
在上一篇的笔记之中,我们讨论了数据模型和查询语言。在第三章之中我们来聊一聊不同的数据引擎内部是如何实现存储和检索的,以及不同设计之间的折中与妥协。
1.键值对数据库
键值对数据库是数据库形式之中最简单的一种模式,我们可以把它简化的实现为下面两个函数:
底层存储格式也十分简单:一个文本文件,其中每行包含一个键值对,用逗号分隔(类似于CSV文件,忽略转义问题)。每一次调用 db_set 会追加键值对到文件的末尾,如果你更新的一个键值对的旧版本不会覆盖之前的键值对,但是 db_get会利用 tail -n 1 in 语句读取最新的键值对。但是真正的数据库需要处理更多的问题(例如并发控制、回收磁盘空间、使日志不能永久增长、处理错误和部分写的问题),但基本设计思路和原则是相同的。
但是,db_get 在性能上表现的很糟糕,每一次需要查找一个key,db_get 会扫描整个数据库文件来查找Key。在算法定义之中,查找的时间复杂度是O(n)。为了有效地查找数据库中某个特定键的值,我们需要一个不同的数据结构:索引。
2.索引
索引是从原始数据派生出来的附加结构。在添加和删除索引时,不会影响数据存储的内容,它只会影响查询的性能。但是维护额外的结构会导致开销,尤其是写操作。任何类型的索引都会减慢写速度,因为每次写入数据时也需要更新索引。
在存储系统的有一个重要的权衡:精心挑选的索引加快了读取的速度,但是每个索引都会减慢写入速度。由于这个原因,数据库通常不会默认索引所有内容,但要求应用程序开发人员或数据库管理员手动地选择索引,可以选择使应用程序受益最大的索引,而不需要引入更多的开销。
哈希索引
这里我们通过哈希索引来分析一下上文提及的那个简易的键值数据库。最简单的索引策略是:保持一个内存的哈希映射,其中每一个键都映射到数据文件中的字节偏移量,通过偏移量可以找到该值的位置,如下图所示:
每当向文件追加一个新的键值对时,也会同时更新哈希映射以反映刚才写入的数据的偏移量(这既可以用于插入新的键值对,也可以用于更新现有的键值对)。在查找值时,使用哈希映射查找数据文件中的偏移量,查找该位置并读取该值。
那么我们如何避免最终耗尽磁盘空间呢?一个好的解决方案是,我们可以对这些文件执行压缩,如下图所示。压缩意味着在文件中扔掉重复的键,并且只保留每个键的最新更新。
合并和压缩可以由后台线程完成,并且在进行合并和压缩操作时,我们仍然可以使用旧的文件继续正常地服务读写请求。在合并过程完成后,我们将读取请求转换为使用新合并的文件,然后旧的文件可以简单地删除。
缺点:
(1)哈希索引严重依赖于内存,所以如果Key的数量庞大,需要匹配足够的内存空间。
(2)范围查询效率不高,每查找一个值都需要一次键值对映射。SSTable
由哈希索引我们可以引申出更加高效的索引结构:SSTable(Sorted String Table),SSTable要求键值对序列按照键来排序。乍一看,这个要求似乎破坏了顺序写的性能,但是它大大提高了维护数据以及索引结构的效率。不再需要保留所有键在内存中的索引,只需要保留部分键的索引,利用键在SSTable之中有序的特点。
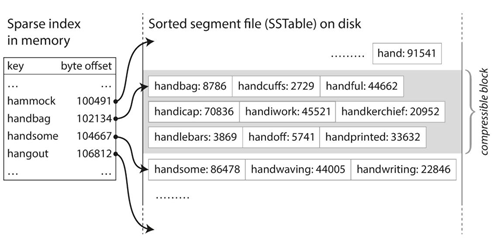
可以进行分组压缩,每个索引可以指向压缩块的起始点,来节省存储空间与减少I/O带宽的使用。
合并文件既简单又高效,使用简单的归并排序算法。

但是,如何让我们写入的键值对有序呢?这个问题在内存之中并不是什么难事,如红黑树或AVL树这些数据结构,可以按任何顺序插入键,并按排序顺序读取它们。所以我们在使用SSTable时,会维护一个MemTable的数据结构在内存之中,当MemTable达到阀值时,我们将MemTable作为一个新的SSTable序列化到磁盘之上。同时利用后台线程,不断压缩删除旧的SSTable,来维护一个可循环运行的存储系统。由于两次写入一次是在内存,一次磁盘写入是连续的(append日志),因此SSTable可以支持非常高的写入吞吐量。
许多数据库都是采用这样的思路来高效的处理数据,如Cassandra,HBase,LevelDB,Bitcask等。Lucene的全文搜索的使用Elasticsearch和Solr索引引擎,也采用了类似的方法来存储它的词典,当然,全文索引比键值索引复杂得多,但基于一个类似的想法:给定搜索查询中的一个词,查找提及该词的所有文档(Web页面、产品描述等)。这同样是一个键值结构实现的,其中键是一个词,而这个值是包含该词的所有文档的ID列表。
B树索引
这个索引结构大家应该非常熟悉了,在关系型数据库(如:MySQL,Oracle)与非关系型数据库(如:MongoDB)之中都大量应用。B树也把键值对进行了排序,它既允许高效的值查询也允许高效的范围查询。
哈希索引结构将数据分解成可变大小的段,通常是几个兆字节或更多的大小。而相比之下,树型索引将数据分成固定大小的块或页,通常为4KB大小(有时更大),每次读或写都基于页的大小。这种设计更接近于底层硬件,因为磁盘也是按固定大小的页来排列的。B树索引保证了:N个键总是有深度的O(log n)树,大多数数据都可以放入到一个三或四层的B树之中,(一个4页的四级树,分支系数为500,可以存储256TB)。下图展示了我们怎么样使用B树来查找“251”这个键:
基本写的操作是覆盖旧数据的数据页,重写不会改变页的位置;即,当页被覆盖时,对该页的所有引用都保持不变。这与SSTable这样的哈希索引结构形成鲜明对比,它有附加操作,但从不修改文件。
而B树索引的并发控制相对复杂,当多个线程会对树进行访问时,需要通过用锁存器(轻量级锁)保护树的数据结构来完成。(这里也可以用Copy on Write来快照隔离)而哈希索引结构的压缩,合并则不会影响查询,写入等操作。一些优缺点的探讨
(1)顺序写入通常比随机写入快得多,所以SSTable通常的写入性能是相对优秀的。
(2)由于SSTable压缩与清理的线程存在,通常会有较低的存储开销。但是压缩和清理磁盘的过程之中会与正常的请求服务产生磁盘竞争,导致吞吐量的下降。
(3)由于SSTable会存在同一个键值的多个副本,对于实现事务等对于一致性要求更高的场景,树型索引会表现的更加出色。
3.小结
树型索引在数据库架构是非常根深蒂固的,对于很多的工作负载提供始终如一的良好性能。而以SSTable为代表的哈希索引也越来越受欢迎。确定哪种类型的存储引擎更适合应用场景,并没有一个简单易用的规则,因此需要我们对业务逻辑有更深层次的理解。




