Go语言-for语句
for语句代表着循环。一条语句通常由关键字for、初始化子句、条件表达式、后置子句和以花括号包裹的代码块组成。其中,初始化子句、条件表达式和后置子句之间需用分号分隔。示例如下:
for i := 0; i < 10; i++ {
fmt.Print(i, " ")
}
我们可以省略掉初始化子句、条件表达式、后置子句中的任何一个或多个,不过起到分隔作用的分号一般需要被保留下来,除非在仅有条件表达式或三者全被省略时分号才可以被一同省略。
我们可以把上述的初始化子句、条件表达式、后置子句合称为for子句。实际上,for语句还有另外一种编写方式,那就是用range子句替换掉for子句。range子句包含一个或两个迭代变量(用于与迭代出的值绑定)、特殊标记:=或=、关键字range以及range表达式。其中,range表达式的结果值的类型应该是能够被迭代的,包括:字符串类型、数组类型、数组的指针类型、切片类型、字典类型和通道类型。例如:
for i, v := range "Go语言" {
fmt.Printf("%d: %c\n", i, v)
}
对于字符串类型的被迭代值来说,for语句每次会迭代出两个值。第一个值代表第二个值在字符串中的索引,而第二个值则代表该字符串中的某一个字符。迭代是以索引递增的顺序进行的。例如,上面的for语句被执行后会在标准输出上打印出:
0: G 1: o 2: 语 5: 言
可以看到,这里迭代出的索引值并不是连续的。下面我们简单剖析一下此表象的本质。我们知道,字符串的底层是以字节数组的形式存储的。而在Go语言中,字符串到字节数组的转换是通过对其中的每个字符进行UTF-8编码来完成的。字符串"Go语言"中的每一个字符与相应的字节数组之间的对应关系如下:
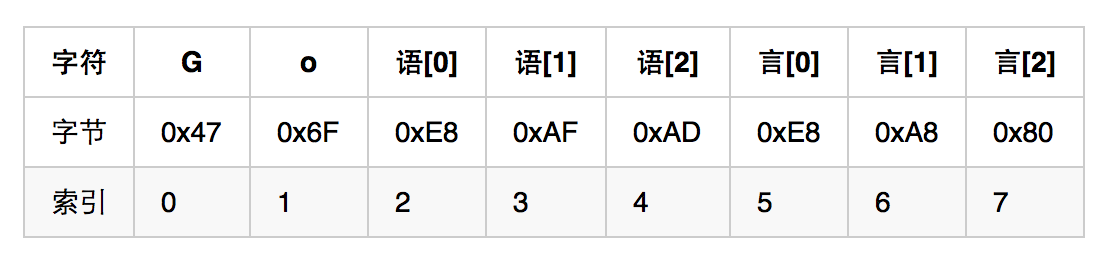
注意,一个中文字符在经过UTF-8编码之后会表现为三个字节。所以,我们用语[0]、语[1]和、语[2]分别表示字符'语'经编码后的第一、二、三个字节。对于字符'言',我们如法炮制。
对照这张表格,我们就能够解释上面那条for语句打印出的内容了,即:每次迭代出的第一个值所代表的是第二个字符值经编码后的第一个字节在该字符串经编码后的字节数组中的索引值。请大家真正理解这句话的含义。
对于数组值、数组的指针值和切片之来说,range子句每次也会迭代出两个值。其中,第一个值会是第二个值在被迭代值中的索引,而第二个值则是被迭代值中的某一个元素。同样的,迭代是以索引递增的顺序进行的。
对于字典值来说,range子句每次仍然会迭代出两个值。显然,第一个值是字典中的某一个键,而第二个值则是该键对应的那个值。注意,对字典值上的迭代,Go语言是不保证其顺序的。
携带range子句的for语句还可以应用于一个通道值之上。其作用是不断地从该通道值中接收数据,不过每次只会接收一个值。注意,如果通道值中没有数据,那么for语句的执行会处于阻塞状态。无论怎样,这样的循环会一直进行下去。直至该通道值被关闭,for语句的执行才会结束。
最后,我们来说一下break语句和continue语句。它们都可以被放置在for语句的代码块中。前者被执行时会使其所属的for语句的执行立即结束,而后者被执行时会使当次迭代被中止(当次迭代的后续语句会被忽略)而直接进入到下一次迭代。