-

- qq_羽悦_03291187 2023-07-17
DataSchema简介

- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-07-17
Druid数据摄取配置

- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-07-16
Druid Segment聚合

- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-07-16
Druid数据划分

- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-07-16
Druid整体架构图

- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-07-16
Apache Druid基本特点

- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-07-16
Apache Druid使用场景

- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-07-16
Apache Druid简介

- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-07-15
OLAP(联机事物分析处理
 )系统与OLTP(联机事物处理)系统的概念,Druid类似于OLAP系统
)系统与OLTP(联机事物处理)系统的概念,Druid类似于OLAP系统- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-07-15
Apache Druid是一个高性能的实时分析型数据库
- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-07-11
解压gz数据

- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-07-11
kafka配置druid

- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-07-11
消息发布和消息消费

- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-07-11
server.properties配置文件说明:
broker.id=0 #kafka实例节点唯一标识
num.network.threads=3 #broker处理消息的最大线程数,一般是cpu的核数
num.io.threads=8 #broker处理磁盘io的线程数
socket.send.buffer.bytes=102400 #socket的一个发送缓冲区大小
socket.receive.buffer.bytes=102400 #socket的一个接入缓冲区大小
socket.request.max.bytes=104857600 #socket请求的最大数值
log.dirs=/tem/kafka-logs #log文件地址
num.partitions=1 #指定一个新创建的topic会包含的那些分区的一个默认值
num.recovery.threads.per.data.dir=1 #配置kafka用于自身恢复的一些机制,默认情况下,每个文件夹下就是1个线程
#log.flush.interval.messages=1000 #当消息有1000条时就刷新到磁盘上
#log.flush.interval.ms=1000 #每1000秒时就把消息刷新到磁盘
log.retention.hours=168 #过期时间,日志数据保存的一个最大时间,默认是7天
#log.retention.bytes=1073741824 #日志保存的最大字节数
log.retention.check.interval.ms=300000 #日志片段检查周期
- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-07-11
kafka存放在磁盘上,可以配置多个目录

- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-07-11
socket发送缓冲区、socket接入缓冲区;socket请求最大数值,防止OOM溢出

- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-07-11
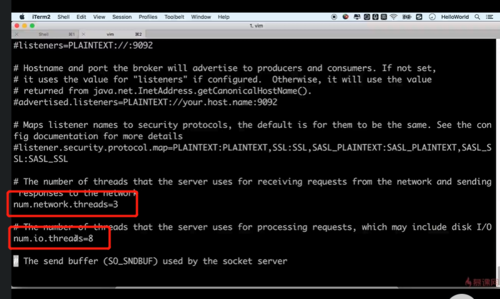
broka处理消息的最大进程数和处理IO的最大进程数
- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-07-11
kafka安装依赖Scala
- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-07-10
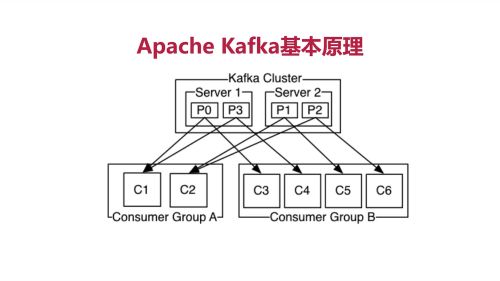
Kafka基本原理2,消费群组
- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-07-10
Kafka基本原理,局部有序的消息队列

- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-07-10
生产者向Kafka发送数据,消费者读取Kafka的数据

- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-07-10
Kafka概念:Broke、Topic和Partiton;分区主要是负载均衡,然后提高并发度,分区把消息分散到不同的节点上去

- 0赞 · 0采集
-
- qq_羽悦_03291187 2023-07-10
kafka简介,高吞吐和低延迟指kafka每秒钟处理几十万条消息,但他的延迟也只是几毫秒;高容错是当集群中有节点异常下线的时候kafka依然能保持高吞吐、低延迟的特性

- 0赞 · 0采集
-

- weixin_慕慕5561349 2021-03-03
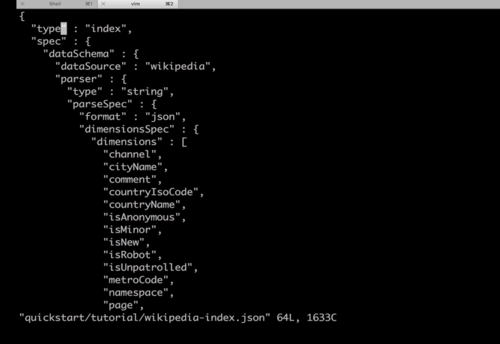
111

- 0赞 · 0采集
-
- weixin_慕慕5561349 2021-03-03
post数据
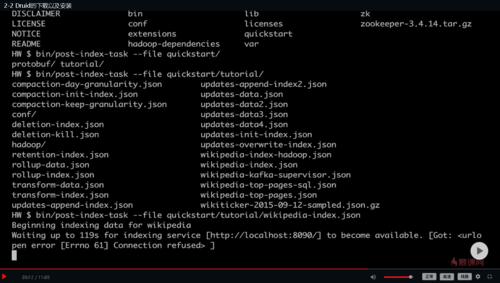
- 0赞 · 0采集
-

- 淡忘这一切 2021-03-03
粒度rollup为false,指标列必须为空
dataSource:表示数据源
parser:数据解析方式
metricspec:指标列信息
granularitypec:存储和查询粒度
transformSpce:过滤转换输入数据
-
截图0赞 · 0采集
-
- 淡忘这一切 2021-03-03
OLAP技术方案对比
-
截图0赞 · 0采集
-

- weibo_最爱囧囧有神_0 2020-07-31
- Druid 架构图
-
截图0赞 · 0采集
-
- weibo_最爱囧囧有神_0 2020-07-31
- ,,,
-
截图0赞 · 0采集
-

- 慕仙1599145 2020-07-06
- Druid
-
截图0赞 · 0采集




