_db,"dangdang") def get_dangdang(self, page): """发送请求到当当网获取数据""" url = "http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-%s" % page response = requests.get(url=url, headers=self.header) if response: # html数据实例化 # print(response.text) html1 = etree.HTML(response.content) items = html1.xpath("//ul[@class='bang_list clearfix bang_list_mode']/li") return items def join_list(self,item): # 处理列表→字符串 return "".join(item) def parse_item(self,items): # 解析条目 # 存到mongodb之前的数据 result_list=[] for item in items: # 名称 title=item.xpath(".//div[@class='name']/a/@title") # 图书评论 comment=item.xpath(".//div[@class='star']/a/text()") # 作者信息 author=item.xpath(".//div[@class='publisher_info'][1]/a[1]/@title") # 价格 price=item.xpath(".//div[@class='price']/p[1]/span[1]/text()") result_list.append( { "title":self.join_list(title), "comment":self.join_list(comment), "author":self.join_list(author), "price":self.join_list(price) } ) return result_list def insert_data(self,result_list): self.dangdang.insert_many(result_list) def main(): d = Dangdang() print("开始") import json for page in range(1, 26): items = d.get_dangdang(page=page) result=d.parse_item(items=items) # print(json.dumps(result)) print(result) # d.insert_data(result) if __name__ == '__main__': main()- 0赞 · 0采集
-
- Nevada0 2021-07-10
 注意单引号双引号的问题
注意单引号双引号的问题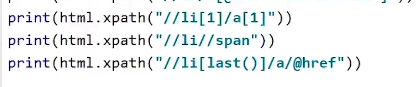 孙子标签用//
孙子标签用//获取最后一个li标签的a标签的href的值
- 0赞 · 0采集
-
- Nevada0 2021-07-10
xpath
//div[@class="result c-container new-pmd"]
//dd[@class="lemmaWgt-lemmaTitle-title J-lemma-title"]/a[3]/text()
//div[not(contains(@class,"para"))]
//div[last()-2]
- 0赞 · 0采集
-

- 慕码人433340 2021-06-22
- Chrome商店 XPath Helper
-
截图0赞 · 0采集
-

- 王得得 2021-03-21
遇到网络问题: ConnectionError异常
如果HTTP请求返回了不成功的状态码: HTTPError异常
若请求超时,则抛出一个Timeout异常
若请求超过了设定的最大重定向次数,则会抛出一个 TooManyRedirects异常
- 0赞 · 0采集
-
- 王得得 2021-03-21
关闭SSL校验:
response = requests.get(url="https://www.baina.org/", verify=false)
print(response.text)
- 0赞 · 0采集
-

- 慕九州1349144 2021-02-07
cookie
- 0赞 · 1采集
-

- 258069 2020-12-02
# 随便练习 print(1)
- 0赞 · 0采集




















