-

- qq_羽悦_03291187 2025-03-17
任务调度除了使用linux的crontale,还可以使用Azkabanhuoz Ooize工具

- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-17
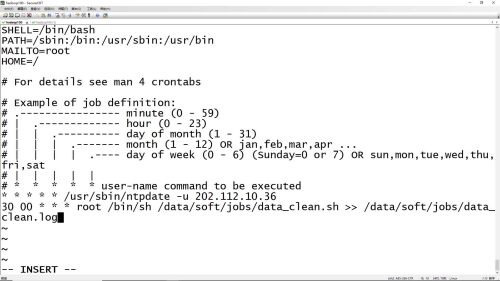
加入/etc/crontab定时任务命令
- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-17
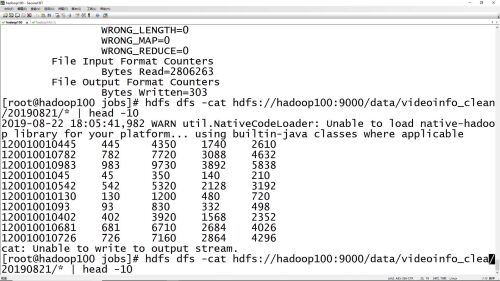
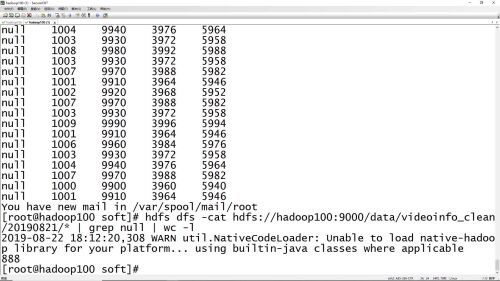
hdfs查看清洗之后的数据命令
- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-17
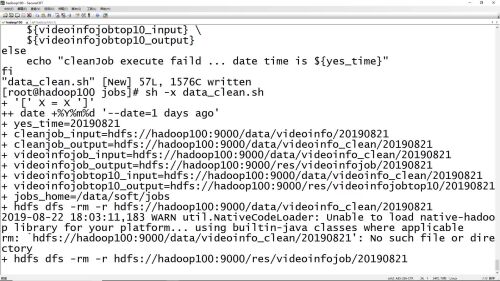
数据清洗脚本执行
- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-17
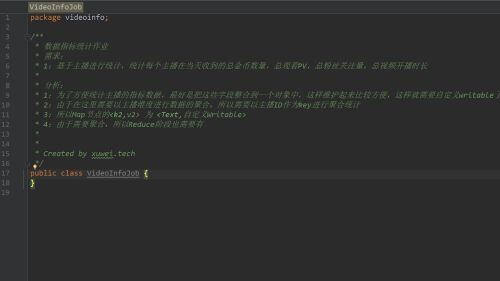
数据指标统计作业
- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-17
业务描述

- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-17
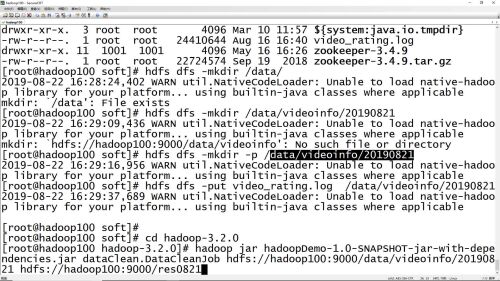
项目启动命令
- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-17
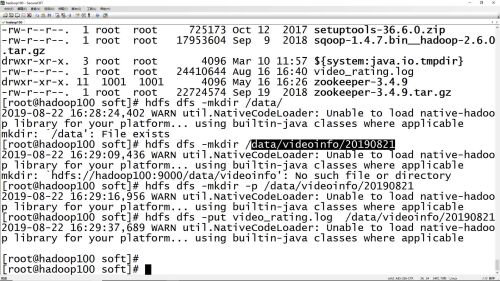
目录创建与文件上传命令
- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-17
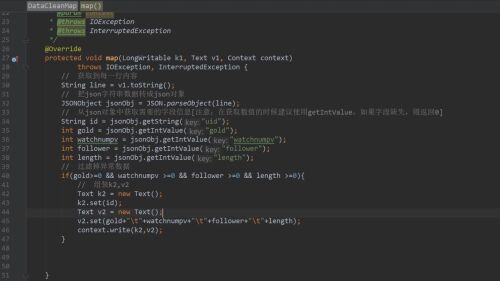
数据清洗作业代码实现
- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-17
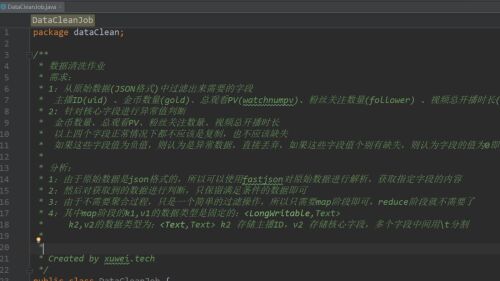
数据清洗作业
- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-17
原始数据清洗原因

- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-17
Yarn资源管理器详解


- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-17
Java序列化的不足

- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-17
Hadoop序列化机制的特点

- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-17
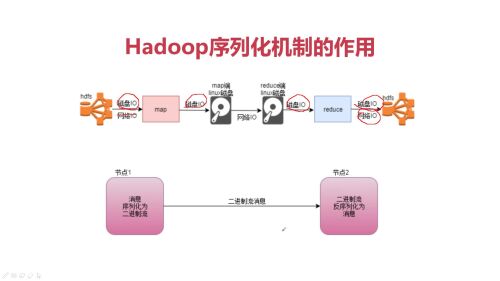
Hadoop序列化机制的作用
- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-17
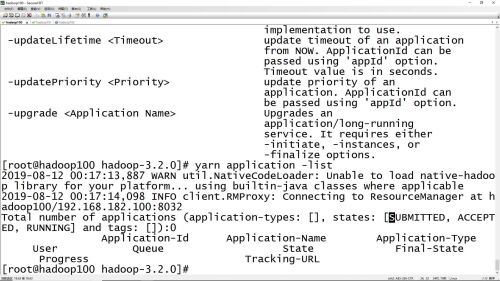
#yarn application -list查看正在执行中的任务

- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-17
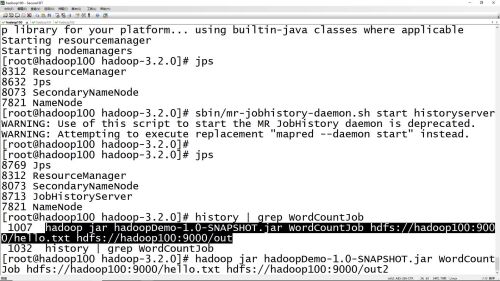
聚合日志命令,每个节点上都启动聚合日志服务
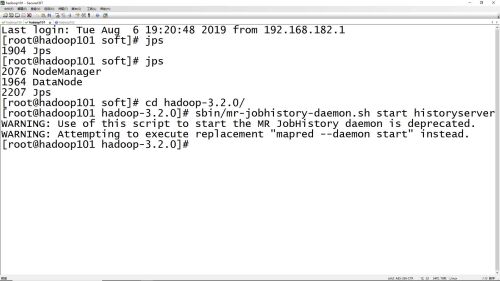
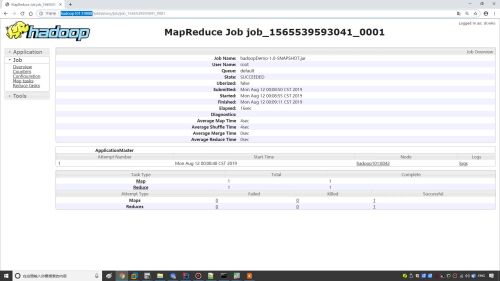
- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-17
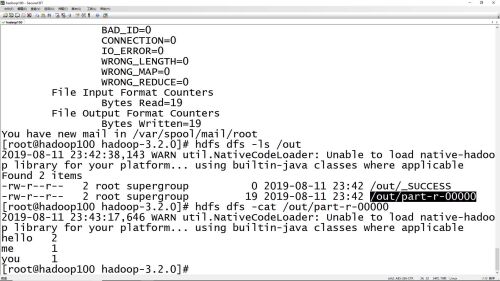
hadoop jar项目部署命令
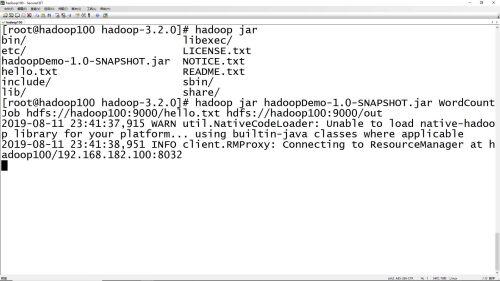
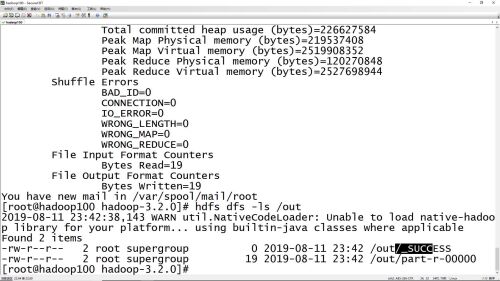
- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-17
MapReduce概述

- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-17
NameNode总结

- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-17
DataNode介绍

- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-17
SecondaryNameNode介绍

- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-17
NameNode介绍

- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-17
HDFS体系结构详解

- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-17
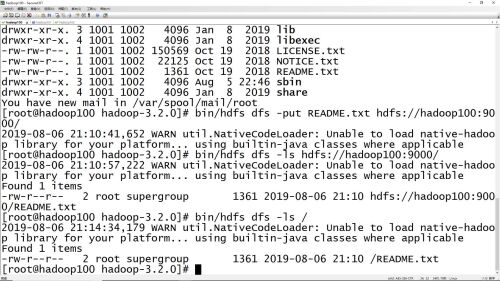
HDFS中put、ls命令的使用
- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-17
HDFS的Shell操作命令

- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-17
HDFS的shell介绍

- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-17
HDFS分布式的多台文件管理系统

- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-12
hadoop客户端节点安装
- 0赞 · 0采集
-
- qq_羽悦_03291187 2025-03-12
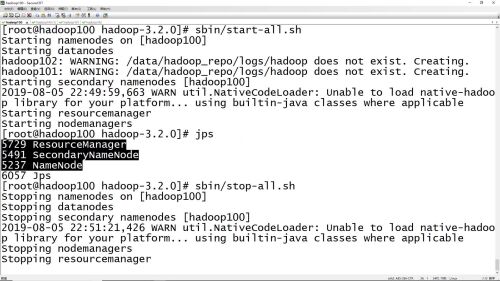
hadoop分布式集群 start-all.sh、stop-all.sh启动和停止命令
- 0赞 · 0采集

数据加载中...
开始学习
免费